
机构名称:
¥ 1.0
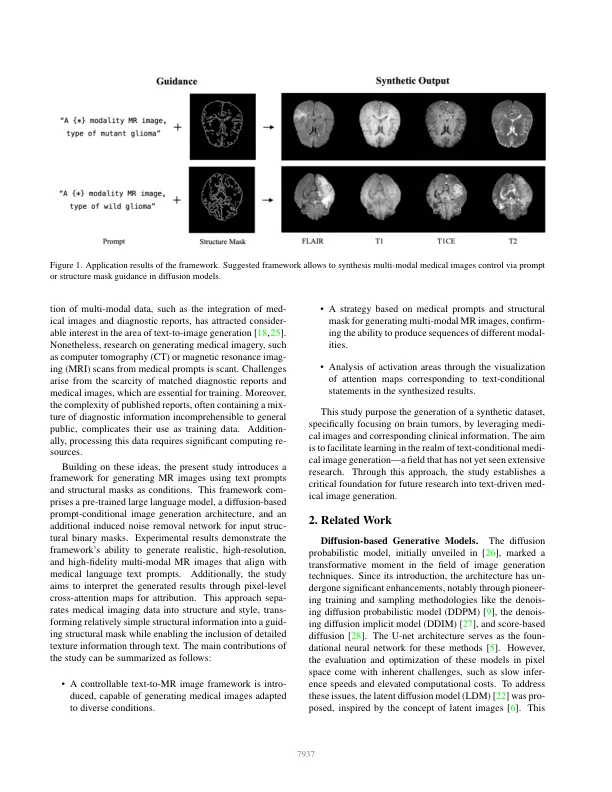
近年来,生成模型取得了重大进展,尤其是在文本到图像合成领域。尽管取得了这些进展,但医学领域尚未充分利用大规模基础模型的功能来生成合成数据。本文介绍了一种文本条件磁共振 (MR) 成像生成框架,解决了与多模态考虑相关的复杂性。该框架包括一个预先训练的大型语言模型、一个基于扩散的提示条件图像生成架构和一个用于输入结构二进制掩码的附加去噪网络。实验结果表明,所提出的框架能够生成与医学语言文本提示一致的逼真、高分辨率和高保真的多模态 MR 图像。此外,该研究根据文本条件语句解释了生成结果的交叉注意力图。这项研究的贡献为未来文本条件医学图像生成的研究奠定了坚实的基础,并对加速医学成像研究的进步具有重要意义。
可控文本到图像合成,适用于多模态 MR 图像
主要关键词




相关文件推荐





























