XiaoMi-AI文件搜索系统
World File Search System翻译

翻译若干促进高质量发展的政策...
《关于鼓励软件产业和集成电路产业发展的若干政策》(国发[2000]18号)和《国务院关于印发进一步鼓励软件产业和集成电路产业发展若干政策的通知》(国发[2011]4号),为我国信息化发展作出了重要贡献,促进了国民经济和社会持续健康发展。这些政策是为了进一步优化集成电路和软件产业发展环境,深化国际产业合作,提高产业创新能力和发展质量而制定的。

Lee,B。H.,Shin,H.,Rasouli,A。S.,Choubisa,H.,Ou,P.,Dorakhan,R。,...&Sargent,E。H.(2023)。支撑的金属邻thal的超分子调整 朝着bory的合成(氨基甲基... ROS如何诱导Netosis?氧化DNA损伤,DNA修复和染色质脱凝 使用斑马鱼研究多外观跳过作为的潜在疗法 啮齿动物的心肌病和心力衰竭的啮齿动物模型,用于翻译研究和治疗发现
1.3 T HIS W ORK ................................................................................................................................................ 21

翻译方法 Elie Bou Assi1,2*,Kaspar ...
请注意,本文计划在 ICTALS 2022 特别版中发表。致谢:我们感谢伯尔尼大学、Inselspital、伯尔尼大学医院、癫痫研究联盟、瑞士国家科学基金会 (SNF)、UCB、FHC、Wyss 生物和神经工程中心、美国癫痫协会 (AES)、CURE 癫痫基金会、Ripple neuro、Sintetica、DIXI medical、UNEEG medical 和 NeuroPace 通过无限制的教育捐款为伯尔尼 ICTALS 2022 会议提供慷慨赞助。AR 和 KS 感谢 SNF 拨款 200800 的支持。CR 感谢 SNF 通过拨款 204593 提供的支持。EBA 感谢数据价值研究所 (IVADO, 51627) 和蒙特利尔大学医院研究中心 (CRCHUM, 51616) 的资金支持。利益冲突:Elie Bou Assi、Kaspar Schindler、Christophe de Bézenac、Simon S. Keller、Émile Lemoine、Abbas Rahimi、Mahsa Shoaran 和 Christian Rummel 没有利益冲突需要披露。

第13章。西班牙语期刊中翻译的定量分析(1900-1945):一种方法论建议
信息仅限于期刊名称和数字,但缺乏有关所包含的文章(例如文章)的信息,该文章发表在给定问题中。因此,当尝试采用大规模的方法和观点时,就不可能完全掌握过去的期刊媒体发表的内容。并不意味着数字化的文本语料库是不合适的或不适合文化研究的。计算语言学和数字工具已根据数字化书籍的文化趋势进行了研究(Michel等人2011; Gulordava和Baroni 2011; Juola 2013)和历史报纸(Lansdall-Welfare等人。2017; Cristianini,Lansdall福利和Dato 2018)。TESE研究,基于将统计方法应用于整个语料库(Tahmasebi et al。2015),定量描述了随着时间的流逝,语言,文化和历史现象的发展。但是,正如Koplenig(2015)所表明的那样,元数据本身是重要的信息来源,需要上下文化和限定结果。te量化的书籍翻译已经是翻译研究中已建立的批准,尽管它忽略了书籍内容,但它最著名的是引起了译本的翻译学,正如Heilbron(1999)所提出的。将大规模的定量分析带入了周期出版物中翻译的研究。特别是在西班牙和拉丁美洲的著作期刊中,已经出版了多少译本,尚无概念,哪些作者的作者已经翻译而来。1数字方法像本文中提出的那样,旨在使我们处于这个位置,不仅要回答这些问题,而且还要深入研究对不同空间和时间的文化期刊的循环和接收的循环和接收。我们认为,这种方法可以有助于提前书本历史,文学史和西班牙裔世界的文学翻译历史。更一般地,对西班牙语现代文学期刊的分析将从二十世纪的前半段分析,将为了解西班牙裔领域的文学现代性提供新的优势点,并将为与书籍翻译进行比较,使我们能够绘制两个平台,或者在这两个平台之间进行文字循环。
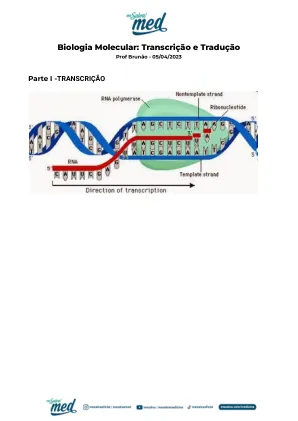
05/04/2023 |分子生物学:转录和翻译。多克克斯
4。(Enem 2011)如今,我们可以说,几乎所有人类都听过DNA及其在大多数生物的遗传中的作用。但是,直到1952年,沃森和克里克的双螺旋桨DNA模型描述的前一年,毫无疑问,这是DNA是遗传物质。在Watson和Crick描述DNA分子的文章中,他们提出了该分子应如何复制的模型。在1958年,梅塞尔森(Meselson)和斯塔尔(Stahl)使用沉重的氮同位素进行了实验,这些同位素被纳入氮基碱基,以评估分子复制的发生方式。从结果来看,他们证实了沃森和克里克所建议的模型,沃森和克里克的基本前提是氮碱基之间的氢桥的破裂。

立场文件:机器翻译应该被标记为 AI 生成的内容吗?
2023 年 9 月,加拿大政府发布了《生成式人工智能使用指南》,其中为加拿大政府机构及其员工提出了建议。与近年来各组织发布的其他类似文件一样,该文件就透明度提出了建议,指出每当使用生成式人工智能生成内容时,都应告知读者“发给他们的消息是由人工智能生成的”。虽然本指南没有专门针对机器翻译的情况,但它确实提到翻译是生成式人工智能的潜在应用。因此,自然而然地出现了一个问题:无论在哪里使用机器翻译的文本,都应明确标记为人工智能生成的内容吗?在本立场文件中,我们详细研究了这个问题,目的是提出关于机器翻译的明确指导方针,不仅针对政府机构,也针对任何使用机器翻译技术的人。我们的主要结论是,机器翻译的文本确实是 AI 生成的内容。因此,应在使用它的所有地方明确标记。我们就这种标记可能采取的形式提出建议。我们还研究了在什么条件下可以删除或省略 MT 标记。

翻译人民法院人工智能法...
Authors Drafting Expert Group ( 起草 专 家 组 ) comprised of Professor Zhang Linghan ( 张 凌寒 ) of China University of Political Science and Law ( 中国政法大学 ), Professor Yang Jianjun ( 杨 建 军 ) of Northwest University of Political Science and Law ( 西北政法大学 ), Senior Engineer Cheng Ying ( 程 莹 ) of China Academy of Information and Communications Technology (CAICT; 中国信息通信研究院 ; 中国信通院 ), Associate Professor Zhao Jingwu ( 赵 精武 ) of Beijing University of Aeronautics and Astronautics (Beihang University; 北京航空航天大学 ), Associate Professor Han Xuzhi ( 韩 旭至 ) of East China University of Political Science and Law ( 华东 政法大学 ), Professor Zheng Zhifeng ( 郑 志峰 ) of Southwest University of Political Science & Law ( 西南政法大学 ), and Associate Professor Xu Xiaoben ( 徐小奔 ) of Zhongnan University of Economics and Law ( 中南 财经 政法大学 )

增强翻译中风康复:运动网络优化的特定任务动作观察疗法
年龄(年)71.7±10.8性别(女性 /男性)%8(40%) /12(60%)MAS-ul 1.25(0-6)FMA-UL 51(29-66)脂肪5(1-5)MBI 94(1-5)MBI 94(46-100)平均±标准偏差; n(%);中值(最小值最小)。修改后的Ashworth Scale-upper肢体(MAS-ul); FUGL-MEYER评估 - Upper肢体(FMA-ul);法式手臂测试(FAT);和修改的Barthel指数(MBI)。

生物学2024 | Brunão|笔录和翻译
4。(Enem 2011)如今,我们可以说,几乎所有人类都听过DNA及其在大多数生物的遗传中的作用。但是,直到1952年,沃森和克里克的双螺旋桨DNA模型描述的前一年,毫无疑问,这是DNA是遗传物质。在Watson和Crick描述DNA分子的文章中,他们提出了该分子应如何复制的模型。在1958年,梅塞尔森(Meselson)和斯塔尔(Stahl)使用沉重的氮同位素进行了实验,这些同位素被纳入氮基碱基,以评估分子复制的发生方式。从结果来看,他们证实了沃森和克里克所建议的模型,沃森和克里克的基本前提是氮碱基之间的氢桥的破裂。

脑机接口翻译伦理指南...
脑机接口研究中采集的神经数据或实验样本反映了受试者的心理状态、生理健康、人格特质、财富信息等,属于隐私数据。采集数据的范围和人员的访问权限应经伦理委员会批准。应制定适当的处理和管理方案,并根据信息安全管理相关法律法规和技术标准,在数据或样本的采集、存储、使用、处理、传输、发布等全过程中对其进行保护。遵守《中华人民共和国个人信息保护法》《中华人民共和国数据安全法》等法律法规,加强风险监测,防止数据或样本泄露,保障数据安全和受试者的隐私及个人信息安全。