XiaoMi-AI文件搜索系统
World File Search SystemGPT
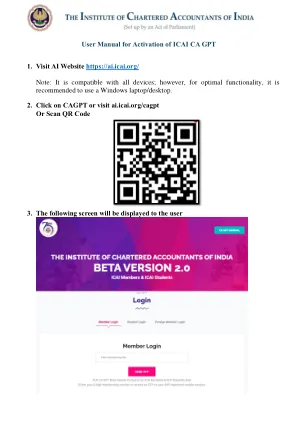
激活ICAI CA GPT
免责声明:ICAI CA GPT是Beta版本,其中所有由ICAI创建和配置的GPT由开放AI平台供电。Beta版本在训练阶段和机器学习中,根据收到的反馈和建议,正在改善及时响应。从ICAI CA GPT内容收到的响应仅用于信息和教育目的,不应被视为合法,会计或税收建议,或者是获得特定于您的企业的建议的替代品。此Beta版本使用知识存储库和培训模型。虽然努力确保准确性,但可能会出现错误。在ICAI CA GPT上的所有内容都以“可用”为基础提供给您的所有内容,无论是否有明示或暗示的保证,包括但不限于任何隐含的适销性,适用于特定目的,准确性和非侵权的ICAI的适合性,对通过此平台的准确性,完整性,货币,货币或可靠性都没有保证。成员使用自己的回复。

利用GPT模型进行语义表注释
摘要本文概述了我们对准确性轨道和语义表解释(STI)和大语言模型(LLMS)的贡献,该语义网络挑战在表格数据上挑战对知识图匹配(SEMTAB)。我们的方法涉及使用LLM来解决挑战中提出的各种任务。具体来说,我们对大多数任务采用了零射门和少量提示技术,这促进了LLMS以最少的先前培训来解释和注释表格数据的能力。对于列属性注释(CPA)任务,我们通过应用一组预定义的规则来采用不同的方法,该规则是针对每个数据集的结构量身定制的。我们的方法取得了显着的结果,𝑓1 -𝑠𝑐𝑜𝑟𝑒超过0。92,证明了LLM在应对SEMTAB挑战方面的有效性。这些结果表明,LLM具有重要的功能,作为语义表注释和知识图匹配的强大解决方案,突出了它们推进语义Web技术领域的潜力。


根据医学指南的 GPT 药物可以改善……
本研究探索了基于医疗指南的生成式预训练 Transformer (GPT) 代理使用大型语言模型 (LLM) 技术在创伤性脑损伤 (TBI) 康复相关问题上的应用。为了评估使用 GPT-4 创建的多个代理 (GPT-agents) 的有效性,使用直接 GPT-4 作为对照组 (GPT-4) 进行了比较。GPT-agents 包含多个具有不同功能的代理,包括“医疗指南分类”、“问题检索”、“匹配评估”、“智能问答 (QA)”和“结果评估与来源引用”。从医患问答数据库中选择了脑康复问题进行评估。主要终点是更好的答案。次要终点是准确性、完整性、可解释性和同理心。回答了 30 个问题;总体而言,GPT 代理的响应时间比 GPT-4 长得多,而且字数也更多(时间:54.05 vs. 9.66 秒,字数:371 vs. 57)。但是,与 GPT-4 相比,GPT 代理在更多情况下提供了更出色的答案(66.7 vs. 33.3%)。GPT 代理在准确度评估方面优于 GPT-4(3.8 ± 1.02 vs. 3.2 ± 0.96,p = 0.0234)。未发现不完整答案的差异(2 ± 0.87 vs. 1.7 ± 0.79,p = 0.213)。然而,在可解释性(2.79 ± 0.45 vs. 07 ± 0.52,p < 0.001)和同理心(2.63 ± 0.57 vs. 1.08 ± 0.51,p < 0.001)评估方面,GPT 代理表现明显更好。根据医学指南,GPT 代理提高了对 TBI 康复问题回答的准确性和同理心。本研究提供了指南参考,并展示了更好的临床可解释性。然而,需要通过临床环境中的多中心试验进一步验证。本研究提供了实用见解,并为 LLM 代理医学的潜在理论整合奠定了基础。

Informatica CLAIRE GPT:强大的人工智能驱动数据管理
数据消费者在与数据交互时面临一系列挑战。其中最突出的是需要花费大量时间追踪有用数据、难以获取可靠、可信的数据以及掌握技术技能的必要性。这需要掌握各种结构化查询语言 (SQL) 和一系列编程语言,包括但不限于 C#、Java、Ruby、C++、PHP、JavaScript、Python。学习这些语言对于将原始数据转换为有价值的见解以及实现数据的端到端生命周期管理至关重要。公司历来高度依赖昂贵的数据工程师来编译数据。这些数据孤岛最终被移交给一组主题专家进行验证和微调,这个过程的典型特征是成本过高、效率低下和繁重的交付周期。

使用生成式人工智能(CHAT GPT、GEMINI 等)
• 使用生成式人工智能超出主题协调员允许的范围。有些主题可能不允许使用人工智能,或者只允许在一定限制下使用。如果主题信息或评估说明指定了如何使用人工智能,请务必遵守这些准则。如果您不确定,请咨询您的主题协调员。 • 将生成式人工智能生成的输出作为您自己的作品提交。这可能构成合同欺诈,至少是 2 级学术不端行为。 • 未正确引用生成式人工智能生成的输出。确保您根据主题的首选引用风格引用生成式人工智能生成的输出。APA 7 和哈佛参考指南已更新,包括对生成式人工智能工具的承认。 • 不承认您使用了生成式人工智能。您必须提供一份声明,承认您如何使用人工智能。这应该作为脚注或参考列表的末尾包括在内——

GPT 2024 年能源总体规划更新
将使用可再生电力的供暖系统转换为电加热系统的主要方法是用热泵系统取代燃气锅炉。这些系统效率高,可以在较热的月份为建筑物增加额外的制冷能力。然而,热泵系统确实需要额外的空间、通风,有时还需要改进的热分配系统来适应较低的温度,这可能会给淘汰燃气带来挑战。GPT 的新开发项目现在设计了全电动建筑供暖系统,对于现有建筑,在建筑供暖的下一个生命周期中,GPT 打算将这些资产电气化。

GPT集团2023年年度报告体验第一
您应该注意,过去的表现不一定是未来表现的指南。尽管我们尽一切努力提供准确和完整的信息,但 GPT 集团不声明或保证本报告中的信息没有错误或遗漏、完整或适合您的预期用途。特别是,对于本报告中包含的任何前瞻性陈述或其所基于的假设的准确性、实现可能性或合理性,不作任何陈述或保证。此类材料本质上受 GPT 无法控制的重大不确定性和偶然性的影响。实际结果、情况和发展可能与本报告中明示或暗示的结果、情况和发展存在重大差异。

基于NLP的问题回答肠道微生物组的GPT
当前基于NLP的CHATGPT深度学习模型已经开发并验证了这些模型,这些模型在与一般主题有关的多项选择问题上,并在某种程度上是标准的科学基准数据集,例如PubMed Question-swingering(PubMedQA),Arxiv和Stanford Question-wording Question-Assive-Assive-Asswork-Assworge-Answorking Dataset(Squead)。但是,QA任务尤其是全文文章阅读是一项非常具有挑战性的任务,并且在当前Chatgpts的科学环境中是一项艰巨的任务。我们的管道着重于生物化学,生物信息学,生物医学的生成预训练的变压器(GPT)模型,包括临床文献,例如生物标志物,药物,剂量等。与迄今为止在现场的给定关键字或上下文特定文献有关(“人类肠道微生物组作为案例研究”)。

汽油价格和关税(GPT)包:R740 220.00
要求: *会计,金融,经济学或任何其他类似或同等学历的学士学位 *至少五(5)年的工作经验,可以应用于管道的价格和关税。候选人必须在以下内容中胜任: *建模和电子表格 *报告写作技巧 *人际交往能力 *计算机素养(MS Excel,Word,Word,Power Point和Microsoft Project) *分析技能 *分析技能 *人际交往能力 *良好的沟通(言语和书面)技能 *领导才能 *领导才能 *时间管理技能 *时间管理技能 *决策和问责制。目的:向部门负责人报告:煤气定价和关税,现任者将协助Nersa履行其在拆除账户和关税的责任。关键责任:成功的现任者将: *根据立法要求制定,审查和实施未捆绑业务的账目的指南,并实施这些 *对传输关税的实施和审查关税指南 *监控汽油关税协议 *制定方法,以根据《天然气法》确定所有客户的最高价格。*与《天然气法》,《莫桑比克天然气管道协议》,《天然气法规》,《天然气规则》和监管决策有关的NERSA的定价和关税责任 *对许可证申请进行经济分析 *编译能源监管机构的提交 *协助开发流程,程序和