XiaoMi-AI文件搜索系统
World File Search System训练集

代表视觉艺术家社区制定的人工智能开发者行为准则
艺术家权利协会 (ARS) 是美国首屈一指的视觉艺术家版权、许可和监控组织。我们代表全球 120,000 多名艺术家,并且是国际版权管理协会联盟 CISAC 的骄傲成员。自 1987 年以来,我们一直致力于保护和促进视觉艺术家的权利。我们认识到,生成式人工智能系统对视觉艺术家和版权所有者的生计构成了独特的威胁。虽然人工智能可以合乎道德地用于补充人类作品,但未经同意或向版权所有者提供补偿而大量获取受版权保护的作品,以及生成旨在破坏和取代人类艺术家的创造力和劳动的作品,是不公正的。考虑到视觉艺术家,我们提出了一套供人工智能开发人员遵守的基本规则,旨在减轻对艺术家生计和人类作者受版权保护作品的市场价值造成损害的风险。我们的目标是,这些准则确保作品用于训练集的创作者和生成式 AI 技术的用户的透明度,强调 AI 可以合乎道德且安全地用作创作工具。此外,我们建议权利人保留对其知识产权的控制权,并通过合法许可为已摄取其作品的 AI 输出获得补偿。I. 摄取 AI 训练集图像的准则版权所有者的同意:版权法保护艺术家和版权所有者,赋予他们决定如何使用其作品的能力。AI 开发人员在将其作品摄取到 AI 训练集之前必须征得版权所有者的同意。版权所有者或其授权代表可以单独获得同意,并且“选择加入”选项应得到充分宣传、易于使用,并且创作者可以随时有效地撤销。同样,AI 开发人员必须遵守版权所有者的任何要求,删除未经同意摄取的图像。对创作者的补偿:生成式 AI 直接依赖于其训练集中目前使用的数百万个受版权保护的作品。如果不利用这些受版权保护的作品,他们的成果就不会存在。人工智能系统必须向版权持有者补偿其在训练集中使用其材料的费用。

逻辑提取:增强人工智能在抽象和推理语料库任务中的泛化能力
1.2 挑战与影响 ARC 公开测试中,人类的平均表现准确率超过 60%[ 3 ]。相反,最有能力的模型利用 SOTA LLM[ 4 ] 也只能达到 50% 以下的准确率。考虑到大量的预训练数据,当前人工智能与人类之间的差距更加明显。对 ARC 竞赛解决方案的研究可以为我们对人类思维中的直觉和推理过程进行建模提供重要见解,促进新型人工智能范式的构建。同时,“[至少,解决 ARC-AGI 将产生一种新的编程范式[ 5 ]”,只需展示几个输入输出示例,就可以让没有编码经验的人进行程序合成。2 竞赛细节 数据集 ARC Prize 竞赛提供三个数据集:公共训练集、公共评估集和私有评估集。公共训练集和公共评估集均包含 400 个任务文件,而私有评估集包含 100 个任务文件。每个任务有 2 到 10 对(通常为 3 个)示例和 1 到 3 对(通常为 1 个)测试[2, 6]。指标 我们可以通过两种方法评估性能: 1)像素正确性 - 正确推断的像素占总数的百分比; 2)正确/不正确 - 推断的输出在形状、颜色和位置方面是否与任务的测试输出相匹配。竞赛使用第二种方法评估提交内容[6]。

协作视觉文本表示为开放式摄取分段(补充材料)优化
- 可可固定:可可固定是一个大规模的语义分割数据集,其中包含164k图像,带有171个带注释的类,分为训练集(118k映像),验证集(5K图像)和测试集(41K图像)。在我们的实验中,我们使用完整的118K训练集作为训练数据来训练语义模型。- 可可式式:可可式跨跨培训图像与可可固定相同的训练图像。这些图像被标记为133个类别。在我们的经验中,我们使用可可式式跨跨景模型。- Pascal-voc:Pascal-Voc包括1,449张图像,用于20个宣传类。在开放式语义语义分割中,所有20个类均用于评估(称为PAS-20)。- ADE20K:ADE20K是一个大规模的场景,理解数据集构成了2K图像,用于验证两种注释:一种具有150个类的班级,带有Panoptic注释,另一个带有847个课程的语义注释。对于开放式语义语义分割,我们在ADE20K的两个设置上评估了我们的方法:150个类(称为A-150)和847类(称为A-847)。在开放式综合综合分割中,我们使用带有150个类注释的设置进行评估。

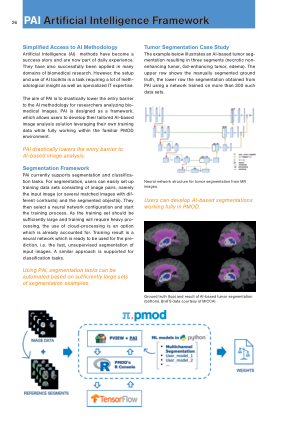
基于深度学习的自动脑肿瘤分析
分割是对图像进行划分,使其更有意义且更易于分析。在本研究中,使用 Otsu 阈值对肿瘤进行分割。这有助于从健康组织中定位肿瘤区域,这对于计划治疗和患者随访是必需的。整个肿瘤分析过程是在 MATLAB 中用户友好的 App 设计器中实现的。1.1 目标 为医学领域贡献深度学习技术,使肿瘤分析更准确、更高效。 通过多模态融合结果实现一种自动肿瘤分类和分割算法,以供进一步分析。 使用 MATLAB 中的 App 设计器显示整个肿瘤分析过程。2. 材料与方法由于大脑结构复杂,脑肿瘤分析过程是一项艰巨的任务。肿瘤分析过程涉及四个模块:预处理、多模态融合、肿瘤分类和分割。最后,使用 App 设计器在 MATLAB 2020b 中实现这些模块,它很吸引人且易于使用。 2.1 数据集我们使用公开的 Kaggle 数据集,其中训练集用于训练模型,验证集用于评估所提出的集成。训练集包括 395 张无肿瘤图像、826 张胶质瘤图像、822 张脑膜瘤图像和 827 张垂体瘤图像。我们

密歇根大学EECS 442:计算机视觉秋季2024年。
注意:启动器代码中有一个调试标志,在调试代码时,您可以将其设置为True。设置标志时,只有20%的训练集被加载,因此其余的代码应花费更少的时间运行。但是,在报告问题的答案之前,请记住将标志设置回False,然后重新运行单元格!还有一个选项可以运行具有不同图像大小的代码,欢迎您尝试(再次,请在提交之前将其设置回默认值!)。

生成或复制:听觉音频潜伏...
摘要引入了具有文本描述的逼真的声音剪辑能力的音频潜在不同模型,该模型有可能彻底改变我们与音频的合作方式。在这项工作中,我们初步尝试通过调查其音频输出与培训数据的比较方式来了解音频潜在不同使用模型的内部工作,这与医生如何通过听取器官的声音来听诊患者。在AudioCaps数据集中训练的文本对审计潜在分歧模型,我们系统地分析了记忆行为,作为训练集大小的函数。 我们还评估了不同的检索指标,以证明训练数据记忆的证据,发现MEL频谱之间的相似性在检测匹配方面比嵌入向量更强大。 在分析音频潜在不同使用模型中的记忆过程中,我们还发现了AudioCaps数据库中的大量重复的音频剪辑。在AudioCaps数据集中训练的文本对审计潜在分歧模型,我们系统地分析了记忆行为,作为训练集大小的函数。我们还评估了不同的检索指标,以证明训练数据记忆的证据,发现MEL频谱之间的相似性在检测匹配方面比嵌入向量更强大。在分析音频潜在不同使用模型中的记忆过程中,我们还发现了AudioCaps数据库中的大量重复的音频剪辑。

拉杰马哈尔煤田土地利用/植被覆盖测绘...
2.6.1 几何校正、纠正与地理参考 2.6.2 图像增强 2.6.3 训练集选择 2.6.4 签名生成与分类 2.6.5 在 GIS 中创建/叠加矢量数据库 2.6.6 分类图像的验证 2.6.7 最终土地利用/植被覆盖图的准备 3.0 土地利用/植被覆盖制图 18-31 3.1 简介 3.2 土地利用/覆盖分类 3.3 数据分析 3.3.1 植被覆盖 3.3.2 采矿区 3.3.3 农业用地 3.3.4 荒地 3.3.5 定居点 3.3.6 水体 4.0 结论与建议 32-33
拉杰马哈尔煤田土地利用/植被覆盖测绘...
2.6.1 几何校正、纠正与地理参考 2.6.2 图像增强 2.6.3 训练集选择 2.6.4 签名生成与分类 2.6.5 在 GIS 中创建/叠加矢量数据库 2.6.6 分类图像的验证 2.6.7 最终土地利用/植被覆盖图的准备 3.0 土地利用/植被覆盖制图 18-31 3.1 简介 3.2 土地利用/覆盖分类 3.3 数据分析 3.3.1 植被覆盖 3.3.2 采矿区 3.3.3 农业用地 3.3.4 荒地 3.3.5 定居点 3.3.6 水体 4.0 结论与建议 32-33
拉杰马哈尔煤田土地利用/植被覆盖测绘...
2.6.1 几何校正、纠正与地理参考 2.6.2 图像增强 2.6.3 训练集选择 2.6.4 签名生成与分类 2.6.5 在 GIS 中创建/叠加矢量数据库 2.6.6 分类图像的验证 2.6.7 最终土地利用/植被覆盖图的准备 3.0 土地利用/植被覆盖制图 18-31 3.1 简介 3.2 土地利用/覆盖分类 3.3 数据分析 3.3.1 植被覆盖 3.3.2 采矿区 3.3.3 农业用地 3.3.4 荒地 3.3.5 定居点 3.3.6 水体 4.0 结论与建议 32-33