XiaoMi-AI文件搜索系统
World File Search System解释

聚焦 LRP:用于人脸变形攻击检测的可解释 AI
近年来,检测变形人脸图像的任务变得非常重要,以确保基于人脸图像的自动验证系统(例如自动边境控制门)的安全性。基于深度神经网络 (DNN) 的检测方法已被证明非常适合此目的。然而,它们在决策过程中并不透明,而且不清楚它们如何区分真实人脸图像和变形人脸图像。这对于旨在协助人类操作员的系统尤其重要,因为人类操作员应该能够理解其中的推理。在本文中,我们解决了这个问题,并提出了聚焦分层相关性传播 (FLRP)。该框架在精确的像素级别向人类检查员解释深度神经网络使用哪些图像区域来区分真实人脸图像和变形人脸图像。此外,我们提出了另一个框架来客观地分析我们方法的质量,并将 FLRP 与其他 DNN 可解释性方法进行比较。该评估框架基于移除检测到的伪影并分析这些变化对 DNN 决策的影响。特别是,如果 DNN 的决策不确定甚至不正确,与其他方法相比,FLRP 在突出显示可见伪影方面表现得更好。
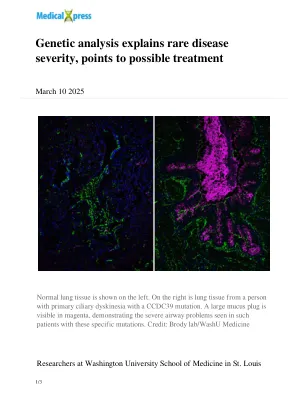
遗传分析解释了罕见疾病的严重程度,指向可能的治疗
由遗传学教授苏珊·荷兰(Susan K.除了功能失调的睫状网络之外,缺失的结构还导致某些应该具有纤毛的细胞产生粘液,这可能会导致气道问题增加。

使用机器学习的基于手语解释器-IJRPR
耳聋是一种全球状况,影响了约4.66亿人,其中包括约3400万儿童。聋哑人在日常生活中面临许多挑战,尤其是在沟通,教育,就业和社会化等领域。普遍的误解是聋人无法交流;但是,许多人依靠手语作为其主要互动手段。手语是一种丰富而复杂的语言,配有其自身的语法和语法,在不同的文化和地区各不相同。认识到聋人社区内的多样性对于培养所有个人的包容性和可访问的社会至关重要,无论其听力状态如何。尽管有手语的重要性,但聋人与不使用手语的人之间有效的沟通有很大的差距。这个差距会导致误解,社会隔离以及获得基本服务的有限访问。为了解决这个问题,我们介绍了Slingo,这是一款创新的基于应用程序的手语解释器,旨在弥合听力受损的个人和非手语用户之间的沟通鸿沟。Slingo利用高级机器学习技术和计算机视觉实时检测和解释手语手势。该系统包括两个主要组成部分:图像捕获系统和机器学习模型。图像捕获系统利用设备的摄像头来捕获用户的手移动,而机器学习模型则处理这些图像以准确解释符号并在屏幕上显示其含义。Slingo系统的多功能性允许在各种环境中使用它,包括教育机构,工作场所和公共场所,从而促进听力障碍的个人与不使用手语的人之间有效的沟通。通过增强沟通可及性,Slingo旨在改善听力障碍者的生活质量,并促进各种环境中更大的包容性。本文将探讨Slingo的发展,功能和潜在应用,并强调其在应对聋人社区所面临的沟通挑战方面的重要性。

通过将政策提炼为程序来评估可解释的强化学习
存在强化学习之类的应用,例如医学,其中政策需要被人类“解释”。用户研究表明,某些政策类可能比其他政策类更容易解释。但是,进行人类的政策解释性研究是昂贵的。此外,没有明确的解释性定义,即没有明确的指标来解释性,因此主张取决于所选的定义。我们解决了通过人类解释性的经验评估政策的问题。尽管缺乏明确的定义,但研究人员对“模拟性”的概念达成了共识:政策解释性应与人类如何理解所给出的政策行动有关。为了推进可解释的强化学习研究,我们为评估政策解释性做出了新的方法。这种新方法依赖于代理来进行模拟性,我们用来对政策解释性进行大规模的经验评估。我们使用模仿学习来通过将专家神经网络提炼为小程序来计算基线政策。然后,我们表明,使用我们的方法来评估基准解释性会导致与用户研究相似的结论。我们表明,提高可解释性并不一定会降低表现,有时会增加它们。我们还表明,没有政策类别可以更好地跨越各个任务的可解释性和绩效进行交易,这使得研究人员有必要拥有比较政策可解释性的方法。


DNA脱甲基解释了番茄如何将其苦毒素转化为更可口的
要找出蛋白质在转化过程中扮演的角色,研究人员设计了番茄植物来开关和关闭生产,使他们能够看到他们的影响。他们发现了一种叫做DML2的,该DML2在关闭产量时阻止了糖基类动物的分解,使水果太苦了,无法吃。进一步的研究表明,该蛋白质能够通过称为脱甲基化的化学过程分解糖基虫类。

解释了CDK介导的细胞周期控制中的冗余:统一连续性和定量模型
摘要:在真核生物中,Cyclin依赖性激酶(CDKS)是DNA复制和有丝分裂的必需的,并且在整个细胞周期中,依次激活了不同的CDK-循环蛋白复合物。普遍认为,特定的复合物需要遍历G1中细胞周期的承诺,并分别促进S期和有丝分裂。因此,根据一个流行的模型,几十年来一直占据了领域的流行模型,在细胞周期的每个阶段,针对不同底物的独特CDK – cyclin compleces固有的特定座位生成了事件的正确顺序和时间。但是,编码细胞周期蛋白和CDK的基因敲除的结果不支持此模型。通过许多最近的工作验证的替代性“定量”模型表明,CDK活性的总体水平(具有相反的磷酸酶输入)决定了S期和有丝分裂的时间和顺序。我们通过建议将细胞周期分为离散阶段(G0,G1,S,G2和M)的细分被过时且有问题,从而进一步采用了该模型。相反,我们恢复了细胞周期的“连续性”模型,并提出与定量模型的结合更好地定义了理解细胞周期控制的概念框架。
葡萄糖:可解释的餐后血糖预测和体育锻炼
摘要 - 以餐后的血糖水平超过正常范围的标志性的植物性高血糖,这是在糖尿病和健康个体中向2型糖尿病进展的关键指标。饮食后了解血糖动力学的关键指标是曲线下的餐后区域(PAUC)。根据人的饮食和活动水平预测PAUC,并解释什么影响餐后血糖可以使人可以相应地调整其生活方式以维持正常的葡萄糖水平。在本文中,我们提出了葡萄糖,这是一种可解释的机器学习,以预测饮食,活性和最近的葡萄糖模式中的PAUC和高血糖。我们对10个全职工作人员进行了为期五周的用户研究,以开发和评估计算模型。我们的机器学习模型采用多模式数据,包括空腹葡萄糖,近期葡萄糖,最近的活性和大量营养素量,并提供了可解释的餐后葡萄糖模式的预测。我们对收集到的数据的广泛分析表明,训练有素的模型达到了0.123的归一化均方根误差(NRMSE)。平均而言,带有随机森林主链的葡萄糖素比基线模型可获得16%的结果。此外,血糖素可以准确地预测高血糖率74%,并建议通过不同的反事实解释来帮助避免高血糖。可用代码:https://github.com/ab9mamun/glucolens。

o r i g i n a l r e s a r c h可解释的预测芬兰2型糖尿病患者的长期糖化血红蛋白反应变化
目的:本研究应用机器学习(ML)和可解释的人工智能(XAI)来预测HbA1c水平的变化,这是监测血糖控制的关键生物标志物,在诊断为2型糖尿病患者的患者中,在启动一种新的抗糖尿病药物后的12个月内。它还旨在确定与这些变化相关的预测因素。患者和方法:来自芬兰北卡雷利亚(North Karelia)的10,139名2型糖尿病患者的电子健康记录(EHR)用于训练整合了随机对照试验(RCT)衍生的HBA1C变化值作为预测变量的预测因子,创建将RCT洞察力与现实世界中集成的偏移模型。各种ML模型 - 包括线性回归(LR),多层感知器(MLP),山脊回归(RR),随机森林(RF)和XGBoost(XGB) - 使用R²和RMSE衡量标准进行评估。基线模型在药物启动之前或之前使用的数据,而随访模型包括第一个药物后HBA1C测量,通过合并动态患者数据来改善性能。模型性能也与临床试验中预期的HBA1C变化进行了比较。结果:结果表明,ML模型的表现要优于RCT模型,而LR,MLP和RR模型具有可比性的性能,RF和XGB模型表现出过于拟合。与基线模型相比,随访MLP模型的表现优于基线MLP模型,其R²得分(0.74,0.65)和较低的RMSE值(6.94,7.62)与基线模型(R²:0.52,0.54; RMSE; RMSE:9.27,9.50)相比。HBA1C变化的关键预测因子包括基线和药后HBA1C值,禁食等离子体葡萄糖和HDL胆固醇。未来的研究将探索治疗选择模型。结论:使用EHR和ML模型可以开发对HBA1C变化的更真实和个性化的预测,考虑到更多样化的患者人群及其异质性,为管理T2D提供了更量身定制和有效的治疗策略。XAI的使用提供了对特定预测因子影响的见解,从而增强了模型的解释性和临床相关性。关键字:类型2糖尿病,HBA1C,治疗效果估计,机器学习,Shap

技术解释器
AI图像生成模型(例如DALL-E 1)由神经网络组成,这些网络经过大量训练数据训练,包括图像和文本。由于培训过程,模型包含模式的数学表示和语言和图像之间的关联,然后在输入提示时将其部署以生成新图像。对AI图像生成的常见误解是,该模型通过结合从确定性过程中逐件存储的训练数据片段收集的特定特征来构建图像,这不是其工作原理。在高级别上,图像生成过程可以分为两个部分:首先,模型必须“理解”文本提示以指导图像生成过程,其次,该模型必须使用该“理解”来创建清晰的图像。这两个部分涉及两个不同的模型体系结构,它们具有不同的训练过程和不同的推理步骤。该过程的第一部分使用基于变压器的文本编码器,类似于生成文本的模型中使用的文本编码器,例如我们以前的技术解释器2中所述的GPT模型。该过程的第二部分涉及