XiaoMi-AI文件搜索系统
World File Search System多模

多模式和多任务自动驾驶数据集
当前用于自动驾驶计算机视觉的深层神经网络(DNNS)通常在仅涉及单一类型的数据和urban场景的特定数据集上进行培训。因此,这些模型努力使新物体,噪音,夜间条件和各种情况,这对于安全至关重要的应用至关重要。尽管持续不断努力增强计算机视觉DNN的弹性,但进展一直缓慢,部分原因是缺乏具有多种模式的基准。我们介绍了一个名为Infraparis的新颖和多功能数据集,该数据集支持三种模式的多个任务:RGB,DEPTH和INDRARED。我们评估了各种最先进的基线技术,涵盖了语义分割,对象检测和深度估计的任务。更多可视化和
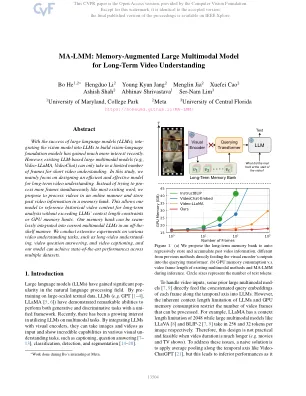
ma-lmm:长期视频理解的内存大型多模型
随着大型语言模型(LLM)的成功,将视觉模型融入了LLM,以建立视觉语言基础模型最近引起了人们的兴趣。但是,现有的基于LLM的大型多模式模型(例如,视频播放,视频聊天)只能摄入有限数量的框架以进行简短的视频理解。在这项研究中,我们主要专注于设计一个有效有效的模型,以进行长期视频理解。我们建议以在线方式处理视频并将过去的视频信息存储在存储库中,而不是像大多数现有作品一样尝试同时进行更多框架。这使我们的模型可以参考历史视频内容以进行长期分析,而不会超过LLM的上下文长度约束或GPU内存限制。我们的内存库可以以现成的方式被缝制到当前的多模式LLMS中。我们在各种视频理解任务上进行了广泛的实验,例如长期介绍,视频问题答案和视频字幕,我们的模型可以在多个数据集中实现最新的性能。

可控文本到图像合成,适用于多模态 MR 图像
近年来,生成模型取得了重大进展,尤其是在文本到图像合成领域。尽管取得了这些进展,但医学领域尚未充分利用大规模基础模型的功能来生成合成数据。本文介绍了一种文本条件磁共振 (MR) 成像生成框架,解决了与多模态考虑相关的复杂性。该框架包括一个预先训练的大型语言模型、一个基于扩散的提示条件图像生成架构和一个用于输入结构二进制掩码的附加去噪网络。实验结果表明,所提出的框架能够生成与医学语言文本提示一致的逼真、高分辨率和高保真的多模态 MR 图像。此外,该研究根据文本条件语句解释了生成结果的交叉注意力图。这项研究的贡献为未来文本条件医学图像生成的研究奠定了坚实的基础,并对加速医学成像研究的进步具有重要意义。

C9orf72 ALS/FTD二肽重复蛋白水平通过抑制PKA或增强蛋白质降解的小分子降低对扩散:全面的多模式对象级图像编辑器
基于扩散的生成模型在合成和操纵图像具有巨大的图像方面表现出了令人鼓舞的结果,其中文本到图像模型及其后续作品在学术界和行业中都具有很大的影响。编辑真实图像时,用户通常希望对不同元素具有直观而精确的控制(即对象)组成图像,并不断地操纵它们。我们可以根据图像中的单个观察的控制级别对现有的图像编辑方法进行分类。一条工作涉及使用文本提示来操纵图像[2,15,24,27]。由于很难与文本同时描述多个对象的形状和外观,因此在对象级别上对细粒度控制的能力有限。同时,迅速的工程使操纵任务乏味且耗时。另一项工作线使用低级调理信号,例如Hu等人。[18],Patashnik等。[34],Zeng等。[58],草图[50],图像[5,47,54]编辑图像。但是,其中大多数作品要么属于迅速的工程陷阱,要么无法独立操纵多个对象。与以前的作品不同,我们的目标是独立控制组成图像的多个对象的正确条件,即对象级编辑。我们表明,我们可以在对象级编辑框架下制定各种图像编辑任务,从而实现全面的编辑功能。

一种多模式的方法利用脑电图研究VR环境对心理工作负载的影响
抽象虚拟现实(VR)是一项允许用户体验模拟真实或虚构场景的多感觉和交互式环境的技术。仍然辩论了不同的VR沉浸式技术神学对心理工作量(MWL)的影响,即执行任务所需的资源数量;但是,从未利用脑电图在这种情况下的潜在作用。本文旨在调查在VR环境中对MWL进行认知任务的影响,这是通过使用多模式的方法进行的,其特征在于以不同程度的沉浸式来进行,这些方法通过生理EEG测量对MWL进行了良好评估的主观评估。提出了基于N-BACK测试的认知任务,以比较使用头部安装显示器(HMD)或桌面计算机展示Stim uli的特定裤子的性能和MWL。任务具有四个不同的复杂度(N¼1或2具有视觉或视觉和听觉刺激)。二十七名健康参与者都参加了这项研究,并在两种情况下都执行了任务。EEG数据和NASA任务负荷指数(NASA-TLX)分别用于评估客观和主观MWL的变化。 错误率(ER)和反应时间(RTS)也针对每个条件和任务水平进行了COL。 任务水平在两种情况下都对MWL产生了重大影响,增加了次级措施和降低性能。 EEG MWL指数显示出显着增加,特别是与休息相比。 不同程度的沉浸式均未显示个人的表现和MWL的显着差异,如主观评分所估计。EEG数据和NASA任务负荷指数(NASA-TLX)分别用于评估客观和主观MWL的变化。错误率(ER)和反应时间(RTS)也针对每个条件和任务水平进行了COL。任务水平在两种情况下都对MWL产生了重大影响,增加了次级措施和降低性能。EEG MWL指数显示出显着增加,特别是与休息相比。 不同程度的沉浸式均未显示个人的表现和MWL的显着差异,如主观评分所估计。EEG MWL指数显示出显着增加,特别是与休息相比。不同程度的沉浸式均未显示个人的表现和MWL的显着差异,如主观评分所估计。但是,在大多数情况下,HMD降低了EEG衍生的MWL,表明较低的认知负载。总而言之,HMD可能会减少某些任务的认知负担。如脑电图MWL指数所示,MWL的降低水平可能对基于VR的应用程序的设计和未来评估有影响。

一种多模式的方法利用脑电图研究VR环境对心理工作负载的影响
抽象虚拟现实(VR)是一项允许用户体验模拟真实或虚构场景的多感觉和交互式环境的技术。仍然辩论了不同的VR沉浸式技术神学对心理工作量(MWL)的影响,即执行任务所需的资源数量;但是,从未利用脑电图在这种情况下的潜在作用。本文旨在调查在VR环境中对MWL进行认知任务的影响,这是通过使用多模式的方法进行的,其特征在于以不同程度的沉浸式来进行,这些方法通过生理EEG测量对MWL进行了良好评估的主观评估。提出了基于N-BACK测试的认知任务,以比较使用头部安装显示器(HMD)或桌面计算机展示Stim uli的特定裤子的性能和MWL。任务具有四个不同的复杂度(N¼1或2具有视觉或视觉和听觉刺激)。二十七名健康参与者都参加了这项研究,并在两种情况下都执行了任务。EEG数据和NASA任务负荷指数(NASA-TLX)分别用于评估客观和主观MWL的变化。 错误率(ER)和反应时间(RTS)也针对每个条件和任务水平进行了COL。 任务水平在两种情况下都对MWL产生了重大影响,增加了次级措施和降低性能。 EEG MWL指数显示出显着增加,特别是与休息相比。 不同程度的沉浸式均未显示个人的表现和MWL的显着差异,如主观评分所估计。EEG数据和NASA任务负荷指数(NASA-TLX)分别用于评估客观和主观MWL的变化。错误率(ER)和反应时间(RTS)也针对每个条件和任务水平进行了COL。任务水平在两种情况下都对MWL产生了重大影响,增加了次级措施和降低性能。EEG MWL指数显示出显着增加,特别是与休息相比。 不同程度的沉浸式均未显示个人的表现和MWL的显着差异,如主观评分所估计。EEG MWL指数显示出显着增加,特别是与休息相比。不同程度的沉浸式均未显示个人的表现和MWL的显着差异,如主观评分所估计。但是,在大多数情况下,HMD降低了EEG衍生的MWL,表明较低的认知负载。总而言之,HMD可能会减少某些任务的认知负荷。如脑电图MWL指数所示,MWL的降低水平可能对基于VR的应用程序的设计和未来评估有影响。

L2词汇音调采集中的多模式提示
海洋生物膜是全球无处不在的表面相关微生物群落,由于其独特的结构和功能,引起了人们的关注。The aim of this study is to provide a comprehensive overview of the current scienti fi c understanding, with a speci fi c focus on naturally occurring bio fi lms that develop on diverse marine abiotic surfaces, including microplastics, sea fl oor sediments, subsurface particles, and submerged arti fi cial structures susceptible to biocorrosion and biofouling induced by marine bio fi LMS。本文介绍了有关海洋环境中这些表面相关微生物群落的多样性,结构,功能和动态的最新进展和发现,突出了它们的生态和生物地球化学维度,同时也是为了进一步研究海洋生物生物LMS的灵感。

零射击学习的多模式基准和改进的体系结构
在这项工作中,我们证明,由于现有评估协议和数据集中的不足,因此有必要重新审视并全面研究Mul-timodal零射击学习(MZSL)问题问题。具体来说,我们解决了MZSL方法面临的两个主要挑战。 (1)既定基线的情况通常是无与伦比的,而且有时甚至是有缺陷的,因为现有的评估数据集通常与培训数据集有一些重叠,因此违反了零照片范式; (2)大多数现有的方法都偏向可见的类,这在对可见和看不见的类别进行评估时会大大降低性能。为了应对这些挑战,我们首先引入了一个新的多模式数据集,用于零照片评估,称为MZSL-50,其中有4462个视频来自50个广泛多元化的类别,并且与培训数据没有重叠。此外,我们提出了一种新型的多模式零射击变压器(MZST)体系结构,该体系结构利用了吸引瓶颈进行多模式融合。我们的模型可以直接预测语义表示,并且在将偏见降低到可见的类别方面表现出色。我们进行了广泛的消融研究,并在三个基准数据集和我们的新型MZSL-50数据集上实现最先进的结果。具体来说,我们提高了传统的MZSL绩效2。1%,9。81%和8。 vgg-sound,UCF-101和ActivityNet的68%。 最后,我们希望引入MZSL-50数据集将促进对社区中多模式零射击的深入研究。 181%和8。vgg-sound,UCF-101和ActivityNet的68%。最后,我们希望引入MZSL-50数据集将促进对社区中多模式零射击的深入研究。1

多模式面部图像生成的扩散驱动的GAN倒置
摘要我们提出了一种新的多模式面部图像生成方法,该方法将文本提示和视觉输入(例如语义掩码或涂鸦图)转换为照片真实的面部图像。为此,我们通过使用DM中的多模式特征在预训练的GAN的潜在空间中使用多模式特征来结合一般的对抗网络(GAN)和扩散模型(DMS)的优势。我们提供了一个简单的映射和一个样式调制网络,可将两个模型链接起来,并在特征地图和注意力图中将有意义的表示形式转换为潜在代码。使用gan inversion,估计的潜在代码可用于生成2D或3D感知的面部图像。我们进一步提出了一种多步训练策略,该策略将文本和结构代表反映到生成的图像中。我们提出的网络生成了现实的2D,多视图和风格化的面部图像,这些图像与输入很好。我们通过使用预训练的2D和3D GAN来验证我们的方法,我们的结果表现优于现有方法。我们的项目页面可在https://github.com/1211SH/diffusion-driven_gan-inversion/。

解码脑电图活动以实现多模态自然语言处理
直到最近,研究人员主要对阅读中的人类行为数据感兴趣,以了解人类认知。然而,这些人类语言处理信号也可以用于基于机器学习的自然语言处理任务。目前,将脑电图大脑活动用于此目的的研究还很大程度上尚未得到探索。在本文中,我们首次进行了大规模研究,系统地分析了脑电图大脑活动数据在改进自然语言处理任务方面的潜力,特别关注了信号的哪些特征最有益。我们提出了一种多模态机器学习架构,它可以从文本输入和脑电图特征中联合学习。我们发现将脑电图信号过滤到频带中比使用宽带信号更有益。此外,对于一系列词嵌入类型,脑电图数据可以改进二元和三元情绪分类,并且优于多个基线。对于关系检测等更复杂的任务,在我们的实验中,只有情境化的 BERT 嵌入优于基线,这提出了进一步研究的需要。最后,当训练数据有限时,EEG 数据显示出特别有前景。