XiaoMi-AI文件搜索系统
World File Search SystemDense

绕过尖峰排序:使用密集多电极探针的尖峰定位进行基于密度的解码
神经解码及其在脑机接口 (BCI) 中的应用对于理解神经活动和行为之间的关联至关重要。许多解码方法的先决条件是尖峰分类,即将动作电位 (尖峰) 分配给单个神经元。然而,当前的尖峰分类算法可能不准确,并且不能正确模拟尖峰分配的不确定性,因此丢弃了可能提高解码性能的信息。高密度探针 (例如 Neuropixels) 和计算方法的最新进展现在允许从未排序的数据中提取一组丰富的尖峰特征;这些特征反过来可用于直接解码行为相关性。为此,我们提出了一种无尖峰分类的解码方法,该方法直接使用对尖峰分配的不确定性进行编码的高斯混合 (MoG) 来建模提取的尖峰特征的分布,而不旨在明确解决尖峰聚类问题。我们允许 MoG 的混合比例随时间变化以响应行为,并开发变分推理方法来拟合得到的模型并执行解码。我们用来自不同动物和探针几何的大量记录对我们的方法进行了基准测试,表明我们提出的解码器可以始终优于基于阈值(即多单元活动)和尖峰分类的当前方法。开源代码可在 https://github.com/yzhang511/density_decoding 上找到。
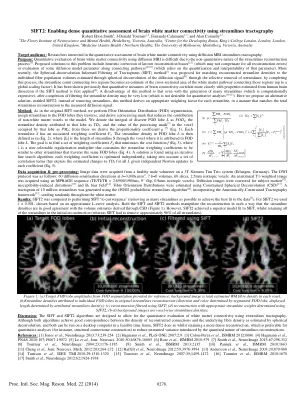
SIFT2:利用流线纤维束成像技术对大脑白质连接进行密集定量评估
目标受众:对使用扩散 MRI 流线纤维束成像定量评估大脑白质连接感兴趣的研究人员。目的:由于流线重建过程的非定量性质 [1],使用扩散 MRI 定量评估大脑白质连接非常困难。针对该问题提出的解决方案包括启发式校正已知的重建偏差 [2,3](可能无法补偿所有重建误差)或评估连接路径上某些扩散模型参数 [4,5,6](依赖于该参数的量化和可解释性)。最近,提出了球面反卷积信息纤维束成像滤波 (SIFT) 方法 [7],通过选择性去除流线,将重建的流线密度与通过扩散信号球面反卷积估计的单个纤维群体积 [8] 进行匹配;完成此过程后,连接两个区域的流线计数变为连接这些区域的白质通路横截面积的估计值(最高可达全局缩放因子)。之前已证明,如果首先应用 SIFT 方法 [9],大脑连接的定量测量与从人脑解剖估计的特性会更加密切相关。这种方法的缺点是,即使生成了许多流线(计算成本高昂),完成过滤后,流线密度可能非常低(这对于定量分析来说是不可取的 [10,11])。在这里,我们提出了一种替代解决方案,称为 SIFT2:此方法不是去除流线,而是为每条流线得出合适的加权因子,以使总流线重建与测量的扩散信号相匹配。方法:与原始 SIFT 方法一样,我们执行纤维方向分布 (FOD) 分割,将流线分配给它们穿过的 FOD 叶,并得出一个处理掩模,以减少非白质体素对模型的贡献。我们将离散 FOD 叶 L 的积分表示为 FOD L ,将归因于该叶的流线密度表示为 TD L ,将处理掩模 [7] 在该叶所占体素中的值表示为 PM L ;从这些中我们得出比例系数 μ [7](等式 1)。每条流线 S 都有一个关联的加权系数 FS 。FOD 叶 L 中的流线密度定义为(等式 2),其中 | SL | 是流线 S 穿过归因于 FOD 叶 L 的体素的长度。目标是找到一组加权系数 FS ,以最小化成本函数 f(等式 3),其中 λ 是用户可选择的正则化乘数,它将流线加权系数约束为与穿过相同 FOD 叶的其他流线相似(等式 4)。使用迭代线搜索算法可以找到解决方案:每个加权系数都经过独立优化,同时考虑一组相关项,这些相关项表示在对每个系数进行独立牛顿更新的情况下所有 L 的 TD L 的估计变化(等式 5)。数据采集和预处理:图像数据是从健康男性志愿者的 3T Siemens Tim Trio 系统(德国埃尔朗根)上采集的。DWI 协议如下:60 个弥散敏化方向,b =3,000s.mm -2,7 b =0 体积,60 个切片,2.5mm 各向同性体素。使用 MPRAGE 序列(TE/TI/TR = 2.6/900/1900ms,9° 翻转,0.9mm 各向同性体素)获取解剖 T1 加权图像。对弥散图像进行了校正以适应受试者运动 [12]、磁化率引起的扭曲 [13] 和 B 1 偏置场 [14]。使用约束球面反卷积 (CSD) [15] 估计纤维取向分布。使用 iFOD2 概率流线算法 [16] 生成了 1000 万条流线的纤维束图,该算法结合了解剖约束纤维束成像框架 [17] ,随机分布在整个白质中。结果:将 SIFT2 与执行 SIFT“收敛”(移除尽可能多的流线以实现与数据的最佳拟合 [7] )进行了比较。对于 SIFT2,我们使用了 λ = 0.001,这是基于近似 L 曲线分析选择的。SIFT 和 SIFT2 方法都以这样一种方式操纵重建,使得流线密度与通过 CSD 得出的体积估计值高度一致(图 1)。然而,SIFT2 实现了比 SIFT 更优秀的模型拟合,同时保留了初始重建中的所有流线(而 SIFT 必须去除大约 96% 的流线)。根据近似 L 曲线分析选择。SIFT 和 SIFT2 方法都以流线密度与通过 CSD 得出的体积估计值高度一致的方式操纵重建(图 1)。然而,SIFT2 实现了比 SIFT 更好的模型拟合,同时保留了初始重建中的所有流线(而 SIFT 必须删除大约 96% 的所有流线)。根据近似 L 曲线分析选择。SIFT 和 SIFT2 方法都以流线密度与通过 CSD 得出的体积估计值高度一致的方式操纵重建(图 1)。然而,SIFT2 实现了比 SIFT 更好的模型拟合,同时保留了初始重建中的所有流线(而 SIFT 必须删除大约 96% 的所有流线)。

针对SI的密集垂直III – V纳米线的定向自组装及其对栅极全能沉积的影响
由于材料之间的晶格错误匹配,SI底物上窄带III – V材料的大规模整合仍然是一个挑战。[1,2]纳米级开口的外延生长降低了源自III – V/SI界面以传播到活动设备的缺陷的可能性,并证明了表现优势。[3]其他剩余的挑战是模式技术,[4]小型大小,高模式密度和经济高效的处理具有吸引力。高密度模式的一种可能的光刻溶液是块共聚物(BCP)光刻。[5–7]该技术依赖于自组装,这意味着该分辨率不是由clas的局限性设置的,例如辐射波长或接近度效应。[8,9] BCP光刻分辨率极限主要是由其总体聚合度和组成块不信用的程度设定的。[10]该技术是低成本的,允许在高图案密度下转移图案转移 - 至少至12 nm螺距。[11,12]一种特殊的材料,聚(苯乙烯) - 块-poly(4-乙烯基吡啶)(PS-B -P4VP),是所谓的高χBCP,即块之间具有很高的缺失性,这使自组件能够最低10 nm lamelar powd。[13]通过控制聚合物分子量,聚合物块的不混溶,聚合物块的体积分数,底物表面能和表面形象,如果向聚合物链提供足够的迁移率,则可以实现自组装。[14]可以通过添加热量来提供所需的迁移率,[15]通过介入聚合物可溶性蒸气,[16,17]或两者的组合。[18]许多设备应用程序受益于模式对齐,为此,可以使用定向自组装(DSA)来控制模式的定位。[5,6,19–22]然后,通常使用电阻的电子或光子暴露创建引导模式,并且指导是通过改变表面能量或创建不同地形来完成的。[19]

现代地面通信系统的密集小型卫星网络:优势、基础设施和技术
摘要 — 低地球轨道 (LEO) 上的密集小型卫星网络 (DSSN) 可使多种移动地面通信系统 (MTCS) 受益。然而,只有通过仔细考虑 DSSN 基础设施并确定合适的 DSSN 技术才能实现潜在优势。在本文中,我们讨论了 DSSN 基础设施的几个组成部分,包括卫星编队、轨道路径、卫星间通信 (ISC) 链路以及从源到目的地的数据传输通信架构。我们还回顾了 DSSN 的重要技术以及在 DSSN 中使用这些技术所面临的挑战。本文还确定了几个开放的研究方向,以增强 DSSN 对 MTCS 的优势。还包括一个案例研究,展示了 DSSN 在 MTCS 中的集成优势。

orca-a*:一种混合相互碰撞的回避和路线计划算法在密集的城市地区
摘要 - 无人机(或无人空中系统)的快速发展及其在城市地区的潜在部署带来了许多安全问题。一定程度的自动化对于确保在城市环境中安全有效执行的UAS任务很可能是必要的。在大量不合作,非交流的UA会在密集的城市地区飞行,自然而然地想到的分散和自动方法。在这种方法中,每个代理都会在建筑物之间导航,同时避免其他流量。orca(最佳的相互碰撞避免)是一种最新的机器人碰撞避免使用方法,可以用作检测并避免在板上UAS上进行逻辑。最初是为自动机器人的2D运动而设计的,需要进行一些适应才能以应用于城市环境中的飞行物体。特别是,ORCA是一种短期避免碰撞,不是为复杂的城市环境中的路径规划而设计的。在这项研究中,我们引入了一种混合方法,将Orca与A ∗路径平面算法相结合,并表明Orca- A ∗

茂密森林覆盖中机载激光扫描 (ALS) 数据的地表插值精度
摘要:地表数字模型在林业中具有许多潜在应用。如今,光检测和测距 (LiDAR) 是收集形态数据的主要来源之一。通过激光扫描获得的点云用于通过插值对地表进行建模,该过程受到各种误差的影响。使用 LiDAR 数据收集地表数据用于林业应用是一个具有挑战性的场景,因为森林植被的存在会阻碍激光脉冲到达地面的能力。因此,地面观测的密度将降低且不均匀(因为它受到冠层密度变化的影响)。此外,森林地区通常位于山区,在这种情况下,地表的插值更具挑战性。本文对九种算法的插值精度进行了比较分析,这些算法用于在茂密森林植被覆盖的山区地形中从机载激光扫描 (ALS) 数据生成数字地形模型。对于大多数算法,我们发现在一般精度方面具有相似的性能,RMSE 值在 0.11 到 0.28 m 之间(当模型分辨率设置为 0.5 m 时)。其中五种算法(自然邻域、Delauney 三角剖分、多级 B 样条、薄板样条和 TIN 薄板样条)对超过 90% 的验证点的垂直误差小于 0.20 m。同时,对于大多数算法,主要垂直误差(超过 1 m)与不到 0.05% 的验证点相关。数字地形模型 (DTM) 分辨率、地面坡度和点云密度影响地面模型的质量,而对于冠层密度,我们发现与插值 DTM 的质量之间的联系不太明显。

MRI脑肿瘤分割,使用具有密集编码器块和残留解码器块的3D U-NET
磁共振成像(MRI)自动脑肿瘤分割的主要任务是自动分割脑肿瘤水肿,腹部水肿,内窥镜核心,增强肿瘤核心和3D MR图像的非增强肿瘤核心。由于脑肿瘤的位置,大小,形状和强度差异很大,因此很难自动分割这些脑肿瘤区域。在本文中,通过结合Densenet和Resnet的优点,我们提出了一个新的3D U-NET,具有密集的编码器块和残留的解码器块。我们在编码器部分中使用了密集的块和解码器部分中的残留块。输出特征图的数量随编码器的收缩路径中的网络层增加而增加,这与密集块的特征一致。使用密集的块可以减少网络参数的数量,加深网络层,增强特征传播,减轻消失的梯度和扩大接收场。在解码器中使用残差块来替换原始U-NET的卷积神经块,这使网络性能更好。我们提出的方法在BRATS2019培训和验证数据集上进行了培训和验证。我们在BRATS2019验证数据集上分别获得了整个肿瘤,肿瘤核心和增强肿瘤核心的骰子得分,分别为0.901、0.815和0.766。我们的方法比原始的3D U-NET具有更好的性能。我们的实验结果表明,与某些最新方法相比,我们的方法是一种竞争性的自动脑肿瘤分割方法。
文章 茂密森林覆盖下机载激光扫描 (ALS) 数据的地面插值精度
摘要:地表数字模型在林业中具有许多潜在应用。如今,光检测和测距 (LiDAR) 是收集形态数据的主要来源之一。通过激光扫描获得的点云用于通过插值对地表进行建模,该过程受到各种误差的影响。使用 LiDAR 数据收集地表数据用于林业应用是一个具有挑战性的场景,因为森林植被的存在会阻碍激光脉冲到达地面的能力。因此,地面观测的密度将降低且不均匀(因为它受到冠层密度变化的影响)。此外,森林地区通常位于山区,在这种情况下,地表的插值更具挑战性。本文对九种算法的插值精度进行了比较分析,这些算法用于在茂密森林植被覆盖的山区地形中从机载激光扫描 (ALS) 数据生成数字地形模型。对于大多数算法,我们发现总体精度方面的性能相似,RMSE 值在 0.11 到 0.28 m 之间(当模型分辨率设置为 0.5 m 时)。其中五种算法(自然邻域、Delauney 三角剖分、多层 B 样条、薄板样条和 TIN 薄板样条)对超过 90% 的验证点的垂直误差小于 0.20 m。同时,对于大多数算法,主要垂直误差(超过 1 m)与不到 0.05% 的验证点相关。数字地形模型 (DTM) 分辨率、地面坡度和点云密度会影响地面模型的质量,而对于冠层密度,我们发现与插值 DTM 的质量之间的联系不太明显。
文章 茂密森林覆盖区机载激光扫描 (ALS) 数据地表插值的精度
摘要:地表数字模型在林业中具有许多潜在应用。如今,光探测和测距 (LiDAR) 是收集形态数据的主要来源之一。通过激光扫描获得的点云用于通过插值对地表进行建模,这一过程受到各种误差的影响。使用 LiDAR 数据收集地表数据用于林业应用是一个具有挑战性的场景,因为森林植被的存在会阻碍激光脉冲到达地面的能力。因此,地面观测的密度将降低且不均匀(因为它受到冠层密度变化的影响)。此外,森林地区通常位于山区,在这种情况下,地表的插值更具挑战性。在本文中,我们对九种算法的插值精度进行了比较分析,这些算法用于在茂密的森林植被覆盖的山区地形中从机载激光扫描 (ALS) 数据生成数字地形模型。对于大多数算法,我们发现在总体精度方面性能相似,RMSE 值在 0.11 到 0.28 米之间(当模型分辨率设置为 0.5 米时)。其中五种算法(自然邻域、Delauney 三角剖分、多层 B 样条、薄板样条和基于 TIN 的薄板样条)对于超过 90% 的验证点具有小于 0.20 米的垂直误差。同时,对于大多数算法,主要垂直误差(超过 1 米)与不到 0.05% 的验证点相关。数字地形模型 (DTM) 分辨率、地面坡度和点云密度影响地面模型的质量,而对于冠层密度,我们发现与插值 DTM 的质量之间的联系不太显著。
文章 茂密森林覆盖区机载激光扫描 (ALS) 数据地表插值的精度
摘要:地表数字模型在林业中具有许多潜在应用。如今,光探测和测距 (LiDAR) 是收集形态数据的主要来源之一。通过激光扫描获得的点云用于通过插值对地表进行建模,这一过程受到各种误差的影响。使用 LiDAR 数据收集地表数据用于林业应用是一个具有挑战性的场景,因为森林植被的存在会阻碍激光脉冲到达地面的能力。因此,地面观测的密度将降低且不均匀(因为它受到冠层密度变化的影响)。此外,森林地区通常位于山区,在这种情况下,地表的插值更具挑战性。在本文中,我们对九种算法的插值精度进行了比较分析,这些算法用于在茂密的森林植被覆盖的山区地形中从机载激光扫描 (ALS) 数据生成数字地形模型。对于大多数算法,我们发现在总体精度方面性能相似,RMSE 值在 0.11 到 0.28 米之间(当模型分辨率设置为 0.5 米时)。其中五种算法(自然邻域、Delauney 三角剖分、多层 B 样条、薄板样条和基于 TIN 的薄板样条)对于超过 90% 的验证点具有小于 0.20 米的垂直误差。同时,对于大多数算法,主要垂直误差(超过 1 米)与不到 0.05% 的验证点相关。数字地形模型 (DTM) 分辨率、地面坡度和点云密度影响地面模型的质量,而对于冠层密度,我们发现与插值 DTM 的质量之间的联系不太显著。