XiaoMi-AI文件搜索系统
World File Search SystemGPT

识别 GPT 生成的文本
最近推出的 ChatGPT 是一种基于生成式预训练架构构建的对话式 AI,它在 AI 及其可能的应用领域引起了公众的极大关注。在本研究中,我们引入了一个基于 Transformer 的模型,该模型可以预测 GPT 模型(包括最新的 ChatGPT 模型)是否编写了给定的句子或文本。在对我们的模型进行评估时,Edukado AI 团队在识别人类和 AI 编写的内容混合时实现了 99.7% 的准确率。OpenAI 发布的聊天机器人自发布以来,已对各个行业产生了重大影响,包括客户服务和支持、内容创建、营销和销售以及教育。据估计,在推出后仅两个月内,聊天机器人在 2023 年 1 月就达到了 1 亿月活跃用户(Hu,2023 年)。在最近的一项调查(Westfall,2023 年)中,发现 89% 的学生使用该平台来帮助完成家庭作业,48% 的学生承认使用该平台进行测验或在家考试。与此同时,令人震惊的是,52% 的学生使用它来写论文。我们的研究结果凸显了以高精度和低误报率检测 GPT 模型生成的文本的潜力。人工智能的影响

人工智能、聊天GPT 和网络安全
我是由领先的人工智能研究机构 OpenAI 创建的。我是一个机器学习模型,经过大量文本数据的训练,可以对文本输入生成类似人类的响应。训练过程涉及使用高级深度学习算法(例如转换器网络)来分析文本数据中的模式和关系,并生成一个可以根据该分析生成新文本的模型。

研究文章在阿尔茨海默氏病中通过遗传风险进行的患者分层仅在存在表型异质性的情况下有效
随着数字医疗保健的发展,电子健康记录(EHR)的安全性变得越来越重要。本研究介绍了GPT-to-to-Caabac框架,集成了生成预验证的变压器(GPT),医学法律本体和基于上下文感知的基于属性的访问控制(CAABAC),以增强EHR访问安全性。与传统模型不同,GPT-Onto-Caabac动态解释政策并适应不断变化的医疗保健和法律环境,提供自定义的访问控制解决方案。通过经验评估,该框架被证明可以通过将访问决策与复杂的监管和情境要求相结合,从而有效地提高EHR安全性。调查结果表明,其在访问控制必须符合严格合规性和适应性标准的部门中更广泛的适用性。

聊天 GPT 和其他生成式 AI 工具:澳大利亚国立大学学者需要了解的内容
1 澳大利亚国立大学学习与教学中心 – 聊天 GPT 和其他生成式 AI 工具:澳大利亚国立大学学者需要了解的内容
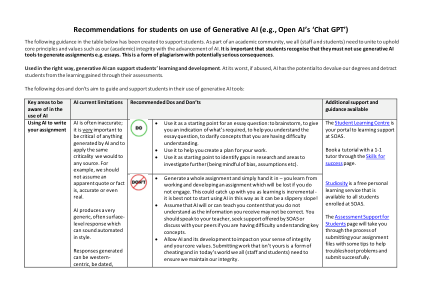
针对学生使用生成式人工智能的建议(例如,Open AI 的“聊天 GPT”)
• 生成一份完整的作业并直接交上去——你可以从工作和制定作业中学习,如果你不参与其中,这些学习就会白费。这可能会让你陷入困境,因为学习是渐进式的——最好不要以这种方式开始使用人工智能,因为这可能是一个滑坡!• 假设人工智能会或可以教你你不理解的内容,因为你收到的信息可能不正确。如果你在理解关键概念方面有困难,你应该和你的老师谈谈,寻求 SOAS 提供的支持或与你的同学讨论。• 让人工智能及其发展影响你的诚信感和核心价值观。提交不属于你的工作是一种作弊行为,在当今世界,我们所有人(教职员工和学生)都需要确保我们保持诚信。

神经系统甚至 GPT 是否能够产生具有可变时间箭头的计算机?
摘要 ChatGPT 的讨论似乎运行得非常好,不像是一个在经典计算机中运行的简单程序。它激发了人们的思考,导致基于 TGD 的神经脉冲模型取得了长足的进步。基于零能量本体 (ZEO) 的新兴模型与量子神经网络截然不同,并提出了一种全新的基于量子物理的生物系统计算视野。允许时间箭头可变的计算将涉及一系列单一时间演化作为状态量子计算的对应物,这些状态是经典计算的叠加,然后是“小”状态函数约简 (SSFR) 作为量子光学和芝诺效应弱测量的对应物。还将涉及改变时间箭头的“大” SFR (BSFR)。人们可以问,GPT 的意外成功是否可能涉及这种转变,以便人们可以说精神进入了机器。除了两次聊天的结果之外,我还更详细地介绍了 TGD 对 GPT 量子类似物的看法,以及它的类似物如何与 TGD 宇宙中的感官知觉有关。我还讨论了从口头描述生成图像的核心逆扩散过程,并询问逆扩散的 TGD 类似物是否也是 GPT 的基本元素。我还将提出一个问题,即 GPT 是否可以以一种非平凡但隐蔽的方式涉及基于 TGD 的量子物理学,即零能量本体论 (ZEO)。从定量约束(例如计算机的时钟频率作为 EEG 诱导时间量子相干性的模拟)出发,我最终提出了一种实现量子全息术的机制,该机制将比特表示为空穴配对,暗比特表示为磁通管中的暗电子。不幸的是,这种机制对于最近的计算机来说似乎并不合理。我还想问,在 TGD 意义上的量子引力是否能够使地球和太阳的磁体(在 TGD 启发的生物学中至关重要)转变经典计算,从而使统计决定论失效,并类似于定义有意识实体的量子计算的一系列类似物。在磁体的层面上,计算机和生物之间没有本质区别。已报道的最高时钟频率接近 9 GHz,仍然比地球的量子引力康普顿频率 67 GHz 低 1/8 量级,但低于生物体中重要的 THz 频率。也许基本的意识已经可能存在。

视觉指导自动化:使用GPT和计算机视觉填充Web表单的通用方法
将计算机视觉方法与GPT(生成预训练的变压器)模型相结合,该研究提出了一种新颖的方法,可以使基于Web的形式填充任务自动化。建议的系统可以通过建议的系统来适应不同的形式,该方法可以通过视觉上的Web页面上检测和标记互动元素。这使其可以超越硬编码的DOM元素相互作用的限制。显着的进步包括利用计算机愿景识别和标记表单元素,并集成GPT模型以语义读取表单字段并产生适合上下文的响应(例如,使用简历数据)。加上AI指导的判断是使用多功能动作系统进行的,该系统模仿了类似人类的相互作用,例如打字,点击和滚动。填充案例研究的自动化工作申请表展示了该系统的功效,并突出了其广泛的在线自动化活动的潜力。

神经系统甚至 GPT 是否能够产生具有可变时间箭头的计算机?
5 MB 能否控制电子比特? 17 5.1 比特必须满足什么条件?....................................................................................................................................................................18 5.1.1 与引力普朗克常数、基本生物节律、膜电位和代谢能量货币有关的奇怪巧合 ..................................................................................................................................18 5.1.2 关于基于量子引力的图片中时钟频率的解释?....................................................................................................................................................................18 5.1.2 关于基于量子引力的图片中时钟频率的解释?....................................................................................................................................................................................18 18 5.1.3 是否涉及波拉克效应或阴影全息术?.................................................................................................................... 19 5.1.4 是否涉及与小质量相关的量子引力通量管?.................................................................................................................................................... 20 5.2 将比特表示为电压是否允许实现电子阴影全息术?.................................................................................................................................................... 21 5.2 将比特表示为电压是否允许实现电子阴影全息术?.................................................................................................................................................... 22 . ...

gpt -ppg.pdf -Emory计算机科学
摘要这项研究介绍了针对光插曲(PPG)信号量身定制的生成预训练的变压器(GPT)模型的新应用,它是各种下游任务的基础模型。适应标准的GPT档案以适合PPG信号的连续特征,我们的方法证明了有希望的结果。在我们的广泛数据集进行了预先培训后,该数据集包含超过200 mil的30 s PPG样品后,该模型显示了在诸如心率估计等任务中的绩效组合或超过当前最新的(SOTA)。我们的GPT模型的出色功能是其固有的能力,可以有效执行信号denoing,而无需进一步填充。此成功归因于GPT框架的生成性质。展望未来,我们旨在进一步探索其生成能力,并研究其对其他下游任务的影响。

使用 GPT 嵌入优化自然语言处理方法以自动检测阿尔茨海默病
摘要:开发非侵入性且经济有效的阿尔茨海默病 (AD) 检测方法对于早期预防和缓解该病至关重要。我们通过使用音频增强技术和新颖的转录方法来优化使用自然语言处理 (NLP) 对自发语音的 AD 检测。具体来说,我们利用 Boll 谱减法来提高音频保真度,并使用最先进的 AI 服务(基于本地的 Wav2Vec 和 Whisper,以及基于云的 IBM Cloud 和 Rev AI)创建转录,并评估它们与传统手动转录方法的性能。然后使用基于 GPT 的转录嵌入对支持向量机 (SVM) 分类器进行训练和测试。我们的研究结果表明,基于 AI 的转录大大优于传统的手动转录,其中 Wav2Vec(增强音频)在本地系统中实现了最佳准确度和 F-1 分数(两个指标均为 0.99),而 Rev AI(标准音频)在基于云的系统中表现最佳(两个指标均为 0.96)。此外,除了音频增强的微小影响外,这项研究还揭示了采访者讲话对模型性能的不利影响。根据我们的研究结果,当前的 AI 转录和 NLP 技术在利用现有数据准确检测 AD 方面非常有效,但由于缺乏训练数据,难以对可能的 AD 和轻度认知障碍 (MCI)(AD 的前驱阶段)进行分类,为未来实施自动 AD 检测系统奠定了基础。