XiaoMi-AI文件搜索系统
World File Search System开源

tidybot ++:机器人学习的开源自动移动操纵器
摘要:利用最近在模仿学习中进行操作的前进的承诺将需要收集大量的人类引导示范。本文提出了一种开源设计,用于廉价,健壮且灵活的移动操纵器,该设计可以支持任意武器,从而实现了各种各样的现实世界家庭移动操纵任务。至关重要的是,我们的设计使用动力施法者使移动基础能够完全自动,能够同时独立地控制所有平面自由度。此功能使基础更具机动性,并简化了许多移动操作任务,从而消除了在非实体基础中产生复杂且耗时的动作的运动限制。我们为机器人配备了直观的手机遥控接口,以实现简单的数据获取以进行模仿学习。在我们的实验中,我们使用此界面来收集数据,并表明所产生的学习政策可以成功执行各种常见的家庭移动操纵任务。

野外自动空中操纵的开源软机器人平台
摘要:空中操纵将飞行平台的多功能性和速度与移动操作的功能能力相结合,由于需要精确的定位和控制,这引起了挑战。在传统上,研究人员依靠卸下感知系统,这些系统涉及昂贵且不切实际的室内环境。在这项工作中,我们引入了一个新颖的平台,用于自主空中操纵,该平台可易于利用板载感知系统。我们的平台可以在各种室内和室外环境中进行空中操纵,而无需依赖外部感知系统。我们的实验结果表明了平台在不同环境中自主掌握各种对象的能力。这一进步可以通过消除昂贵的跟踪解决方案的需求来显着提高空中操纵应用的可扩展性和实用性。为了加速未来的研究,我们开源3我们的ROS 2软件堆栈和自定义硬件设计,使我们的贡献可用于更广泛的研究社区。

Riotee:无电池互联网的开源硬件和软件平台
快速增长的物联网(IoT)可以避免通过使用无可持续的电池设备来代替数万亿电池的高成本和环境负担,这些设备数十年来无需维护。要开发无电池的物联网系统,研究人员和制造商需要一个通用,价格合理且易于使用的通用平台。但是,有限的可用性和缺乏支持阻止了以前无电池平台的广泛采用。我们介绍了Riotee,这是一个开源和市售的无电池平台,其中包括多个板,广泛的软件和全面的文档。我们通过机器学习应用程序展示了Riotee的功能,并介绍了涉及学生和客户的用户研究结果,他们对其有用性和可用性评为高度评价。
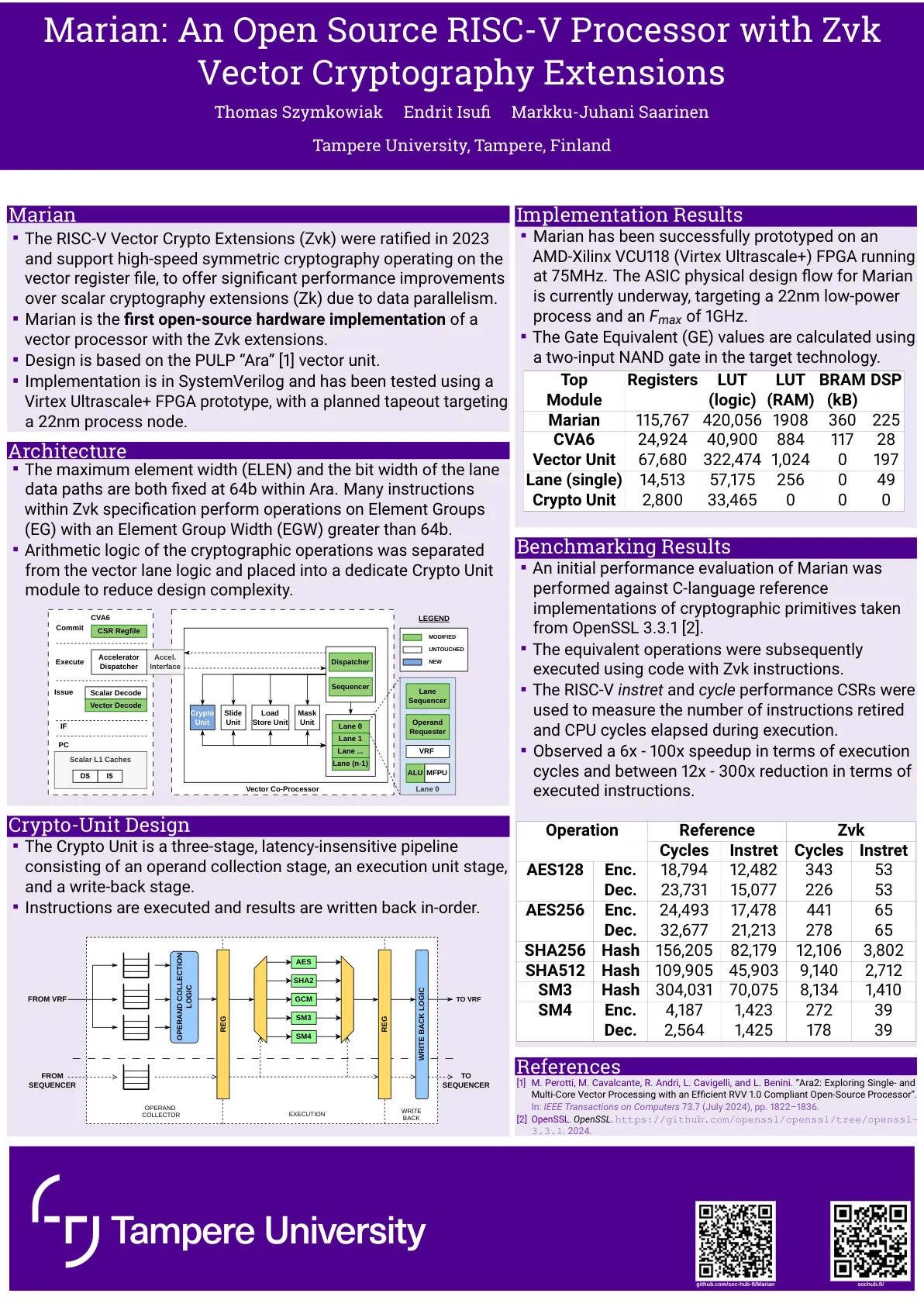
玛丽安:带有ZVK矢量加密扩展的开源RISC-V处理器
对玛丽安的初步性能评估是针对从OpenSSL 3.3.1 [2]获得的密码原始图的C语言参考实现进行的。随后使用带有ZVK指令的代码执行等效操作。使用RISC-V Intert和循环性能CSR用于测量在执行过程中退休的指令数量和CPU周期的数量。在执行周期中观察到6倍-100倍加速度,而执行指令则介于12倍-300倍之间。

生成的AI和分布式工作 - 开源软件的证据
- 示例:免费开源软件(OSS)贡献者漏斗 - ≈50%项目依赖于单个维护者(Avelino等人。2017) - 5%的开发人员的价值的96%(Hoffmann等人2024)


冷冻粒子拾取机学习竞赛的开源工具
图4:超级金属和金属3D的疯狂分布跨各种概率截止。内核密度估计用于说明分布,突出显示中位数(白色圆圈),四分位数(黑匣子)和数据扩展(晶须量最高为1.5倍。


玛丽安:带有ZVK矢量加密扩展的开源RISC-V处理器
RISC-V矢量加密扩展(ZVK)在2023年批准并集成到2024年的ISA主要手册中。这些表面支持在矢量寄存器文件上运行的高速对称加密(AES,SHA2,SM3,SM4),并且由于数据并行性而对标量密码扩展(ZK)提供了显着的性能改进。作为批准的扩展名,ZVK由编译器工具链提供支持,并且已经集成到流行的加密中间件(例如OpenSSL)中。我们报告了玛丽安(Marian),这是带有ZVK扩展程序的向量处理器的第一个开源硬件实现。设计基于纸浆“ ARA”矢量单元,该矢量单位本身就是流行的CVA6处理器的扩展。该实现位于SystemVerilog中,并已使用Virtex Ultrascale+ FPGA原型制作进行了测试,其计划的磁带针对22nm的过程节点。我们对矢量密码学对处理器的架构要求进行分析,以及对我们实施的绩效和面积的初步估计。

OpenAirInterface 10周年研讨会 - FR2 Sidelink的开源6G测试床以及联合通信和感应研究。
PSBCH-物理Sidelink广播频道(同步)。s-pss/s-SSS- Sidelink初级/二级同步信号(同步参考)。PSCCH-物理侧链接控制通道(控制)。PSSCH-物理侧链接共享通道(数据)。PSFCH-物理侧链接反馈通道(HARQ)。