XiaoMi-AI文件搜索系统
World File Search System深度


基于深度学习方法预测抗癌药物敏感性
抗癌药物敏感性的预测是个性化医学的主要挑战。在本文中,CCLE被用作抗癌药物易感性研究的数据集,并选择了基因的数据数据和不同细胞系上的药物敏感性数据。同时,我们签署了一种称为PCA变压器(PCAT)的混合深度学习和机器学习方法,以预测抗癌药物的敏感性。首先,构建了PCA模型以在不同细胞系上提取基因表达数据中的重要变量,因此将约50,000的基因维度降低到500。然后,基于降低性降低基因表达值建立了神经网络变压器模型,以预测药物敏感性,通过均方根误差(RMSE)评估我们的模型的功能,并使用最佳的潜在变量来评估模型估计值。为了验证PCA变压器的性能,本文将变压器模型与前字典模型随机森林(RF)和支持向量回归(SVR)进行了比较。特定组合Include:PCA变压器,PCA + SVR,PCA + RF。最后,将结果与先前的研究方法(ISIR)的结果进行了比较和优化。最终预测结果表明,对于CCLE中的24种药物,该方法预测的平均RMSE为0.7564、6种药物的RMSE小于0.5(L-685458,PF2341066等)。)和18种药物小于1。预测方法的平均RMSE为0.8284(PCA + SVR),0.8757(PCA + RF)和ISIRS(0.9258),表明所提出的方法具有更强的概括能力。

小企业AI 机器学习/ 深度学习解决方案
Gartner 的数据显示 , 未来几年人工智能的发展将进一步加速 , 到 2020 年人工智能和机器学习将成为超过 30 % 的 CIO 的五大投

基于深度强化学习算法的火力⁃目标分配方法
plaa m makingabilit p e,whichcanp, the:lightife for:lightife fim⁃taietassignmietassignmient;diepieinfoifieinfoightimciemientlieaightimning;q⁃l
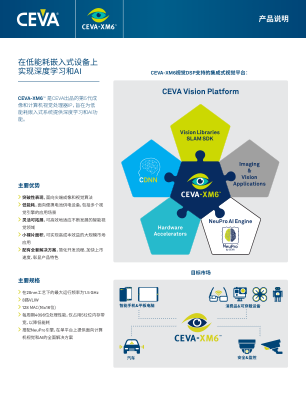
在低能耗嵌入式设备上实现深度学习和AI - Ceva, Inc.
智能嵌入式视觉应用的设计变得前所未有 的快捷而安全,这要归功于围绕 CEVA-XM6 DSP 而构建的全方位视觉平台。该平台包含 CEVA 深度神经网络( CDNN )编译器图表、计 算机视觉软件库以及一系列算法。

强于大市AI 端侧深度报告之AI 手机
智能手机是最适合承载端侧 AI 的载体, AI 手机可提供差异化的用户价 值与品牌价值。智能手机具有保有量大、使用便携、使用场景多、使用 时长久、应用生态系统强大等优势,可创造众多的 AI 使用场景,并加速 第三方 AI 应用成熟,我们认为智能手机将是生成式 AI 最佳的应用载体 之一。 AI 手机的定义具有三个典型特征:①能够在手机端侧运行大模型; ② SoC 中包含 NPU 算力;③达到一定参数要求的性能指标。 AI 手机可提 供差异化的用户价值与品牌价值。对用户而言, AI 手机将是自在交互、 智能随心、专属陪伴、安全可信的个人化助理,使用体验较目前阶段智 能手机大幅提升。对于手机厂商而言,可提供品牌形象与用户粘性。



元宇宙系列深度研究:脑机接口现状与未来
号质量,提高信噪比。特征提取根据特定的BCI范式所设计的心理活动任务相关的神经信号规律,采用时域、频域、空域方法或相 结合的方法提取特征。模式识别通过采用先进的模式识别技术或机器学习算法训练分类模型,针对特定的用户定制特征提取和解 码模型。 3. 控制接口:根据具体的通信或控制应用要求,控制接口把上述解码的用户意图所表征的逻辑控制信号转换为语义控制信号,并由

主导课程五:(深度学习)
2。R. S. Sutton和A. G. Barto,增强学习:介绍,第二版,2018年11月R. S. Sutton和A. G. Barto,增强学习:介绍,第二版,2018年11月