XiaoMi-AI文件搜索系统
World File Search System限制
![文章标题:抗击 COVID-19:人工智能技术与挑战 作者:Nikhil Patel[1]、Sandeep Trivedi[2]、Jyotir Moy Chatterjee[3] 所属机构:毕业于杜比克大学,联系电子邮件 ID:Patelnikhilr88@gmail.com[1],IEEE 会员,毕业于 Technocrats Institute of Technology,联系电子邮件 ID:sandeep.trived.ieee@gmail.com[2],尼泊尔加德满都佛陀教育基金会[3] Orcid id:0000-0001-6221-3843[1]、0000-0002-1709-247X[2]、0000-0003-2527-916X[3] 联系电子邮件:sandeep.trived.ieee@gmail.com 许可信息:本作品已以开放获取形式发表根据 Creative Commons 署名许可 http://creativecommons.org/licenses/by/4.0/,允许在任何媒体中不受限制地使用、分发和复制,前提是正确引用原始作品。条件、使用条款和出版政策可在 https://www.scienceopen.com/ 找到。预印本声明:本文为预印本,尚未经过同行评审,正在考虑并提交给 ScienceOpen Preprints 进行公开同行评审。DOI:10.14293/S2199-1006.1.SOR-.PPVK63O.v2 预印本首次在线发布:2022 年 7 月 25 日 关键词:COVID-19、SVM、神经网络、NLP、数学建模、高斯模型、疫情防控](/simg/8/8dd469c55249d1165cc0c55c494f5b27bda7b11b.png)
文章标题:抗击 COVID-19:人工智能技术与挑战 作者:Nikhil Patel[1]、Sandeep Trivedi[2]、Jyotir Moy Chatterjee[3] 所属机构:毕业于杜比克大学,联系电子邮件 ID:Patelnikhilr88@gmail.com[1],IEEE 会员,毕业于 Technocrats Institute of Technology,联系电子邮件 ID:sandeep.trived.ieee@gmail.com[2],尼泊尔加德满都佛陀教育基金会[3] Orcid id:0000-0001-6221-3843[1]、0000-0002-1709-247X[2]、0000-0003-2527-916X[3] 联系电子邮件:sandeep.trived.ieee@gmail.com 许可信息:本作品已以开放获取形式发表根据 Creative Commons 署名许可 http://creativecommons.org/licenses/by/4.0/,允许在任何媒体中不受限制地使用、分发和复制,前提是正确引用原始作品。条件、使用条款和出版政策可在 https://www.scienceopen.com/ 找到。预印本声明:本文为预印本,尚未经过同行评审,正在考虑并提交给 ScienceOpen Preprints 进行公开同行评审。DOI:10.14293/S2199-1006.1.SOR-.PPVK63O.v2 预印本首次在线发布:2022 年 7 月 25 日 关键词:COVID-19、SVM、神经网络、NLP、数学建模、高斯模型、疫情防控
文章标题:抗击 COVID-19:人工智能技术与挑战 作者:Nikhil Patel[1]、Sandeep Trivedi[2]、Jyotir Moy Chatterjee[3] 所属机构:毕业于杜比克大学,联系电子邮件 ID:Patelnikhilr88@gmail.com[1],IEEE 会员,毕业于 Technocrats Institute of Technology,联系电子邮件 ID:sandeep.trived.ieee@gmail.com[2],尼泊尔加德满都佛陀教育基金会[3] Orcid id:0000-0001-6221-3843[1]、0000-0002-1709-247X[2]、0000-0003-2527-916X[3] 联系电子邮件:sandeep.trived.ieee@gmail.com 许可信息:本作品已以开放获取形式发表根据 Creative Commons 署名许可 http://creativecommons.org/licenses/by/4.0/,允许在任何媒体中不受限制地使用、分发和复制,前提是正确引用原始作品。条件、使用条款和出版政策可在 https://www.scienceopen.com/ 找到。预印本声明:本文为预印本,尚未经过同行评审,正在考虑并提交给 ScienceOpen Preprints 进行公开同行评审。DOI:10.14293/S2199-1006.1.SOR-.PPVK63O.v2 预印本首次在线发布:2022 年 7 月 25 日 关键词:COVID-19、SVM、神经网络、NLP、数学建模、高斯模型、疫情防控

寻找浪费的时间:attosond物理学,Petahertz光电子和量子速度限制
1。简介:attosond Electron动力学,Petahertz光电子和量子力学中的“损失时间”的问题370 2。量子力学中的严重问题:量子跳跃,不确定性关系和Pauli定理371 2.1 Bohr的理论,量子跳跃和时间测量的不确定性; 2.2 Pauli的定理3。量子力学中的时间面孔372 3.1内部和外部时间; 3.2作为量子可观察的时间和时间操作员; 3.3延迟时间4。mandelstam±tamm不确定性关系374 5。量子保真度和量子速度限制375 6。能量±时间不确定性,与时间有关的汉密尔顿人375 7。激光驱动的量子动力学376 8。不确定性关系和电子动力学的速度限制376 9。Keldysh参数和光电子的Petahertz极限378 10。mandelstam±Tamm的不确定性关系和量子进化的信息几何度量379 10.1量子演化的几何形状; 10.2量子保真度和渔民信息; 10.3不确定性关系和cram er±rao绑定11。量子速度极限的非量化性质381 12。热力学不确定性限制382 12.1信息指标和热力学不确定性; 12.2膜蛋白温度阈值的热力学极限13。结论383参考383

克隆,表征和表达的大肠杆菌中的CpG DNA甲基酶的基因中的大肠杆菌中的克隆,表征和表达。菌株MQ1(M SSSI) 一种用于检测蛋白质的酵母交配选择方案 快速板法,用于筛选透明质酸酶和软骨素硫酸硫酸酶 - 生产微生物 schizosacchomyces pombe突变体在细胞壁中有缺陷的孤立和表征(1-3)1-d-葡聚糖 数学模型用于研究遗传变异的限制性核酸内切酶 在体外向海马的层特异性纤维投影形成 回顾文章的DNA复制和损坏检查点和减数分裂细胞周期控制,并在酵母中进行酵母 DNA依赖性腺病毒基因A ... 的转录 核酸研究 kilodalton核帽结合蛋白
噬菌体FD,FL和OX174是已知的最小病毒之一。它们属于具有单链圆形DNA作为其遗传物质(1-4)的一组良好特征的副觉。他们的DNA的分子量约为2 x 106,仅包含有限数量的基因。fd和fl是丝状噬菌体,在血清学和遗传上相关。ox174是一个显然与丝状噬菌体无关的球形噬菌体。dev> deNhardt和Marvin(5)通过DNA-DNA杂交进行了表明,尽管这两种类型的噬菌体(即丝状和球形)在每种类型的DNA之间没有检测可检测的同源性,尽管在每种类型内部都有很高的同源性。最近,已经推出了一种相对较快的分馏和序列大嘧啶寡核苷酸的技术。已经确定了9-20个基碱残基的FD DNA中长嘧啶裂纹的序列(6)。在本报告中,提出了来自FL和OX174 DNA的大嘧啶产物的序列。将这些序列与先前从FD DNA获得的序列进行了比较。


执行限制 12 监测报告 2024 年 5 月
a. 建立对教职员工和学生使用技术的期望;b. 为学校系统与教职员工、学生、家庭和社区之间提供互动交流的手段;c. 禁止将技术资源用于破坏学习环境的商业、政治或不雅目的,或联邦、州或地方法律或 FCPS 政策禁止的目的;d. 使用收集、审查、传输或存储信息的方法,防止网络威胁和对所获取信息的不当访问。5. 为在教育和运营环境中使用人工智能建立适当的界限和道德准则。6. 为适当的员工提供培训、工具和可访问性资源,以支持所有学习者的教学需求和包容性。7. 确保为教职员工和学生提供培训和支持,以有效、合乎道德和安全地使用部门提供的技术工具和资源,并以数字公民的身份参与这些资源。8. 向家庭提供有关课堂和部门使用技术的目的和频率的透明信息。

2024.25 AP 和限制性核心产品表.docx
以下课程满足 4 年级科学要求,并要求完成生物学和化学:生物工程:本课程探讨分子和细胞生物学,并进行相应的实验室实验。学生将研究遗传学、生物分子结构和功能、细胞信号通路控制和蛋白质功能。解剖学和生理学:对人体结构和功能的高级、严格、深入研究。法医学:探索刑事调查的科学和技术方面。主题包括 DNA、指纹识别、血液和证据收集。NRM:水产养殖:学习出于经济、娱乐和健康目的对空气、土壤、水、土地和野生动物资源的保护、维护和良好管理。包括水产养殖、农业 STEM、创业和营销。游戏设计:本课程提供对游戏设计、动画和游戏物理的高级介绍。先决条件 - CSP、AP CSP 或 AP CS A。参见 F30 中的 Winzeler 先生。林业科学:通过课堂和实验室活动,学生将接触到多种概念,如森林的建立、树种识别、树木学基础和森林经济学。需要先修生物和化学或生物和基础农业科学。仅限 10 至 12 年级。适当和替代能源:了解不可再生能源和可再生能源之间的差异以及它们如何影响您的世界。秋季学期物理学将整合另外半个学分。学生应计划在 11 年级选修能源与电力技术以完成物理要求。仅限 9 年级机器人与机电一体化:本课程以学生在物理学中获得的基础知识为基础,并概述机器人机制、动力学和系统。需要同时或先修物理学。能源与电力技术:基于项目的课程,探讨力、功、能量和功率之间的关系以及在工业和社会中的应用。需要同时或先修物理学。
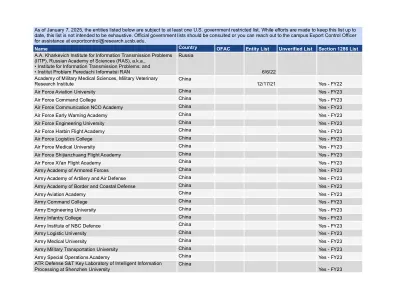
受限制的外国研究机构
名称 国家 OFAC 实体列表 未经验证的列表 第 1286 条列表 中国工程物理研究院 (CAEP) 又名 • 第九院 • 西南计算中心 • 西南应用电子研究所 • 西南化工材料研究所 • 西南电子工程研究所 • 西南环境测试研究所 • 西南火炸药化工研究所 • 西南流体物理研究所 • 西南总体设计与装配研究所 • 西南机械加工技术研究所 • 西南材料研究所 • 西南核物理与化学研究所(又名中国工程物理研究院 (CAEP) 902 研究所) • 西南特种材料研究应用研究所工厂 • 西南结构力学研究所 • 上海高功率激光实验室 • 北京应用物理与计算数学研究所 • 901 研究所

取消工作限制对寻求庇护的人的经济和社会影响
我们首先探讨了由于庇护申请人进入工作而导致的税收收入的潜在变化。我们估算了我们基于工作和退休金部(DWP)进行的建模练习的所得税和国民保险收入的增加,这些练习可以在单位成本数据库(GMCA,2023)中找到,该数据库模拟了一个接收求职者津贴(JSA)进入工作的人。我们认为,这是用于庇护申请人进入工作的最合理的情况,而不是假设所有申请人都能获得最低工资工作,并根据本文的其他论文中所做的那些工作,从这些工作中计算出所得税和国家保险收益。这是因为庇护申请人的教育和技能背景经常被发现高度多样(Holtom and Iqbal,2020年),因为那些言论和迫害的人可能是由于与他们的技能水平无关的原因而这样做。因此,在平均非工作成人进入工作之后,使用经济增长的估计是更合理的,而不是只关注最低限度。如果庇护申请人的技能水平更为多样(无论是高于英国平均水平),则在方法论上以平均水平更加强大。

数学模型用于研究遗传变异的限制性核酸内切酶
它。因此,如果像mtDNA这样的圆形DNA具有m识别(限制)位点,则该酶在消化后将其分散成M段。限制位点的数量和位置随核苷酸序列而变化。相比,两个DNA序列的相似性越高,裂解模式越接近。因此,可以通过比较限制位点的位置来估计两个同源DNA之间的核苷酸取代的数量。同样,可以从两个或分类的DNA片段的比例中估算核苷酸取代的数量。Upholt(8)研究了这两个问题,但他的锻炼并不一般,似乎涉及一些错误。fur-hoverore,upholt不关注种群中DNA序列的异质性明显高度(5)。当研究紧密相关的物种之间的遗传差异时,有必要消除这种异质性的作用。本文的目的是开发一个更严格的DNA遗传差异数学模型,并提出了一种统计方法,用于分析限制酶研究的数据。在前四个部分中,我们要么假设人群中没有多态性,要么仅考虑一对生物(个体)之间的遗传差异。在第五部分中将删除无多态性的假设。
