XiaoMi-AI文件搜索系统
World File Search SystemGemma

Gemma Calamandrei
详细或为加工做出了贡献 - 就国际空间站多种结构发出的意见而言,就卫生部的要求(过去十年中大约40个)就国会问题,议会动议和对心理健康问题的账单提出了意见;他在国家生物伦理学委员会(National Bioethics委员会)就进化时代的精神残疾问题进行了试镜; 2017年,它应议会童年和青春期委员会的总统要求报告,涉及“未成年人的心理身体健康”,这与儿童在大火之地所谓的儿童中罕见的脑肿瘤的增加有关; 2024年,在儿童和青春期议会委员会中,童年和青春期行为和精神泥土的增加问题。

MTR V3:2024 Waymo Open DataSet挑战的第一名解决方案 - 运动预测
我们介绍了Gemma 3,这是吉玛(Gemma)的轻型开放模型家族的多模式,规模从1到270亿个参数不等。此版本介绍了视觉理解能力,更广泛的语言覆盖范围和更长的上下文 - 至少128K令牌。我们还更改了模型的体系结构,以减少往往会在长上下文中爆炸的KV-CACHE内存。这是通过增加本地注意层与全球注意力层的比率并保持局部注意力的范围来实现的。Gemma 3型号经过蒸馏训练,并为预训练和指令固定版本提供了超过Gemma 2的性能。,我们的新型培训后食谱可显着改善数学,聊天,指导跟踪和多语言能力,从而使Gemma3-4B-IT与Gemma2-27b-it和gemma3-27b-it和gemma3-27b-it竞争与Geminii-1.5-Pro可比。我们将所有模型都发布给社区。

Horche Rody
日期:12-09-2024名称和姓氏:Gemma Guillazo Blanch机构:大学教授或中心:巴塞罗那自治大学知识:心理学知识领域:心理生物学Sexenios(RD 1086/89):5研究活动,转移和交换知识:1.1。 div>研究,转移和交换知识的项目和合同1。项目。 div>pid2020-114243rb-i00,营养,脑衰老和神经变性。 div>科学与创新部。 div>Gemma Guillazo Blanch。 div>(巴塞罗那自动诺马大学(UAB))。 div>01/09/2021-08/31/2024。 div>€102,850。 div>主要研究人员。 div>2。 div>项目。 div>PSI2017-84290-R,与衰老相关的认知下降的预防和治疗:相关的大脑行为和机制。 div>经济与竞争力部(MINECO)。 div>Gemma Guillazo Blanch。 div>(巴塞罗那自动诺马大学(UAB))。 div>01/01/2018-30/09/2021。 div>€70.180。 div>主要研究人员。 div>3。 div>项目。 div>PSI2014-52660-R,通过认知缺陷的动物脑刺激的关系记忆增强和工作记忆的增强:行为和神经生理学。 div>经济与竞争力部(MINECO)。 div>Gemma Guillazo Blanch。 div>(巴塞罗那自动诺马大学(UAB))。 div>01/01/2015-12/2017。 div>€77,440。 div>主要研究人员。 div>4。 div>项目。 div>科学与创新部。 div>PSI2011-26862,由于衰老和脑损伤而引起的认知不足模型的注意力和记忆的增强。 div>Gemma Guillazo Blanch。 div>(巴塞罗那自动诺马大学(UAB))。 div>01/01/2011/12/2014。 div>€94,380。 div>主要研究人员。 div>5。 div>项目。 div>PSI2008-04267,在认知过程的调节中,胆碱能和谷氨酸神经传递系统的影响:学习护理和记忆。教育和科学部。 div>玛格丽塔·马蒂·尼科洛维乌斯(Margarita Marti Nicolovius)。 div>(巴塞罗那自动诺马大学(UAB))。 div>01/01/2009-31/12/2011。 div>€96,800。 div>团队成员。 div>6。Project.SEJ2005-02518/PSY,涉及大脑唤醒系统对复杂认知过程调节的神经生理机制。 div>教育与科学部。 div>玛格丽塔·马蒂·尼科洛维乌斯(Margarita Marti Nicolovius)。 div>(巴塞罗那自动诺马大学(UAB))。 div>13/2/2005-13/12/2008。 div>€76,160。 div>团队成员。 div>7。project.BSO2002-03441,机制,机制,cliSloficplicateSnlareversiófuncional,mitjanc the cognitives d'Alzheimer and d'Alzheimer and amn alzheimer andAmnèsidephalica的cognitives d'A a an an an an antelèctric刺激。 div>科学技术部。 div>玛格丽塔·马蒂·尼科洛维乌斯(Margarita Marti Nicolovius)。 div>(巴塞罗那自动诺马大学(UAB))。 div>01/12/2002-01/12/2005。 div>41,400。 div>

Gemma:基于 Gemini 研究和技术的开放模型
Gemma 有两种规模:一种是用于在 GPU 和 TPU 上高效部署和开发的 70 亿参数模型,另一种是用于 CPU 和设备上应用程序的 20 亿参数模型。每种规模都旨在解决不同的计算约束、应用程序和开发人员要求。在每种规模下,我们都会发布原始的、预先训练的检查点,以及针对对话、指令遵循、帮助性和安全性进行微调的检查点。我们会根据一系列定量和定性基准彻底评估我们模型的缺点。我们相信,发布预训练和微调的检查点将有助于彻底研究和调查当前指令调整机制的影响,以及开发越来越安全和负责任的模型开发方法。
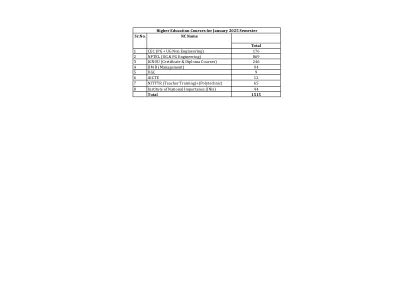
Gemma 3技术报告-Googleapis.com2025年1月的学期清单-Googleapis.com
171商业银行和保险Nilam Panchal Gujarat University UG 5.5 5 5.5 12 4 Bcom英语172经济学营销管理Dr. Pradip Pradip Prajapati Gujarat University Universion UG 5 12 3 BA英语173 HRM HRM HRM HRM HRD:策略和系统UG 5 12 4英语175管理,商业

埃隆·马斯克(Elon Musk):很快,AI将无需教
例如,Microsoft PHI-4和Google Gemma模型接受了使用的培训。但是,尽管经济优势(例如,作者以70万美元的价格创建了Palmyra X 004型号,而对于类似的OpenAI模型来说是460万美元),但合成数据可以导致“模型崩溃”,从而降低其创造力并增加偏见。

1出现的TA4C3和MO2TI2C3 MXENE纳米片...
Michalis Stavrou,* Benjamin Chacon,Maria Farsari,Anna Maria Pappa,Lucia Gemma Delogu,Yury Gogotsi,*和David Gray*


联合当地健康和福祉策略刷新
作者/领导联系人:Buckinghamshire Healthcare NHS Trust&Louise Hurst战略交付总监Gemma Thomas,Buckinghamshire Council临时公共卫生主管
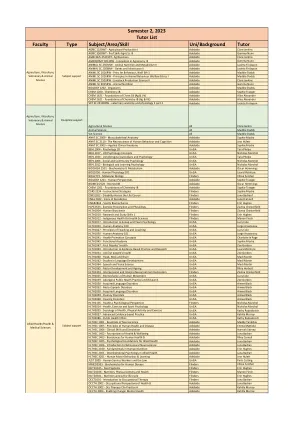
学期2,2023 Tutor List
AGRIC 1520WT - Agricultural Production I Adelaide Clare Jenkins AGRIC 3500WT - Prof Skills Agric Sc III Adelaide Gemma Nunn AGRICBUS 2520 WT- Agribusiness Adelaide Clare Jenkins AGRONOMY 3012RW - Innovation in Agronomy III Adelaide Gemma Nunn ANIMAL SC 2505RW - Animal Nutrition and代谢II阿德莱德·耶金特·芬莱森动物SC 2508RW-基因和继承i ii阿德莱德·贾辛特·贾辛塔·芬莱森·芬莱森动画sc 1016rw -princ a行为,福利eth 1阿德莱德·麦迪·麦迪·麦迪德斯·多德斯动画sc 1016rw -sc 1016rw- Adelaide Clare Jenkins ANIML SC 3015RW - Animal Nutrition Adelaide Gemma Nunn BIOLOGY 1202 - Organisms Adelaide Maddie Dodds CHEM 1200 - Chemistry 1B Adelaide Sophie Traeger CHEM 1621 - Foundations of Chem 1B (Ag & Vit) Adelaide Alice Alexander CHEM 1621 - Foundations of Chemistry IB (Ag & Vit) Adelaide Alice Alexander兽医SC 2510BRW-兽医解剖学和生理学II第2部分阿德莱德Jacinta Finlayson