XiaoMi-AI文件搜索系统
World File Search SystemDistributions


分布服务指南
不时地从外部来源通知和其他文件(包括公司行动信息以及有关金融资产的通信)收到。尽管DTC可以确定此类文档和通信,或者从其中提取(“信息”)为参与者和其他授权用户提供,但不得义务也不会这样做,或者一旦这样做,DTC应持续有义务提供某种类型的可用信息。信息不是由DTC独立验证的,并且不打算替代从适当的专业顾问那里获得建议。因此,建议参与者和其他授权用户独立获取和监视信息。此外,根据DTC的规则和程序或其他适用的合同义务,参与者和其他授权用户提供的信息中没有任何包含的信息,以检查参与者日常活动声明的准确性,以及从DTC收到的所有其他声明和报告,并收到了DTC并通知任何差异的DTC。dtc不代表提供给参与者和其他授权用户的任何特定目的(上面定义的)的准确性,充分性,及时性,完整性或适应性,并提供了AS-IS。DTC对与此类信息(或提供此类信息的法案或过程)相关的任何损失不承担任何责任,而不是直接或间接来自错误,错误或遗漏,而不是直接由DTC的严重过失或故意的不当行为造成的。此外,此类信息可能会更改。参与者和其他授权用户应获得,监视和审查与其活动有关的任何可用文档,并应验证从DTC收到的独立信息。

CES 分布的 Fisher-Rao 几何
陈述了这两点,我们最后可以注意到,获得的 Fisher 信息度量 ⟨· , ·⟩ FIM 횺 随 횺 平滑变化。这使得从统计模型过渡到黎曼几何成为可能:微分几何的一个分支,研究具有光滑局部内积(称为黎曼度量)的光滑流形。这种框架确实适用于参数统计模型,因为它使我们能够研究配备 Fisher 信息度量的参数空间的几何形状。由此产生的黎曼几何通常称为 Fisher-Rao 信息几何。回到我们的中心例子,我们已经介绍了足够多的元素来明确本章的标题“CES 分布的 Fisher-Rao 几何”更准确地说是“由中心圆形复椭圆对称分布的 Fisher 信息度量引起的 Hermitian 正定矩阵(协方差矩阵)的黎曼几何”,这将在下一节中研究。

大质量 QED2 中的准部分子分布
我们通过精确对角化分析了大质量二维量子电动力学 (QED2) 中最轻的 η 0 介子的准部分子分布。哈密顿量和增强算子被映射到具有开放边界条件的空间晶格中的自旋量子比特上。精确对角化中的最低激发态显示为在强耦合下的异常 η 0 态和弱耦合下的非异常重介子之间连续插入,并在临界点处出现尖点。增强的 η 0 态遵循相对论运动学,但在光子极限方面存在较大偏差。在强耦合和弱耦合下,对 η 0 态的空间准部分子分布函数和振幅进行了数值计算,以增加速度,并与精确的光前沿结果进行了比较。增强形式的空间部分子分布的数值结果与在最低 Fock 空间近似中得出的光子部分子分布的逆傅里叶变换相当。我们的分析指出了当前部分子分布的格子程序面临的一些局限性。

算法偏差评估的Abroca分布
[1] Ryan S. Baker。2024。大数据和教育(第8版)。宾夕法尼亚州费城宾夕法尼亚大学。 [2] Ryan S. Baker和Aaron Hawn。2022。教育算法偏见。国际人工智能杂志教育杂志(2022),1-41。[3] Solon Barocas,Andrew D Selbst和Manish Raghavan。2020。反事实解释和主要原因背后的隐藏假设。在2020年公平,问责制和透明度会议的会议记录中。80–89。[4] Alex J Bowers和Xiaoliang Zhou。2019。曲线下的接收器操作特征(ROC)区域(AUC):一种评估教育结果预测指标准确性的诊断措施。受风险的学生教育杂志(JESPAR)24,1(2019),20-46。[5] Oscar Blessed Deho,Lin Liu,Jiuyong Li,Jixue Liu,Chen Zhan和Srecko Joksimovic。2024。过去!=未来:评估数据集漂移对学习分析模型的公平性的影响。IEEE学习技术交易(2024)。[6] Olga V Demler,Michael J Pencina和Ralph B D'Agostino Sr. 2012。滥用DELONG测试以比较嵌套模型的AUC。医学中的统计数据31,23(2012),2577–2587。[7] Batya Friedman和Helen Nissenbaum。1996。计算机系统中的偏差。信息系统(TOIS)的ACM交易14,3(1996),330–347。[8]乔什·加德纳,克里斯托弗·布鲁克斯和瑞安·贝克。2019。225–234。通过切片分析评估预测学生模型的公平性。在第9届学习分析与知识国际会议论文集。[9]LászlóA Jeni,Jeffrey F Cohn和Fernando de la Torre。2013。面对不平衡的数据:使用性能指标的建议。在2013年,俄亥俄州情感计算和智能互动会议上。IEEE,245–251。 [10] Weijie Jiang和Zachary a Pardos。 2021。 在学生等级预测中迈向公平和算法公平。 在2021年AAAI/ACM关于AI,伦理和社会的会议上。 608–617。 [11]RenéFKizilcec和Hansol Lee。 2022。 教育算法公平。 在教育中人工智能的伦理学中。 Routledge,174–202。 [12]JesúsFSalgado。 2018。 将正常曲线(AUC)下的面积转换为Cohen的D,Pearson的R PB,Ordds-Ratio和自然对数赔率比率:两个转换表。 欧洲心理学杂志适用于法律环境10,1(2018),35-47。 [13] Lele Sha,Mladen Rakovic,Alexander Whitelock-Wainwright,David Carroll,Victoria M Yew,Dragan Gasevic和Guanliang Chen。 2021。 在自动教育论坛帖子中评估算法公平性。 教育中的人工智能:第22届国际会议,AIED 2021,荷兰乌得勒支,6月14日至18日,2021年,第I部分。 Springer,381–394。 2024。 2023。 2018。IEEE,245–251。[10] Weijie Jiang和Zachary a Pardos。2021。在学生等级预测中迈向公平和算法公平。在2021年AAAI/ACM关于AI,伦理和社会的会议上。608–617。[11]RenéFKizilcec和Hansol Lee。2022。教育算法公平。在教育中人工智能的伦理学中。Routledge,174–202。[12]JesúsFSalgado。2018。将正常曲线(AUC)下的面积转换为Cohen的D,Pearson的R PB,Ordds-Ratio和自然对数赔率比率:两个转换表。欧洲心理学杂志适用于法律环境10,1(2018),35-47。[13] Lele Sha,Mladen Rakovic,Alexander Whitelock-Wainwright,David Carroll,Victoria M Yew,Dragan Gasevic和Guanliang Chen。2021。在自动教育论坛帖子中评估算法公平性。教育中的人工智能:第22届国际会议,AIED 2021,荷兰乌得勒支,6月14日至18日,2021年,第I部分。Springer,381–394。2024。2023。2018。[14]Valdemaršvábensk`Y,MélinaVerger,Maria Mercedes T Rodrigo,Clarence James G Monterozo,Ryan S Baker,Miguel Zenon Nicanor LeriasSaavedra,SébastienLallé和Atsushi Shimada。在预测菲律宾学生的学习成绩的模型中评估算法偏见。在第17届国际教育数据挖掘会议上(EDM 2024)。[15]MélinaVerger,SébastienLallé,FrançoisBouchet和Vanda Luengo。您的模型是“ MADD”吗?一种新型指标,用于评估预测学生模型的算法公平性。在第16届国际教育数据挖掘会议上(EDM 2023)。[16] Sahil Verma和Julia Rubin。公平定义解释了。在国际软件公平研讨会的会议记录中。1-7。[17] Zhen Xu,Joseph Olson,Nicole Pochinki,Zhijian Zheng和Renzhe Yu。2024。上下文很重要,但是如何?课程级别的性能和公平转移的相关性在预测模型转移中。在第14届学习分析和知识会议论文集。713–724。[18] Andres Felipe Zambrano,Jiayi Zhang和Ryan S Baker。2024。在贝叶斯知识追踪和粗心大意探测器上研究算法偏见。在第14届学习分析和知识会议论文集。349–359。

利用相空间分布矩阵探索非经典性
我们设计了一种通过相空间分布相关性来认证非经典特征的方法,该方法统一了准概率和相关函数矩阵的概念。我们的方法补充并扩展了基于切比雪夫积分不等式的最新结果 [Phys. Rev. Lett. 124, 133601 (2020)]。这里开发的方法在相空间中的任意点关联任意相空间函数,包括多模场景和高阶相关性。此外,我们的方法提供了必要和充分的非经典性标准,适用于 s 参数化函数以外的相空间函数,并且可以在实验中使用。为了证明我们技术的强大功能,我们仅使用二阶相关和 Husimi 函数来验证离散和连续变量、单模和多模以及纯态和混合态的量子特性,这些函数始终类似于经典概率分布。此外,我们还研究了我们方法的非线性推广。因此,我们设计了一个通用且广泛适用的框架,以揭示相空间分布矩阵中的量子特性。
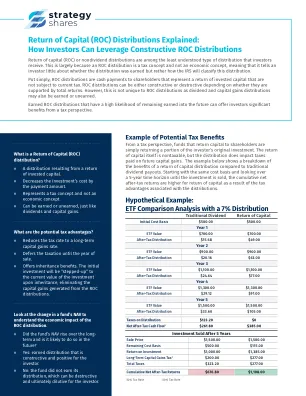
资本回报(ROC)分布解释了
对于一些希望向股东进行固定每月分配的资金,使用ROC分布可能是确保持续支出的有效策略。如果基金无法产生足够的收入和收益来支持全月付款,则可以进行ROC分配以弥补任何短缺。例如,一些封闭式资金使用资本分配的回报,同时经历了NAVS下降并在售后计划中发行新股票。这种类型的稀释行为通常对投资者而言是不利的,因为如果基金无法可持续支持该水平的现金流量,则总现金流量最终可能会下降(自然或由基金酌情下降)。这是ROC分布有时与传统股息分布相同的主要原因。但是,当基金始终如一地赚取其分配时,资本回报的好处就会充分实现。

能量启发模型:利用采样器诱导分布进行学习
基于能量的模型 (EBM) 是强大的概率模型 [8, 44],但由于配分函数的原因,其采样和密度评估难以处理。因此,EBM 中的推理依赖于近似采样算法,导致模型和推理不匹配。受此启发,我们将采样器诱导分布视为感兴趣的模型,并最大化该模型的似然。这产生了一类能量启发模型 (EIM),它结合了学习到的能量函数,同时仍提供精确样本和可处理的对数似然下限。我们基于截断拒绝抽样、自归一化重要性抽样和汉密尔顿重要性抽样描述和评估了此类模型的三个实例。这些模型的表现优于或相当与最近提出的学习接受/拒绝采样算法 [ 5 ],并为排序噪声对比估计 [ 34 , 46 ] 和对比预测编码 [ 57 ] 提供了新的见解。此外,EIM 使我们能够概括多样本变分下界 [ 9 ] 和辅助变量变分推断 [ 1 , 63 , 59 , 47 ] 之间的最新联系。我们展示了最近的变分界限 [ 9 , 49 , 52 , 42 , 73 , 51 , 65 ] 如何与 EIM 统一为变分家族。

SUS GAUSSIAN分布及其...
我们证明存在一个通用常数c> 0,因此对于每个d∈N,r d上的每个cen subgaussian分布d,每个偶数偶数p∈N,d variate polyenmial(cp)p/ 2·p/ 2·v v v∥p 2 - e x〜d -e x〜d〜d〜d v,x〜v,x〜v,x〜v,x〜v,x〜v,x〜是平方polynoms of Square polynoms of Square polynoms sum s sum s sum sarear polynoms s。这表明每个次高斯分布都是SOS信誉的次高斯 - 这种条件可为各种高维统计任务提供有效的学习算法。作为直接的推色,我们在计算上有效算法,并为以下任务提供几乎最佳的保证,当给定任意次高斯分布的样品时,我们可以遵守均值估计,可列表的均值均值估计,均值分离的均值混合模型,可靠的均值估计,可靠的估计量,强大的估计,可强大的估计,估算强大的估计,估算。我们的证明是对Talagrand的通用链接/主要措施定理的必要利用。

季节性温度分布的十年可预测性
抽象的十年预测定期关注单个值的预测性,例如均值或极端。在这项研究中,我们研究了全球和欧洲尺度上完整的基础表面温度分布的预测技能。我们研究了Max Planck Institute地球系统模型decadal预测系统的初始化后广播模拟,并比较季节性每日温度的分布与估计气候和非传统历史模拟的估计。在分析中我们表明,初始化的预测系统在北大西洋地区具有优势,因此可以对整个温度频谱进行可靠的预测,以提前两到10年。我们还证明了初始化气候预测预测温度分布的能力取决于季节。