XiaoMi-AI文件搜索系统
World File Search System字符

数据表示和计算机结构
ASCII 是一种允许计算机相互理解和通信的标准。在 ASCII 中,每个字符(字母、数字和符号)都有其独特的代码。例如,字母“A”用二进制数 01000001(65)表示,而“a”用二进制数 1100001(97)表示。该系统帮助计算机了解在屏幕上显示哪些字符或如何将它们存储在内存中。因此,当您在键盘上键入字母时,计算机会将其转换为相应的 ASCII 代码以理解您在说什么。ASCII 使计算机能够相互通信,也使我们通过键入的文本与计算机轻松交互。另一种编码方案是 Unicode,这是一种较新的标准,通过为每个字符分配 16 位来克服 ASCII 可以表示的字符数的限制。扩展 ASCII 是 Unicode 的子集(包含其前 256 个字符)。 Unicode 的目标是为每个字符提供一个唯一的编号,无论平台、程序或语言如何,从而为文本表示创建一个全球标准。

使用黎曼概率的贝叶斯积累的端到端 P300 BCI
摘要 — 在脑机接口 (BCI) 中,大多数基于事件相关电位 (ERP) 的方法都侧重于 P300 的检测,旨在对拼写任务进行单次试验分类。虽然这是一个重要的目标,但现有的 P300 BCI 仍然需要多次重复才能达到正确的分类准确率。P300 BCI 中的信号处理和机器学习进步主要围绕 P300 检测部分,而字符分类不在范围之内。为了在保持良好字符分类的同时减少重复次数,解决完整的分类问题至关重要。我们引入了一个端到端流程,从特征提取开始,由使用概率黎曼 MDM 的 ERP 级分类组成,该分类使用跨试验的贝叶斯置信度积累提供字符级分类。现有方法仅在字符闪现时增加其置信度,而我们新的管道,称为黎曼概率贝叶斯累积 (ASAP),在每次闪现后更新每个字符的置信度。我们提供了此贝叶斯方法的正确推导和理论重新表述,以便无缝处理从信号到 BCI 字符的信息。我们证明我们的方法在公共 P300 数据集上的表现明显优于标准方法。

使用黎曼概率的贝叶斯积累的端到端 P300 BCI
摘要 — 在脑机接口 (BCI) 中,大多数基于事件相关电位 (ERP) 的方法都侧重于 P300 的检测,旨在对拼写任务进行单次试验分类。虽然这是一个重要的目标,但现有的 P300 BCI 仍然需要多次重复才能达到正确的分类准确率。P300 BCI 中的信号处理和机器学习进步主要围绕 P300 检测部分,而字符分类不在范围之内。为了在保持良好字符分类的同时减少重复次数,解决完整的分类问题至关重要。我们引入了一个端到端流程,从特征提取开始,由使用概率黎曼 MDM 的 ERP 级分类组成,该分类使用跨试验的贝叶斯置信度积累提供字符级分类。现有方法仅在字符闪现时增加其置信度,而我们新的管道,称为黎曼概率贝叶斯累积 (ASAP),在每次闪现后更新每个字符的置信度。我们提供了此贝叶斯方法的正确推导和理论重新表述,以便无缝处理从信号到 BCI 字符的信息。我们证明我们的方法在公共 P300 数据集上的表现明显优于标准方法。

使用人工智能的假冒产品监控系统
首先,像下图这样构建图像背景,然后构建文本显著性,即在视觉处理背景下的图像的独特特征。字符识别意味着允许计算机识别书面或印刷字符(例如数字或字母)并将其转换为计算机可以使用的形式的过程。字符识别器 - ABBYY 我们首先使用领先的商业 OCR 引擎 ABBYY 对文本显著性执行字符识别。ABBYY 接收图像作为输入并输出该图像中识别出的字符。然后通过文本提示编码(即二元语法和三元语法)完成字符检测,最后通过视觉提示编码完成视觉检测这两者使用对象粒度分类进行分类,最后的结果是徽标检索。

使用人工智能神经网络和图像处理的手写识别
由于数字技术在各个领域的使用增加以及几乎全天的日常活动以存储和传递信息,手写角色识别已成为研究的流行主题。手写仍然相关,但是人们仍然希望将笔迹副本转换为可以通过电子方式传达和存储的电子副本。手写字符识别是指计算机从手写来源(例如触摸屏,照片,纸质文档和其他来源)检测和解释可理解的手写输入的能力。手写字符仍然很复杂,因为不同的个人具有不同的手写样式。本文旨在报告开发手写字符识别系统,该系统将用于阅读学生和讲座笔记。该发展基于人工神经网络,该网络是人工智能研究领域。不同的技术和方法用于开发手写字符识别系统。但是,很少有人专注于神经网络。与其他计算技术相比,使用神经网络识别手写字符更有效,更健壮。本文还概述了手写字符识别系统以及系统开发的测试和结果的方法,设计和架构。目的是证明神经网络对手写性格识别的有效性。

批准附录 t - 国防后勤局
CHAR -- 固定长度的字母数字字符数据文本字符串 VARCHAR -- 可变长度的字母数字字符数据文本字符串 SMALLINT(eger) -- 仅数字值。范围 -32768 到 32767 INTEGER -- 仅数字值。范围 -2,147,383,648 到 2,147,383,647 DECIMAL -- 需要十进制值的数字数据 DATE -- 取决于数据记录号 (DRN) 的 4 到 17 位数字字段 LENGTH -- 字段中允许的最大字符数 TIMESTAMP -- 这是执行维护时的日期和时间(时间戳)。日期和时间格式为 yyyy-mm-dd-hh.mm.ss.dddd
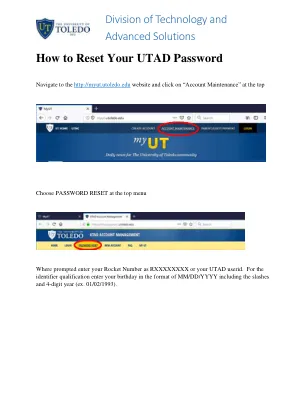
如何重置您的 UTAD 密码
不允许使用以下特殊字符:& # @ < 空白或空格 不能全是数字 不能与前 10 个密码相同 不能包含 3 个或更多相同字符的重复 区分大小写,即“TOM”不等于“tom” 不能包含您的用户名或您的名字、姓氏或中间名


NPDES 施工活动雨水排放通用许可证
填写表格 仅在相应区域使用大写字母键入或打印。请将每个字符放在标记之间。如有必要,请缩写以保持在每项允许的字符数之内。单词之间仅使用一个空格,但不要使用标点符号,除非它们需要澄清您的回答。如果您对此表格有任何疑问,请参阅 www.epa.gov/npdes/stormwater/cgp 或致电雨水通知处理中心 (866) 352-7755。请提交带有墨水签名的原件,请勿发送复印的签名。 仅在相应区域使用大写字母键入或打印。请将每个字符放在标记之间。如有必要,请缩写以保持在每项允许的字符数之内。单词之间仅使用一个空格,但不要使用标点符号,除非它们需要澄清您的回答。如果您对此表格有任何疑问,请参阅 www.epa.gov/npdes/stormwater/cgp 或致电 (866) 352-7755 联系暴雨通知处理中心。请提交带有墨水签名的原件。请勿发送签名的复印件。仅在相应区域键入或打印大写字母。请将每个字符放在标记之间。如有必要,请缩写以保持在每项允许的字符数之内。单词之间仅使用一个空格,但不要使用标点符号,除非需要它们来澄清您的回答。如果您对此表格有任何疑问,请参阅 www.epa.gov/npdes/stormwater/cgp 或致电 (866) 352-7755 联系暴雨通知处理中心。请提交带有墨水签名的原件。请勿发送签名的复印件。

命名和分类,
c lassification在英语中有两个含义:通过共享字符和这些类的排列将事物分为类的过程。识别是观察字符并从而对事物进行分类的过程。生物学分类是生物的布置。分类的能力对于所有动物来说都是共同的,为了生存动物,必须将其他生物分为至少三个类别:被避免食用的生物以及与之交往的人,尤其是自己班级的成员。对于科学家来说,分类被正式化为嵌套或分层的假设集:字符,群体(分类单元)和群体之间的关系的假设。观察到了器官的单个标本,并注意到了特征。因此,例如,我们可能会观察到有些人是黑色的,有些是黄色或白色的,并且像Linnaeus一样得出结论,有不同的人类(Homo Sapiens)。这是一个假设,即肤色是有用的特征。对该特征假设的进一步测试表明,人类的肤色不会界定天然群体。因此,我们拒绝肤色作为人类的角色以及该角色定义的那些群体。颜色对于对许多其他组进行分类是一个非常有用的字符。然后是一组的假设。组