XiaoMi-AI文件搜索系统
World File Search SystemDeno

使用卷积神经网络
声音分类在当今世界的各个领域都有其用途。在本文中,我们将借助机器生成的声音数据来介绍声音分类技术,以检测故障机器。重点是确定音频分类方法的相关性,以通过声音检测有故障的电动机;在嘈杂和无噪声的情况下;因此,可以减少工厂和行业的人类检查要求。降低降噪在提高检测准确性方面起着重要的作用,一些研究人员通过为基准测试其模型而添加噪声来模拟数据。因此,降噪广泛用于音频分类任务。在各种可用方法中,我们实施了一种自动编码器来降低噪声。我们使用卷积神经网络对嘈杂和DeNo的数据进行了分类任务。使用自动编码器将分类的分类准确性与嘈杂的数据进行了比较。进行分类,我们使用了频谱图,MEL频率CEPSTRAL CO-EFIFIED(MFCC)和MEL光谱图图像。这些过程产生了令人鼓舞的结果,从而通过声音区分了故障的电动机。

扩散推荐模型
生成模型,例如生成对抗网络(GAN)和变异自动编码器(VAE),可广泛用于建模用户交互的生成过程。但是,它们遭受了内在的局限性,例如gan的不稳定性和VAE的限制代表能力。这种限制阻碍了复杂用户间生成过程的准确建模,例如由各种干扰因素引起的嘈杂相互作用。鉴于扩散模型(DMS)比传统生成模型的令人印象深刻的优势,我们提出了一种新颖的差异范围,以一种新颖的方式(命名为DIFFREC),以一种以deno的方式学习生成过程。 要将个性化信息保留在用户交互中,fiffrec减少了添加的噪音,并避免将用户的交互损坏为图像综合中的纯噪声。 此外,我们扩展了传统的DMS,以应对推荐中的独特挑战:大规模项目预先词典的高资源成本和用户偏好的时间变化。 为此,我们提出了diffrec的两个扩展:l-diffrec簇项目,用于尺寸压缩,并在潜在空间中进行扩散过程;基于交互时间戳编码时间信息,T-DIFFREC将用户交互重新加权。 我们在多个设置下(例如,清洁训练,嘈杂的训练和时间培训)对三个数据集进行了广泛的实验。 经验结果验证了二分法的优越性,两种扩展比竞争基准的延伸。 CCS概念鉴于扩散模型(DMS)比传统生成模型的令人印象深刻的优势,我们提出了一种新颖的差异范围,以一种新颖的方式(命名为DIFFREC),以一种以deno的方式学习生成过程。要将个性化信息保留在用户交互中,fiffrec减少了添加的噪音,并避免将用户的交互损坏为图像综合中的纯噪声。此外,我们扩展了传统的DMS,以应对推荐中的独特挑战:大规模项目预先词典的高资源成本和用户偏好的时间变化。为此,我们提出了diffrec的两个扩展:l-diffrec簇项目,用于尺寸压缩,并在潜在空间中进行扩散过程;基于交互时间戳编码时间信息,T-DIFFREC将用户交互重新加权。我们在多个设置下(例如,清洁训练,嘈杂的训练和时间培训)对三个数据集进行了广泛的实验。经验结果验证了二分法的优越性,两种扩展比竞争基准的延伸。CCS概念

燃烧和火焰-RWTH出版物
氨(NH 3)是向无碳能源系统转变的关键参与者。可靠的化学动力学模型对于基于NH 3的燃烧技术的进步至关重要。尽管存在相当多的单个模型,但它们的验证发生在不同的情况下,并且最常见于有限的条件集,主要基于与实验数据的图形比较。这项研究对纯NH 3和NH 3 /H 2混合物的广泛实验数据库进行了16个最新模型的全面定量评估。这种定量评估的基础是在平滑插值实验和相应的预测曲线之间计算出的相似性评分。评估利用了文献中可用的广泛实验数据集,并根据不同的目标数量进行分类,包括物种浓度,点火延迟时间和层流燃烧速度。根据热解,高温,中等和低温氧化以及热DENO X过程,将物种浓度评估进一步分类。全面的评估揭示了模型的性能之间的显着差异,有些模型比其他模型表现出更好的一致性。均未在所有条件下达成令人满意的一致性,强调了进一步改进的必要性。模型性能在不同的类别下进行了审查,以检查关键动力学参数,并提供了潜在改进的见解。在更广泛的背景下,整合全面的NH 3 /H 2模型需要从各种动力学建模,实验和理论计算研究中融合见解。这项工作是朝这个方向朝着这一方向发展的基础步骤,这有助于不断努力地完善对NH 3燃烧的理解。

红色强调:使用扩散模型进行傅立叶相试验
摘要 - 书中检索是一个代表性的反问题,其中仅使用信号的傅立叶变换的测量幅度才能恢复信号。深度学习的算法比标准算法更令人满意地重建,例如交替的投影处理和凸放松方法。但是,他们通常无法重建细节或纹理。最近,已经利用扩散模型来解决傅立叶相检索问题。这些算法提供了现实的结果,但是由于生成模型的性质,可以在重建中显示实际图像中的不存在细节。为了应对这些问题,我们提出了一种新型算法,称为“红色强调”,结合了差异扩散采样AP-ap-aper和相位检索的凸松弛方法。尤其是,用于相位检索的经典优化问题被用作额外的正则化,以在变化采样过程中正确重建相位信息。我们的实验结果证实,与现有的傅立叶相检索算法相比,所提出的红色强调可提供定性和定量改善的性能。索引术语 - 较高的相位检索,扩散模型,通过deno的调节,凸松弛
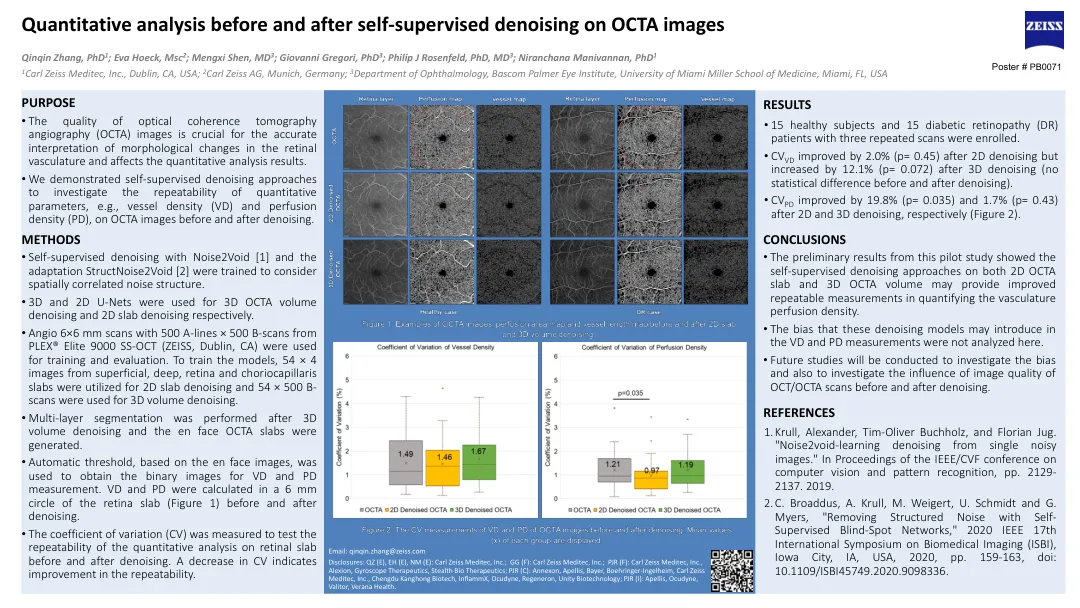
在八颗图像上进行自我监督后和之后的定量分析
•光学相干断层扫描(OCTA)图像的质量对于准确解释视网膜脉管形态变化至关重要,并影响定量分析结果。•我们在deno的八八图图像上展示了研究定量参数的重复性,例如血管密度(VD)和灌注密度(PD)的重复性。方法•对噪声2Void [1]和适应性构造noise2Void [2]进行自我监督的脱氧,训练以考虑空间相关的噪声结构。•3D和2D U-NET分别用于3D八八个体积和2D平板Denoising。•使用Plex®Elite9000 SS-OCT(CA Zeiss,Dublin,CA)的500 A-线×500 B型扫描血管扫描。用于训练模型,将来自浅表,深,视网膜和绒毛膜的54×4图像用于2D平板降级,并使用54×500 b-扫描用于3D体积。•在3D体积降解后进行多层分割,并产生EN脸部八板。•基于EN脸部图像的自动阈值用于获取用于VD和PD测量的二进制图像。vd和pd是在降解前后在视网膜平板的6 mm圆(图1)中计算的。•测量变异系数(CV),以测试降解前后视网膜平板上定量分析的重复性。CV的减少表示可重复性的提高。

基于特征表示学习和深度神经网络
抽象背景:药物目标相互作用预测对于缩小候选药物范围的范围至关重要,因此是药物发现中的至关重要的一步。由于生化实验的特殊性,新药的发展不仅昂贵,而且耗时。因此,药物靶标相互作用的计算预测已成为药物发现过程中的重要方法,旨在大大减少实验成本和时间。结果:我们提出了一种基于特征表示学习和名为DTI-CNN的深神经网络的基于学习的方法,以预测药物目标相互作用。我们首先使用Jaccard相似性系数并重新启动随机行走模型,从异质网络中提取药物和蛋白质的相关特征。然后,我们采用deno的自动编码器模型来降低维度并确定基本功能。第三,根据从上一步获得的特征,我们构建了一个卷积神经网络模型,以预测药物与蛋白质之间的相互作用。评估结果表明,DTI-CNN的平均AUROC得分和AUPR得分为0.9416和0.9499,其性能比其他三种现有的最新方法更好。结论:所有实验结果表明,DTI-CNN的性能要比现有方法中的三种方法更好,并且所提出的方法的设计适当设计。

评估使用扩散降解概率模型
生成的AI模型,例如稳定的扩散,DALL-E和MIDJOURNEY,最近引起了广泛的关注,因为它们可以通过学习复杂,高维图像数据的分布来产生高质量的合成图像。这些模型现在正在适用于医学和神经影像学数据,其中基于AI的任务(例如诊断分类和预测性建模)通常使用深度学习方法,例如卷积神经网络(CNNS)和视觉变形金刚(VITS)(VITS),并具有可解释性的增强性。在我们的研究中,我们训练了潜在扩散模型(LDM)和deno的扩散概率模型(DDPM),专门生成合成扩散张量张量成像(DTI)地图。我们开发了通过对实际3D DTI扫描进行训练以及使用最大平均差异(MMD)和多规模结构相似性指数(MS-SSSIM)评估合成数据的现实主义和多样性来生成平均扩散率的合成DTI图。我们还通过培训真实和合成DTI的组合来评估基于3D CNN的性别分类器的性能,以检查在培训期间添加合成扫描时的性能是否有所提高,作为数据增强形式。我们的方法有效地产生了现实和多样化的合成数据,有助于为神经科学研究和临床诊断创建可解释的AI驱动图。

反事实解释的生成模型
反事实说明通过回答“如果”方案,阐明了复杂的系统决策,表明最小输入变化如何导致不同的结果[1]。这对于机器学习(ML)至关重要,其中了解模型的理由与决策本身一样重要[2]。通过检查假设的替代方法,反事实解释使ML模型的决策更加透明和可理解。尽管对反事实解释的兴趣越来越大,但文献上存在有关用于创建它们的生成方法的差距。变异自动编码器(VAES)[3],生成对抗网络(GAN)[4]和deno的扩散概率模型(DDPMS)[5]非常值得注意,尤其是生成反事实,尤其是对于复杂的数据模态,例如图像等复杂的数据模态,在其中调整了不隔离的功能。但是,现有的调查通常忽略生成方面或高维数据方案[6,7,8]。我们的工作通过着重于复杂数据中的反事实解释的生成模型来解决这一差距,从而对其能力和局限性提供了全面的理解。在本文中,我们探讨了反事实解释的生成模型的常见用例,并突出了主要的挑战。我们通过其生成技术对方法进行分类,并检查对标准过程的修改,以满足反事实要求。我们的讨论旨在通过确定反事实解释中推进生成方法的关键挑战和潜在方向来刺激进一步的研究。while

未经训练的感知损失,用于MR图像中线状结构的图像降级
在获取磁共振(MR)图像中,较短的扫描时间会导致更高的图像噪声。因此,使用深度学习方法自动图像降解是高度兴趣的。在这项工作中,我们集中于包含线状结构(例如根或容器)的MR图像的图像。特别是,我们研究了这些数据集的特殊特征(连接性,稀疏性)是否受益于使用特殊损失功能进行网络培训。我们特此通过比较损失函数中未经训练的网络的特征图将感知损失转换为3D数据。我们测试了3D图像降级的未经训练感知损失(UPL)的表现,使MR图像散布脑血管(MR血管造影-MRA)和土壤中植物根的图像。在这项研究中,包括536个MR在土壤中的植物根和450个MRA图像的图像。植物根数据集分为380、80和76个图像,用于培训,验证和测试。MRA数据集分为300、50和100张图像,用于培训,验证和测试。我们研究了各种UPL特征的影响,例如重量初始化,网络深度,内核大小以及汇总结果对结果的影响。,我们使用评估METIC,例如结构相似性指数(SSIM),测试了四个里奇亚噪声水平(1%,5%,10%和20%)上UPL损失的性能。我们的结果与不同网络体系结构的常用L1损失进行了比较。我们观察到,我们的UPL优于常规损失函数,例如L1损失或基于结构相似性指数(SSIM)的损失。对于MRA图像,UPL导致SSIM值为0.93,而L1和SSIM损耗分别导致SSIM值分别为0.81和0.88。UPL网络的初始化并不重要(例如对于MR根图像,SSIM差异为0.01,在初始化过程中发生,而网络深度和合并操作会影响DeNo的性能稍大(5卷积层的SSIM为0.83,而核尺寸为0.86,而5卷积层的0.86 vs. 0.86对于根数据集对5卷积层和5卷积层和内核尺寸5)。我们还发现,与使用诸如VGG这样的大型网络(例如SSIM值为0.93和0.90)。总而言之,我们证明了两个数据集,所有噪声水平和三个网络体系结构的损失表现出色。结论,对于图像

在Bbox之外思考:无约束的生成对象合成
生成的AI模型和社交媒体的兴起引发了图像编辑技术的广泛兴趣。现实且可控的图像编辑现在对于内容创建,营销和娱乐等应用是必不可少的。在大多数编辑过程中的一个关键步骤是图像合成,无缝地将前景对象与背景图像集成。然而,图像构成的挑战带来了许多挑战,包括结合新的阴影或反射,照明错位,不自然的前景对象边界,并确保对象的姿势,位置和刻度在语义上是连贯的。以前关于图像合成的作品[5,30,32,59,61]专注于特定的子任务,例如图像融合,协调,对象放置或阴影一代。更多的方法[9,36,50,62]表明,可以使用扩散模型同时处理一些单独的组合方面(即,颜色协调,重新定位,对象几何调整和阴影/反射生成)[18,46]。这种方法通常以自我监督的方式进行训练,掩盖地面真相图像中的对象,并将蒙版的图像用作输入[9,62],或者在反向扩散过程中仅在掩模区域内deno [9,50]。因此,在本文中,我们提出了一个生成图像合成模型,该模型超出了掩码,甚至使用空掩码,在这种情况下,模型将自然位置在适合尺度的自然位置中自动合成对象。我们的模型是图像合成的第一个端到端解决方案,同时解决了图像合成的所有子任务,包括对象放置。因此,在推理过程中需要掩模作为输入,导致了几个限制:(i)对普通用户进行精确掩码可能是不乏味的,并且可能会导致不自然的复合图像,具体取决于输入蒙版的位置,规模和形状; (ii)掩模区域限制了生成,其训练数据不考虑对象效应,从而限制了合成适当效果的能力,例如长阴影和反射; (iii)物体附近的背景区域往往与原始背景不一致,因为该模型在面具覆盖的情况下不会看到这些区域。为了实现此目的,我们首先使用图像介绍来创建包括图像三重态的训练数据(前景对象,完整的背景图像和