XiaoMi-AI文件搜索系统
World File Search System多分辨率

fa-gan:无伪像和相感的高保真gan vocoder
基于生成的对抗网络(GAN)的声音编码器在高质量和快速的推理速度方面已在语音合成中获得了极大的关注。但是,仍然存在许多明显的光谱伪像,导致综合语音的质量下降。在这项工作中,我们采用了一种基于Gan的新型Vocoder,专为少数文物和高保真效果而设计,称为Fagan。为了抑制高频组件中非理想的上取样层引起的混叠伪像,我们在发电机中引入了抗脱氧的双反卷积模块。为了减轻模糊的伪影并丰富了规格细节的重建,我们提出了一种新型的细粒度多分辨率真实和虚构的损失,以帮助对相信息进行建模。实验结果表明,FA-GAN的表现优于比较促进音频质量和减轻光谱伪像的方法,并且在应用于看不见的说话者场景时表现出卓越的性能。索引术语:语音综合,生成对抗网络,光谱伪像,频域

Instant-UV:网格的快速隐式纹理学习
建模3D对象有效地成为计算机视觉研究中的一个核心主题。传统代表涉及几何表示的网格,体素网格以存储SDF或占用率之类的值或用于外观建模的UV地图。由于其离散的性质,其表示功能受硬件限制的约束。采用多层感知器(MLP)允许形状[5,10,22,29,30],辐射场[24],纹理[17,20,28,47]等的高质量表示。Mildenhall等。[24]表明,高视觉保真度是使用频率编码来编码功能的关键。近年来,由于使用较小的MLP,大大提高了训练和推理速度,多分辨率参数编码变得越来越流行。尽管如此,由于其直观的编辑功能和有利的动画可能性,许多应用程序仍然依赖网格作为对象表示。不幸的是,直接在网格上进行了少数作品铲球外观建模。先前的工作将纹理直接作为3D空间中的连续函数回归[28],并使用频率编码[1,40]。内在的编码[17]也被引入以解锁更大的视觉细节。Mahajan等。[20]提出了一个有效的多解决顶点 -

使用粗到精视觉变换器进行仿射医学图像配准
仿射配准在全面的医学图像配准流程中不可或缺。然而,只有少数研究关注快速而鲁棒的仿射配准算法。这些研究中大多数利用卷积神经网络(CNN)来学习联合仿射和非参数配准,而对仿射子网络的独立性能探索较少。此外,现有的基于 CNN 的仿射配准方法要么关注局部错位,要么关注输入的全局方向和位置来预测仿射变换矩阵,这些方法对空间初始化很敏感,并且除了训练数据集之外表现出有限的通用性。在本文中,我们提出了一种快速而鲁棒的基于学习的算法,即粗到精视觉变换器(C2FViT),用于 3D 仿射医学图像配准。我们的方法自然地利用了卷积视觉变换器的全局连通性和局部性以及多分辨率策略来学习全局仿射配准。我们对 3D 脑图谱配准和模板匹配归一化方法进行了评估。综合结果表明,我们的方法在配准精度、稳健性和通用性方面优于现有的基于 CNN 的仿射配准方法,同时保留了基于学习的方法的运行时优势。源代码可在 https://github.com/cwmok/C2FViT 上找到。
DNA作为基于量子物理原理的完美量子计算机
DNA是一个复杂的多分辨率分子,其理论研究是一个挑战。其内在的24多尺寸性质需要化学和量子物理学才能了解结构和25个量子信息学,以将其操作解释为完美的量子计算机。在这里,我们提出了26个DNA的理论结果,可以更好地描述其结构及其在遗传信息的传输,编码和解码中的操作过程27。芳香性通过28个相关电子和孔对的振荡谐振量子状态来解释,这是由于量化的29个分子振动能充当吸引力的。相关对在单个带𝜋-分子轨道(𝜋 -MO)中的氮基碱基中形成30个超电流。Mo Wave 31函数(φ)被认为是N组成原子轨道的线性组合。腺嘌呤(a)和胸腺氨酸(T)或鸟嘌呤(G)和胞嘧啶(C)之间的32个中央氢键像理想的约瑟夫森连接一样。正确描述了两个34个超导体之间约瑟夫森效应的方法,以及氮基碱的凝结到35,获得了形成量子的两个纠缠量子状态。将36个复合系统的量子状态与经典信息相结合,RNA聚合酶传递了四个钟形37个状态之一。DNA是一台完美的量子计算机。38
![arxiv:2307.11870v1 [eess.iv] 2023年7月21日](/simg/f\f94ff6f2f840fee96869903480715affbeba16c4.webp)
arxiv:2307.11870v1 [eess.iv] 2023年7月21日
摘要。皮质表面重建在对围产期期间大脑快速发育进行建模方面起着基本作用。在这项工作中,我们提出了有条件的时间注意网络(COTAN),这是一个快速的端到端末端框架,用于新生儿皮质表面重建。Cotan可预测新生儿脑磁共振图像(MRI)的多分辨率固定速度场(SVF)。Cotan不是整合多个SVF,而是引入了注意机制,以通过在每个集成步骤中计算所有SVF的加权总和来学习有条件的时变速度场(CTVF)。每个SVF的重要性(通过学习的注意图估算)的重要性是基于新生儿的年龄,并且随着整合的时间步骤而变化。提出的CTVF定义了差异表面变形,该变形可有效地减少网格自我交流误差。仅需要0.21秒即可为每个脑半球变形至皮质白色垫料和毛皮表面的初始模板网格。cotan在开发的人类连接项目(DHCP)数据集上得到了验证,其中877 3D脑MR图像是从早产和术语出生的新生儿获取的。与最先进的基线相比,科坦仅以0.12±0.03mm的几何误差和0.07±0.03%的自我相交面部实现了优势。我们注意地图的可视化说明了科坦确实在没有中间监督的情况下自动学习了粗到细的表面变形。

使用胸肌抑制进行乳房分割...
梯度法自 Semmlow 等人 [ 9 ] 的早期工作以来就一直被使用,他们利用空间滤波器和 Sobel 边缘检测器获得乳房边界。类似地,M´endez 等人 [ 10 ] 使用两级直方图阈值获得乳房区域,然后将其向上划分为三个部分,使用梯度法跟踪边界。使用“准确”或“接近准确”标签对分割质量进行评估。他们成功地将他们的结果与 Yin 等人 [ 5 ] 提出的工作进行了比较。Karssemeijer 等人 [ 14 ] 提出的工作利用了多分辨率方案,在低分辨率下处理并推断结果。他们使用全局阈值技术获得一个初步区域,然后使用 3x3 Sobel 算子对其进行处理,并通过 Hough 变换估计胸肌位置。Abdel-Mottaleb 等人 [12] 提供了一种基于不同阈值的方案来查找乳房边缘。使用两幅图像的梯度及其并集,他们获得了可能的乳房轮廓。他们在 500 张测试图像中的 98% 中找到了边界。Morton 等人 [13] 提出的分割是另一种基于梯度的方法。通过初始阈值减去背景后,通过逐行梯度分析找到边缘。Zhou 等人 [11] 提出了最后一种方法的改进。

机载 LiDAR 和地面激光扫描仪 (TLS) ...
热带雨林是主要的陆地生态系统之一,通过碳封存对缓解全球气候变化发挥着重要作用。近年来,机载 LiDAR(光检测和测距)和地面激光扫描仪(TLS)在测量和提取森林生物物理参数和特性以及估算地上生物量(AGB)和碳储量方面的应用日益广泛。到目前为止,关于在热带雨林生态系统中使用地面激光扫描仪(TLS)的研究很少。因此,本研究的主要目的是评估地面激光扫描仪和机载 LiDAR 在热带雨林中估算地上生物量和碳储量的表现。通过从数字表面模型(DSM)中减去数字地形模型(DTM),从机载 LiDAR 数据生成冠层高度模型(CHM)。使用多分辨率分割对机载 LiDAR 的 CHM 进行了分割。人工勾画上部树冠,并采用 D“拟合优度测量”方法评估分割精度,精度为 68.6%。使用地面激光扫描仪 (TLS) 通过多个扫描位置收集点云数据。在配准点云数据(误差为 0.016m)后,在 779 棵树中,提取了 627 棵树(80.5%),遗漏了 152 棵树(19.5%)。树木参数、胸高 (DBH) 和 He
DNA 是基于量子物理原理的完美量子计算机
DNA 是一种复杂的多分辨率分子,其理论研究是一项挑战。其内在的多尺度性质需要化学和量子物理学来理解其结构,以及量子信息学来解释其作为完美量子计算机的运行。在这里,我们展示了 DNA 的理论结果,这些结果可以更好地描述其结构和在遗传信息的传输、编码和解码中的运行过程。芳香性可以通过关联电子和空穴对的振荡共振量子态来解释,这是由于量化的分子振动能量充当了引力。关联对在单带 𝜋 -分子轨道(𝜋 -MO)中的含氮碱基中形成超电流。MO 波函数(Φ)被假定为 n 个组成原子轨道的线性组合。腺嘌呤 (A) 和胸腺嘧啶 (T) 或鸟嘌呤 (G) 和胞嘧啶 (C) 之间的 32 中心氢键 33 的功能类似于理想的约瑟夫森结。正确描述了两个 34 超导体之间的约瑟夫森效应方法,以及含氮碱基的凝聚以获得形成量子比特的两个纠缠量子态。将复合系统的量子态与经典信息相结合,RNA 聚合酶传送四个贝尔 37 状态之一。DNA 是一台完美的量子计算机。38

使用分层 K 函数进行激光雷达数据分类 ...
使用分层 K 均值聚类的激光雷达数据分类 Nesrine Chehata a,b , Nicolas David b , Frédéric Bretar b a Institut EGID - Université Bordeaux 3 - Equipe GHYMAC Allée Daguin 33607 Pessac- Nesrine.Chehata@egid.u-bordeaux3.fr乙国家地理研究所 - MATIS Av. 实验室Pasteur 94165 St. Mandé cedex, France- nicolas.david@ign.fr, frederic.bretar@ign.fr Commission III, WG III/3 关键词:遥感、LIDAR、层次分类、DTM、多分辨率 摘要:本文涉及使用激光雷达点云过滤和分类来建模地形,更一般地用于场景分割。在本研究中,我们建议使用众所周知的 K 均值聚类算法来过滤和分割(点云)数据。K 均值聚类非常适合激光雷达数据处理,因为可以根据所需的类别使用不同的特征属性。当仅处理 3D 点云时,属性可能是几何或纹理的,但当联合使用光学图像和激光雷达数据时,属性也可能是光谱的。该算法基于固定的邻域大小,可以处理植被茂密的陡峭地貌、山区区域和呈现微地形的地形。我们的算法的新颖之处在于提供分层分割聚类来提取地面点。聚类分割的数量用于自动限定分类可靠性。这一点在以前的工作中很少被处理。此外景观< /div>
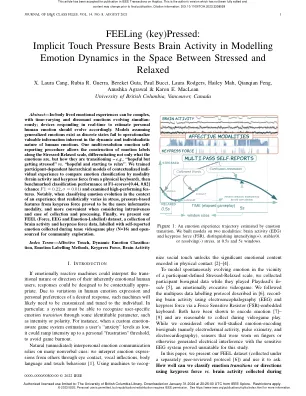
感觉(关键)按压:隐性触摸压力在压力和放松之间的情绪动态建模方面优于大脑活动
摘要 — 身体内的实际情绪体验可能很复杂,随着时间变化和不和谐情绪同时发展;实时响应以估计个人情绪的设备应该相应地发展。假设广义情绪存在于离散状态的模型无法将人类情绪的动态和个体性中固有的宝贵信息付诸实践。我们的多分辨率情绪自我报告程序允许根据压力-放松量表构建情绪标签,不仅可以区分情绪是什么,还可以区分情绪如何转变——例如,“充满希望但越来越紧张”与“充满希望并开始放松”。我们训练了基于被试的情境化个人经验的分层模型,以比较不同模态(大脑活动和物理键盘的按键力度)的情绪分类,然后在 F1 分数 = [0.44, 0.82](机会 F 1 = 0.22,σ = 0.01)下对分类性能进行基准测试,并检查高性能特征。值得注意的是,当在压力实际变化的体验背景下对情绪演变进行分类时,基于压力的按键力度特征被证明是更具信息量的模态,并且在考虑侵入性和易于收集和处理时更为方便。最后,我们展示了我们的 FEEL(力、脑电图和情绪标记)数据集,这是大脑活动和按键力度数据的集合,标记了在紧张的电子游戏过程中收集的自我报告情绪(N = 16),并开源供社区探索。