XiaoMi-AI文件搜索系统
World File Search System数据量

道路相关数据及其使用方法呼吁...
大数据:大数据是指数据量太大、太复杂、移动速度太快或结构太弱,例如无法使用手动和传统数据处理方法进行评估。大数据通常来自不同来源,格式也不同。大数据通常用作数字技术的统称,从技术角度来说,它代表着数字通信和处理的新时代,从社会角度来说,它代表着社会变革。大数据还描述了用于收集和评估这些数据量的复杂技术,包括人工智能和物联网。对于这个项目,大数据还包括社交网络数据。

论预训练数据多样性与微调鲁棒性之间的联系
预训练已在深度学习中被广泛采用,以提高模型性能,特别是当目标任务的训练数据有限时。在我们的工作中,我们试图了解这种训练策略对下游模型泛化特性的影响。更具体地说,我们提出以下问题:预训练分布的属性如何影响微调模型的鲁棒性?我们探索的属性包括预训练分布的标签空间、标签语义、图像多样性、数据域和数据量。我们发现影响下游有效鲁棒性的主要因素 [44] 是数据量,而其他因素的重要性有限。例如,将 ImageNet 预训练类别的数量减少 4 倍,同时将每个类别的图像数量增加 4 倍(即保持总数据量固定)不会影响微调模型的鲁棒性。我们展示了从各种自然和合成数据源中提取的预训练分布的发现,主要使用 iWildCam-WILDS 分布转变作为稳健性测试。
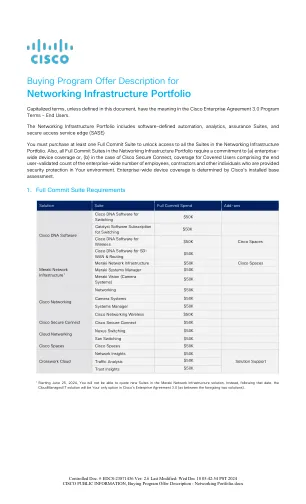
购买计划-报价-描述-网络组合.pdf
“受保用户”是指通过您部署的 Cisco Secure Connect 覆盖(或保护)的联网员工、分包商或任何其他授权个人。Cisco Secure Connect 每位受保用户每月传输的数据量最高为 20 GB。这意味着,您每月传输的数据总量除以受保用户数量必须等于或小于 20 GB。如果您超出每位受保用户分配的数据量或导致异常激增影响产品运行,Cisco 保留向您收取额外费用的权利。

分布式云架构中大数据处理的可扩展和容错算法
数字数据的快速增长是当今时代的特征,预计到 2025 年,全球数据量将超过 175 ZB。这种巨大的数据融合对处理系统提出了巨大的要求,因为传统方法难以跟上数据量、速度和种类的不断增长。云计算已成为一种重要的推动因素,为管理和分析这些无尽的数据集提供了灵活的基础。尽管云平台具有这些功能,但大数据处理的效率通常取决于处理大规模操作所需的计算的优化。由于数据处理速度通常落后于数据生成速度,因此迫切需要升级处理解决方案。


数字传输参考模型 - 思科
为了应对日益加剧的拥堵压力、气候可持续性以及后疫情时代社会不断变化的需求,交通运输机构正在对物理和技术基础设施进行大量投资。这些基础设施投资正在推动产生的数据量以及优化性能和满足客户需求所需的数据量呈指数级增长。为了应对这一挑战,交通运输机构正致力于改造其许多技术资产和企业系统的核心,这些系统也需要高昂的投资成本和实施时间框架——对于管理流程和数据的核心系统,这可以看作是一种“由内而外”的方法,与生成和呈现数据的交通网络中的技术形成鲜明对比。


具有统计和强度波动的非对称双场量子密钥分配
摘要 双场量子密钥分发(TF-QKD)是一种颠覆性创新,它能够克服无需可信中继的 QKD 速率-距离限制。自第一个 TF-QKD 协议提出以来,人们在理论和实验上不断取得突破,以增强其能力。然而,仍有一些实际问题有待解决。在本文中,我们研究了具有不稳定光源和有限数据量的非对称 TF-QKD 协议的性能。使用 Azuma 不等式估计参数的统计波动。通过数值模拟,我们比较了具有不同数据量和不同强度波动幅度的非对称 TF-QKD 协议的密钥速率。我们的结果表明,统计和强度波动都对非对称 TF-QKD 的性能有显著的影响。


美国宇航局的分布式活动档案中心管理
50 多年来,NASA 一直将卫星和其他科学仪器发射到太空,以观察地球并收集有关气候、天气和地震、干旱、洪水和野火等自然现象的数据。NASA 地球科学任务生成的数据存储在 12 个分布式活动存档中心 (DAAC) 中。DAAC 位于 NASA 中心、大学和其他联邦机构,负责处理、存档和分发数据。在未来 6 年内,当多个高数据量任务(例如 NASA-印度空间研究组织合成孔径雷达 (NISAR) 和地表水和海洋地形 (SWOT))上线时,NASA 需要存档的地球观测数据量预计将从 32 PB 增加到 247 PB(1 PB 的存储量相当于 150 万张 CD-ROM 光盘)。