机构名称:
¥ 1.0
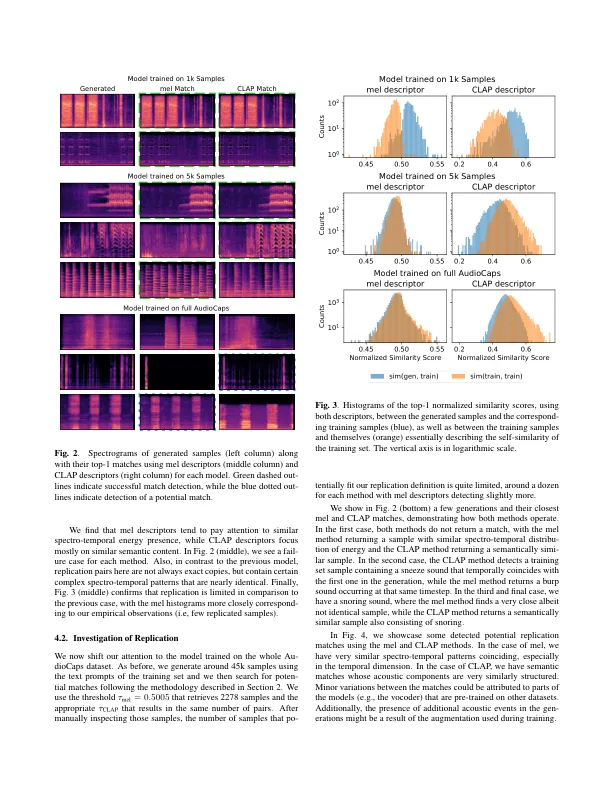
摘要引入了具有文本描述的逼真的声音剪辑能力的音频潜在不同模型,该模型有可能彻底改变我们与音频的合作方式。在这项工作中,我们初步尝试通过调查其音频输出与培训数据的比较方式来了解音频潜在不同使用模型的内部工作,这与医生如何通过听取器官的声音来听诊患者。在AudioCaps数据集中训练的文本对审计潜在分歧模型,我们系统地分析了记忆行为,作为训练集大小的函数。 我们还评估了不同的检索指标,以证明训练数据记忆的证据,发现MEL频谱之间的相似性在检测匹配方面比嵌入向量更强大。 在分析音频潜在不同使用模型中的记忆过程中,我们还发现了AudioCaps数据库中的大量重复的音频剪辑。在AudioCaps数据集中训练的文本对审计潜在分歧模型,我们系统地分析了记忆行为,作为训练集大小的函数。我们还评估了不同的检索指标,以证明训练数据记忆的证据,发现MEL频谱之间的相似性在检测匹配方面比嵌入向量更强大。在分析音频潜在不同使用模型中的记忆过程中,我们还发现了AudioCaps数据库中的大量重复的音频剪辑。
生成或复制:听觉音频潜伏...
主要关键词




相关文件推荐