XiaoMi-AI文件搜索系统
World File Search System线性模型

面向未来的电子行业:
在本报告中,我们介绍了经过近一年的研究与合作(包括公司内部和外部各方),我们试图量化转向更循环的商业模式对气候和财务带来的好处。我们以电子行业为案例研究,但我们相信几乎所有行业都有潜力实现转向更循环的商业模式的价值。我们的模型评估了电子行业四个不同细分市场的三种不同的循环商业模式,发现不同的策略在不同的细分市场中表现优异,这取决于相关业务是寻求优化以降低成本还是减少环境影响,但我们的主要发现是,与使用线性模型(一切照旧)方法相比,本报告中分析的所有循环商业模式(循环投入、再制造和 PaaS)都更具成本效益,并在未来 12 年内显着减少二氧化碳当量。

量子测量问题
• 非线性——无论内部还是环境的线性“退相干”[3](相位随机化)都无法解释共存量子可能性的消失[4],[5],因为一切,包括测量仪器和观察者,都是由量子实体组成的。例如,[6] 很好地、透明地证明了这一点。无论一个数学上的线性系统有多大,它都不可能神奇地自行变成非线性——这也相当于“奇迹”,而不是物理学。在任何纯线性量子模型中,叠加态都会无限期地持续存在,遵循幺正演化。通过对越来越大的子系统叠加进行无限回归,即“冯·诺依曼链”,这不可避免地导致了这样的结论:在线性模型中,任何东西都无法测量(!)3 [8],或者导致了一个多重世界图景[9],但除了不可测试和缺乏科学可预测性之外(因为任何不是绝对禁止的事情都保证会发生在某些共存的、线性叠加的平行世界中),甚至对于

STEM 奖学金 UCalgary 研究实习计划 ...
基于我们在数据分析和协作方面的经验,我们开发了生物信息学和生物统计学工具来处理研究人员遇到的最新问题。到目前为止,我们已经开发了几个工具包,重点关注(1)从汇集测序中推断单倍型,(2)用于统计遗传学的核外工具(将数据存储在磁盘中,但访问它们就像它们驻留在内存中一样),以及(3)用于群体遗传学和进化分析的快速而强大的工具。研究主题 3:我们对机器学习中的理论问题感兴趣,灵感来自我们在实际数据分析中的观察和机器学习领域的最新出版物。特别是,我们关注在集成领域知识和/或应用迁移学习时机器学习模型的行为。我们还试图描述何时以及如何用线性模型来近似非线性生物系统。

教学大纲
Python简介 - Google Colab和Jupyter笔记本,数据结构,熊猫(读,写文件,加载数据等),Numpy等。。matplotlib(区域图,散点图,线图,直方图,条形图,框图,热图,刻面,配对图),Seaborn。什么是数据科学,各种类型和数据级别,结构化与非结构化数据,定量数据,定性数据,数据科学生命周期等。数据收集和准备,缺失价值处理,数据擦洗,数据转换,探索性数据分析,人群和样本,矩和生成功能,可变性,假设测试,偏差和方差的度量。有监督的分类,例如KNN和无监督的分类,例如K-均值聚类,模型定义和培训,模型评估。特征工程,尺寸降低 - PCA,回归线性模型:线性回归,逻辑回归。

计算机科学学士 2022-2026
本文件仅显示目录发布时的课程要求。您必须使用学位进度报告来跟踪所有毕业要求。计算机科学通识课程 CSC 466 从数据中发现知识 4 20 CSC 480 人工智能 4 CSC 487 深度学习 4 4 STAT 334 应用线性模型 4 MATH 241 微积分 IV 8 MATH 248 数学证明方法 CPE/EE 428 计算机视觉 MATH 306 线性代数 II CSC 481 基于知识的系统 MATH 334 组合数学 CSC 482 语音和语言处理 MATH 335 图论 CSC 566 高级数据挖掘主题 MATH 437 博弈论 CSC 580 人工智能 MATH 470 选定的高级主题 CSC 581 知识管理的计算机支持 STAT 305 概率与模拟简介 CSC 582 计算语言学 STAT 323 实验设计与分析 I CSC 587 高级深度学习 STAT 324 应用回归分析 DATA 301 数据科学简介 STAT 330 使用 SAS 进行统计计算 EE 509 计算智能 STAT 331 使用 R 进行统计计算 STAT 434 统计学习:方法与应用 STAT 334 应用线性模型 24 STAT 416 时间序列的统计分析 STAT 418 分类数据分析 STAT 419 应用多元统计 STAT 434 统计学习:方法与应用 CSC 366 数据库建模、设计和实现 4 24 CSC 436 移动应用程序开发 4 或 CSC 437 动态 Web 开发或 CSC 309 软件工程 II CSC 466 从数据中发现知识 4 CSC 468 数据库管理系统实现 4 或 CSC 469 分布式系统 4 CPE/EE 428 计算机视觉 CSC 369 分布式计算简介CSC 400 特殊问题 2

如何不自欺欺人治疗效果的异质性
我们提出18个具体建议,并以教育研究的示例为其说明。The most common themes are to (1) seek heterogeneity only when the mechanism offers clear motivation and the data offer adequate power, (2) shy away from seeking “no-but” heterogeneity when there is no main effect, (3) separate the noise of estimation error from the signal of true heterogeneity, (4) shrink variation in estimates toward zero, (5) increase p values and widen confidence intervals when conducting multiple tests, (6)估计相互作用而不是亚组效应,(7)检查异质性发现是否对模型或测量的变化敏感。我们还解决了有关在线性模型中核心相互作用的长期辩论,并估计了非线性模型(例如逻辑,序数和间隔回归)中的相互作用。如果研究人员遵循这些建议,那么对异质性的搜索将在将来产生更多值得信赖的结果。

数据621:高级统计建模
主题包括:健康研究方法,使用模型诊断和模型选择的多个线性回归审查,建模二进制结果:逻辑回归和ROC分析。通过泊松回归和负二项式回归来计算数据和速率,发病率,速率比和建模。在非独立/聚类数据设置中建模:GEE,混合效应模型。在线性模型设置(分类,平滑花键等)中捕获和建模非线性关系。时间序列分析和趋势分析,季节性和异常检测的相关算法。学习资源/所需阅读您将在本课程中使用R Studio。请参阅R Studio(https://rstudio.com/products/rstudio/)的下载说明。选择带有开源许可证的R Studio Desktop选项(页面上的第一列选项)。本身不需要教科书。读取和教科书是建议的,除非在讲座中或具体说明。推荐资源:

火箭发射器的主动姿态控制
由于运载火箭的性能与其飞行控制系统密切相关,因此航天飞行中的一个重大挑战是设计姿态控制算法,以确保运载火箭的稳定性,同时遵循确定的轨迹并抑制外界干扰。本报告旨在描述设计这种控制算法并最终评估其性能的通用方法。首先,回顾了现有的姿态控制方法并介绍了线性控制理论。然后介绍影响运载火箭的重要现象,包括刚体动力学、空气动力学、发动机惯性、下垂模式和弯曲模式。然后,使用给定的案例研究作为示例来估计描述所有这些现象的参数。然后推导线性运动方程,并提出构建车辆及其执行器的状态表示的方法。基于该线性模型,本文描述了一种逐步方法来计算用于处理所有相关现象的稳定 PID 控制器。最后,进行包括稳定性、时间响应、灵敏度和鲁棒性在内的性能分析,以评估控制器行为。
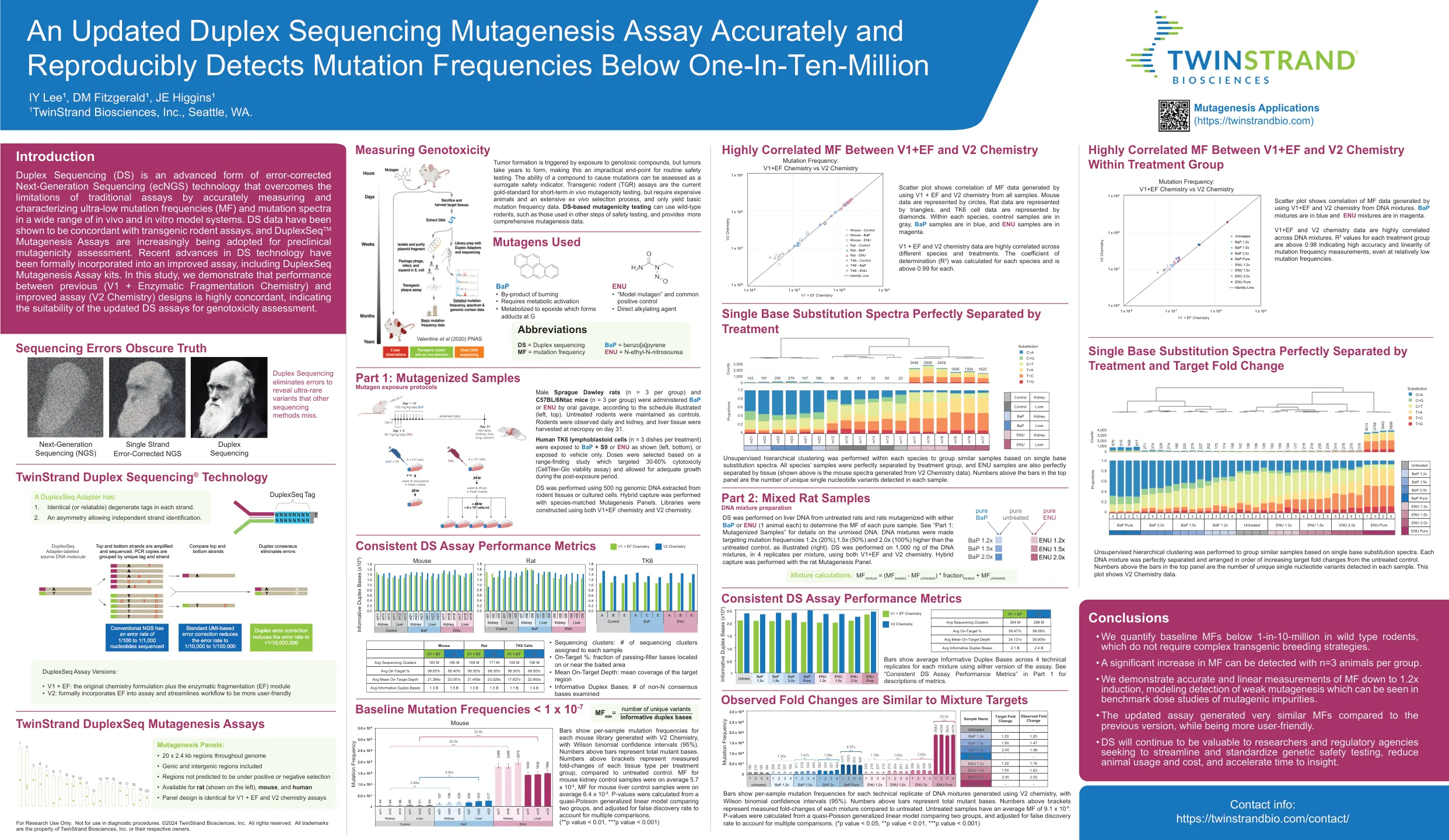
准确的更新的双链测序诱变测定法,可重复检测到低于一十分三百万的突变频率
条显示了用V2化学产生的每个小鼠文库的每样本突变频率,威尔逊二项式置信区间(95%)。条上方的数字代表总突变碱基。与未处理的对照相比,支架上方上方的数字代表每个治疗组的每种组织类型的倍数变化。MF平均为5.7 x 10 -8,小鼠肝对对照样品的MF平均为6.4 x 10 -8。p值是从比较两组的准散孔概括的线性模型中计算得出的,并根据错误的发现率进行了调整以考虑多个比较。(** p值<0.01,*** p值<0.001)仅用于研究使用。不适用于诊断程序。©2024 Twinstrand Biosciences,Inc。保留所有权利。所有商标都是Twinstrand Biosciences,Inc。或其各自所有者的财产。

分段线性建模,具有自动化功能选择,用于锂离子电池终止预后
锂离子电池降解的复杂性质导致文献中提出了许多基于机器的基于机器学习的方法。但是,使用复杂模型的机器学习在计算上可能很昂贵,尽管线性模型的速度更快,但它们也可能不灵活。分段线性模型提供了一种折衷,这是一种快速而灵活的替代方案,其计算上的昂贵不如神经网络或高斯过程回归等技术。在这里,将电池健康预测的分段线性方法(包括自动化功能选择步骤)与高斯流程回归模型进行了比较,并且发现在训练数据集中的中位错误方面表现出色,并且在第95个误差百分位数上的表现确实更好。特征选择过程演示了限制输入之间的相关性的好处。进一步的试验发现,分段线性方法可用于改变培训数据的输入大小和可用性。