XiaoMi-AI文件搜索系统
World File Search System检测技术

基于多维结构特征的硬件木马检测技术
具体来说, Oya 等人 [ 3 ] 总结了 9 种木马特征并对 每种特征赋予特定的分值,通过分值的高低来确定 是否存在硬件木马。但该文并未阐述这些特征的性 质及与硬件木马触发机制的联系。 Yao 等人 [ 4 ] 基于 数据流图提出 4 种硬件木马特征,利用硬件木马特 征匹配算法来检测硬件木马,并形成了检测工具 FASTrust 。然而基于数据流图的木马特征构建方 法是从寄存器层面进行的,大量的组合逻辑被忽略, 误识别率较高。 Hasegawa 等人 [ 5 ] 提出了 LGFi, FFi, FFo, PI, PO 等 5 种硬件木马特征,并利用支持向量 机算法来训练并识别木马节点,然而在训练集中, 硬件木马特征集较少,训练集分布并不平衡,即便 是采用动态加权的支持向量机依然存在较大的误识 别情况。 Chen 等人 [ 6 ] 计算待测电路中两级 AONN 门 的分数,认为分数较高的门是硬件木马。该方法对 单触发型硬件木马有效,然而对于多触发条件的硬 件木马无能为力,且未考虑有效载荷电路及其功能。
检测技术
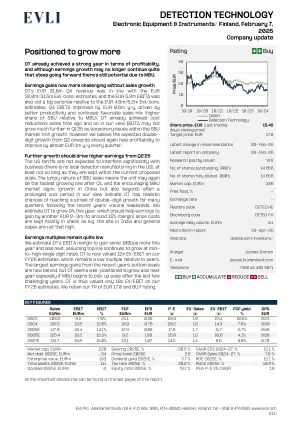
在盈利能力方面,已经取得了更多的DT,但在盈利能力方面已经实现了强劲的一年,尽管收益增长可能不再继续如此陡峭,但由于MBU,仍然有潜力。收益的收益现在更具挑战性,没有销售增长DT的3160万欧元收入与32000万欧元/3150万欧元的EVLI/CONS一致。估计,相对于480万欧元/520万欧元的EVLI/CONS,EBITA的520万欧比塔也不是一个大惊喜。估计。第四季度EBITA提高了060万欧元/Y/y,这是由提高生产率和持续有利的销售组合(相对于MBU的较高份额)驱动的。dt已经在一段时间前已经实现了成本降低,因此在我们看来,EBITA在第1季度的25年代可能不会进一步增长,因为SBU市场限制的临时问题在SBU市场限制增长范围内,但是我们相信,从第2季度开始,预期的双位数字增长应再次有助于盈利能力,以提高每季度几乎100万欧元。进一步的增长应从25 Q5 Q2'25提高收益,预计美国关税不会显着干扰业务(在美国没有本地探测器制造),至少只有将其保留在当前拟议的规模之内。SBU销售的块状性质意味着该单元可能是第1季度后增长最快的一个,而在我们看来,在漫长的凉爽时期长期表明,在近年来,在近年来,MBU市场迹象(在中国的增长和超越)之后,DT持续了很多季度的增长,这表明DT具有现实的机会。我们估计DT今年增长了9%,这应该有助于收益增加2-3m欧元(左右15%),因为费用主要由例如印度和一般资本支出的地点并不高。的收益倍数仍然很低,我们估计DT的EBITA利润率今年增加了约100bps,并且下一年,假设顶级线继续以中高的单位数率增长。dt现在在我们的25 fy'25估计值上重视12x eV/ebit,相对于同行而言,该估计值仍然是低倍数。近年来最大的收入收益率最大的收益现在已经落后了,但是DT似乎很明年,尤其是如果MBU在过去几年中挑战时开始加快步伐。dt仅重视10x eV/ebit。我们保留了17.0欧元的TP并购买评级。

混凝土损伤检测技术...
15.补充说明报告已上传至 http://www.chpp.egr.msu.edu/ 16.摘要 无损检测技术的新技术进步为更好地利用超声波辅助混凝土损伤检测应用创造了机会。本研究利用超声波阵列装置进行无损损伤检测。本研究使用的超声波剪切速度阵列系统特别有利,因为它可以对几乎任何混凝土样品(从柱和梁到混凝土路面)进行测量,并且可以通过一次测量提供大量数据。为几种重要的混凝土应用开发了新的信号解释方法。考虑了全尺寸钢筋混凝土柱中荷载引起的损伤检测,以及由冻融或碱硅反应降解引起的混凝土路面标准生命周期损伤。此外,还考虑了连续钢筋混凝土路面的开裂问题。这些研究最终促成了成功且高效的定量损伤检测方法的开发。


危险材料检测技术(WTCCXCSM ...
Default type of course examination report: Graded pass Language: English Course homepage: http://www.wtc.wat.edu.pl Short description: The objectives of the course is: to provide an introduction into the field of hazardous materials, to introduce the problems related to air monitoring, to familiarize students with various sampling and detection technologies for hazardous materials, to teach how to take a sample containing trace amounts of hazardous substances并分析它,以教导如何准备分析报告。描述:讲座1。危险材料的特性及其分析的细节 / 2小时2。< / div>进行抽样和准备,以检测和鉴定物质 / 4小时3。< / div>含有危险物质的样品的实验室分析 / 4小时4。< / div>使用现场仪器 / 4小时检测和确定物质< / div>

边缘检测技术与...的比较研究
MRI 之所以能利用单个原子核的磁性,是因为图像处理现在是医学等许多生活方面的重要阶段。图像处理使用数学运算符来分析和处理数字图片。边缘检测是此过程中的关键阶段。这两组特征都将图片的数据描述为图像处理的输入。当图片出现突然的不连续性时,边缘检测就是识别和检测分隔它们的线的行为(L. Han, Y. 2020)。像素强度不连续性描述了图片中项目之间的边界。边缘检测几乎普遍使用一种运算符(二维滤波器),该运算符对图片中的大梯度敏感,同时在均匀区域返回零值。边缘检测运算符的数量惊人,每个运算符都针对检测某些类型的边缘进行了优化。边缘方向、噪声环境和边缘结构都是选择边缘检测运算符时要考虑的因素。灰度值的不连续性使边缘具有独特的外观。这意味着边缘表示一个项目结束而另一个项目开始的点。许多因素都会影响图像边缘的外观,包括:数字图像的亮度在某些点突然波动,并且对象的几何和光学特征以及边缘识别的数学算法用于识别这些点(或换句话说,具有不连续性)。近年来,研究人员对此产生了关注(R. Bausys,2020 年;M. Ravi Kumar 等人,2020 年;P. Kanchanatripop 和 D. Zhang,2020 年;SKT Hwa,2020 年;S. Bourouis、R. Alroobaea,2020 年;ZH Naji,2020 年;AK Bharodiya 和 AM Gonsai,2019 年;J. Mehena,2019 年)。

检测技术和系统指南……
指南编辑团队以真诚和最大的能力准备了这份报告,目的是传播结果。本书中描述的技术的描述和测试结果是从系统开发人员,制造商和其他开放文献来源获得的。指南编辑团队没有机会验证系统开发人员或制造商提供的测试结果或性能主张。本出版物中表达的观点否则是GICHD的观点,不一定代表德国政府的观点,或指南编辑团队和他们所工作的组织的观点。本出版物中所采用的名称和材料的介绍并不意味着对德国政府或日内瓦国际国际人道主义中心的任何意见的表达,涉及任何国家,领土或地区,当局或其当局或其当局或武装团体的法律地位,或涉及其前沿或边界的划定。


小型无人机的物体检测技术
摘要。障碍物检测和避障对于无人机尤其是轻型微型飞行器来说是必需的,并且由于其有效载荷受限,因此车辆上只能安装有限的传感器,因此这是一个具有挑战性的问题。通常,系统中包含的传感器要么是基于视觉的(单目或立体摄像机),要么是基于激光的。但是,每种传感器都有自己的优点和缺点,因此我们构建了基于多传感器(单目传感器和激光雷达)集成的障碍物检测和避障系统。最重要的是,我们还将 SURF 算法与 Harris 角点检测器相结合,以确定障碍物的大致大小。在进行的初步实验中,我们成功地检测并确定了具有 3 种不同障碍物的障碍物的大小。实际障碍物和我们的算法之间的长度差异被认为是可以接受的,约为 -0.4 到 3.6。

ssc-463 海洋复合材料检测技术...
1. 介绍................................................................................................................................1 1.1 执行摘要....................................................................................................................1 1.2 背景....................................................................................................................2 1.3 致谢....................................................................................................................3 2. 缺陷.........................................................................................................................................4 2.1 胶接接头失效.......................................................................................................4 2.2 气泡.......................................................................................................................6 2.3 起泡.......................................................................................................................7 2.4 芯材压溃.................................................................................................................8 2.5 芯材剪切失效....................................................................................................10 2.6 开裂....................................................................................................................10 2.7 分层....................................................................................