XiaoMi-AI文件搜索系统
World File Search System线性关系

数字智能 PIR 传感器 BS-612 - Adafruit
电压并不是线性关系。实际上,距离受自身信噪比、菲涅尔透镜成像距离、运动体温度、环境温湿度、电磁干扰等影响。因此输出不能用单一指标来评价,实际应用中请以调节结果为准。SENS Pin电压越小,检测距离越远。传感器有32级检测距离可供选择,最短可达厘米级。实际应用中,SENS通过分压电阻调节。

2021 KDIGO临床实践指南的概要
ARGE规模,前瞻性观察性研究表明,通常的血压(BP)(降至115/75 mm Hg)与中风,心肌梗死,心力衰竭,心力衰竭和其他心血管疾病之间存在对数线性关系(1)。降低BP的干预措施会导致这些风险的比例降低(2,3)。但是,在损害器官灌注之前可以安全地降低BP的程度,并且尚未定义BP的过度减少可能是有害的,尤其是在僵硬的管道动脉或已建立的闭塞性血管疾病的患者中。接受抗高血压药物的患者中观察数据的一些分析显示出J形的关系,其中非常低的BP与较高的不良后果率有关。这些观察发现的含义在其与设定BP目标的关系中引起了争议(4,5),因为迄今为止没有随机对照试验(RCT)可以通过较低的目标BP来结束较差的硬性结果,并且较低的益处是基于基本的基本依赖(SBP)(SBP)的依赖(SBP)。血压干预试验)。尽管如此,由于灌注不足或药物的副作用,BP减少会造成净伤害。观察性研究还显示了BP与随后的肾衰竭风险之间的线性关系(6,7),但是因果关系不太清楚,因为肾脏是BP控制中的中心器官,大多数肾脏疾病

使用ECG信号进行血糖监测的非侵入性方法
摘要简介:使用连续的葡萄糖监测仪(CGM),紧密的葡萄糖监测对于糖尿病患者至关重要。现有的CGM从间质液中测量血糖浓度(BGC)。这些技术非常昂贵,其中大多数都是侵入性的。先前的研究表明,低血糖和高血糖发作会影响心脏的电生理学。但是,他们没有确定BGC和ECG参数之间的队列关系。材料和方法:在这项工作中,我们提出了一种使用表面ECG信号确定BGC的新方法。复发性卷积神经网络(RCNN)用于分段ECG信号。然后,使用两个数学方程式使用提取的特征来确定BGC。使用表面ECG信号而不是心脏内信号,已从D1NAMO数据集对04例患者进行了对04例患者的测试。结果:我们能够使用RCNN算法以94%的精度分割ECG信号。根据结果,所提出的方法能够以平均绝对误差(MAE)为0.0539估计BGC,平均平方误差(MSE)为0.1604。此外,本文已经确认了BGC和ECG特征之间的线性关系。结论:在本文中,我们提出了ECG特征来确定BGC的潜在用途。此外,我们确认了BGC和ECG特征之间的线性关系。这一事实将为进一步研究(即生理模型)打开新的观点。此外,发现指出,通过机器学习,可以将ECG可穿戴设备用于非侵入性连续血糖监测。

政府规模和经济增长:概述
在1870年至2016年期间,17个高度发达国家8的公共部门规模对公共部门规模的平均值平均图表显示出Eco somic增长与公共部门规模之间的逆线性关系(见图1)。从1870年到2016年,中央政府的支出为GDP的份额平均为17%,平均人均GDP的平均增长率为2%。,英国的平均公共部门规模最高,为25%(相关增长率为1.5%),瑞士最低,为6%(增长率为1.7%)。当然,这种线性趋势却存在很大的差异,但该数字可以说明实际经济增长与公共部门规模之间的基本反相关关系。


量子电路学习作为一种预测的潜在算法......
图 1 量子电路的数学和视觉表达。初始状态的向上向量(数学上为 (1,0, … ,0) 𝑇 )通过 𝑉(𝒙) 的编码门进行旋转。图中显示了一个简单的情况,其中第 i 个量子位与 𝑥 𝑖 的角度一起旋转。然后,量子位通过 𝑈(𝜽) 的门进行交互。最后,使用概率分布观察到第一个量子位的向上或向下向量。𝑉(𝒙) 和 𝑈(𝜽) 的变换与初始状态向量成线性关系。最后的观察是一个非线性步骤。

动态系统中政府债券的最优展期...
4 Blanchard 和 Weil (2001) 在第三和第四个例子中使用了随机存储模型,因此产出与资本存量呈线性关系。在脚注 11 中,他们指出,这些模型可以扩展以纳入资本存量的凹度,方法是将产出指定为 Y t = K α t − δK t ,其中 δ 是随机变量,但他们没有计算出该模型的含义。Barro (2021) 使用了一个与我们的模型一样的随机折旧模型,但他指定 Y t = AK t ,因此,与 Blanchard 和 Weil 的简单随机存储规范一样,资本存量中没有凹度。
![arxiv:2401.01629v1 [cs.lg] 2024年1月3日](/simg/1\1904bc517d8e8e8c1dd7feb32aa47246b6aebc73.webp)
arxiv:2401.01629v1 [cs.lg] 2024年1月3日
用于描述分布,而概率质量函数(PMF)用于离散数据。当综合数据时,可以通过从现有数据的分布中进行采样来生成新的数据点。插值和外推。插值和诱惑涉及在现有数据点之间或之外生成新的数据点。这对于时间序列,地理数据等特别有用。一种常见的插值方法是线性插值,其中新点的值取决于两个已知点之间的线性关系。蒙特卡洛模拟。蒙特卡洛模拟启用随机抽样,以模拟真实系统中的不确定性。在数据综合中,该方法用于通过随机从已知的分布中进行随机采样来生成新样本。它在财务,工程和物理建模中找到了常见的应用。基于模型的采样。此方法涉及利用现有数据的统计模型来预测新的数据点。例如,可以将线性回归模型拟合到存在数据,并且可以通过随机采样模型参数来生成新的数据点。这种方法对于表现线性关系的数据特别有效。内核密度估计。 内核密度估计插入每个数据点周围放置核(通常是高斯内核)并计算每个点的贡献以估计概率密度函数。 这对于捕获数据分布的复杂性和多模式很有用。内核密度估计。内核密度估计插入每个数据点周围放置核(通常是高斯内核)并计算每个点的贡献以估计概率密度函数。这对于捕获数据分布的复杂性和多模式很有用。生成新样本时,可以根据估计的概率密度函数进行随机采样。
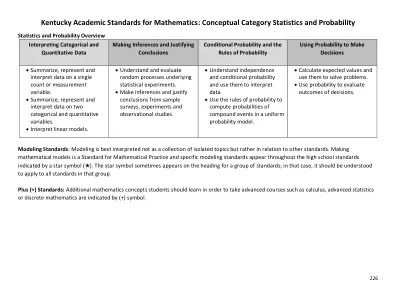
肯塔基州学术标准数学
在两个定量变量解决方向(正或负)与给定关联的相对强度之间。c。学生理解对相关性最常见的误解之一是将其视为因果关系的同义词。两个变量之间的高相关性(表明两者之间的统计关联)并不意味着一个会导致另一个变量。遵守数学实践学生的标准学生将结果解释为统计问题,并将结果与数据背景(,)相关联。学生使用技术来计算相关系数()。学生认识到相关是两个定量变量之间的线性关系的指示,而不仅仅是coomission()的另一个词。

俄罗斯人工智能——2023 年:趋势与前景
在发展过程中,机器学习模型在解决的问题复杂性方面已经取得了长足的进步。其中最简单的方法是寻找少量因素之间的线性关系,然后使用发现的模式进行预测——例如,根据距离、交通信号灯数量等预测旅行时间。随着考虑的因素数量的增加,需要能够识别非线性关系的更复杂的模型。当今最先进的模型采用神经网络架构,拥有数千亿个参数,使得它们能够在数据中找到非常复杂的模式。使用这样的模型,可以预测行程的持续时间,同时考虑一天中的时间、一周中的哪一天、交通拥堵和天气等因素。