XiaoMi-AI文件搜索系统
World File Search SystemLang

最先进的
学习实验室:第1天(需要额外费用)7:00 AM注册和早餐7:45 AM欢迎,目标和介绍R. Lang,M。Umland,M。Umland上午8:00 AM,AM上,AM M. Umland M. Umland 8:15 AM 2D评估左心室收缩功能,左心房,左心,以及3D R. Lang,M. YAMAT 9:00 AM YAMAT 9:00 AM YAMAT 9:00 AM WESTRIC,d. Ignatowski, R. Jain, A. Kaminski, C. Kramer, M. Umland 9:45 AM 3D Echo for Left Ventricular Systolic Function E. Kruse, R. Lang, M. Yamat 10:30 AM Refreshment Break 10:45 AM Conventional and Basic Strain Measurements of Right Ventricular Systolic Function D. Adams, J. Betz, S. Mankad, J. Warmsbecker 11:30 AM Basic Left Ventricular Strain Measurements D. Ignatowski, R. Jain, A. Kaminski, C. Kramer, M. Umland 12:15 PM Lunch Break 1:15 PM Quantification of Aortic and Mitral Regurgitation J. Betz, C. Kramer, S. Mankad, J. Warmsbecker 2:00 PM 3D Echocardiography for Mitral Disease E. Kruse, R. Lang, M. Yamat 2:45 PM Aortic Stenosis: Measurements for Native and Prosthetic Valves D. Adams, J. Betz, S. Mankad, J. Warmsbecker 3:30 PM Refreshment Break 3:45 PM Advanced Diastolic Cases Including Constriction and Restriction D. Ignatowski, R. Jain, A. Kaminski, C. Kramer, M. Umland 4:30 PM Crop Til You Drop I: Cases All Faculty 5:30 PM Adjourn

未来国际货币体系中的催化力量
Nicola Bilotta 曾担任国际事务研究所 (IAI) 高级研究员,领导数字化和全球经济研究。他目前是欧盟监管数字金融学院 (EU-SDFA) 的协调员和佛罗伦萨银行与金融学院 (欧洲大学学院) 的研究员。他还是 LUMSA 大学的兼职教授和 IAI 的副研究员。此前,他曾担任银行家研究团队 (金融时报) 的高级研究分析师、战略与国际研究中心的客座研究员以及 2021 年意大利担任 G20 主席国期间 Think20 工作组“基础设施投资和融资”的协调员。他共同编辑并参与了以下书籍:《科技巨头的崛起》。全球金融和政治的游戏规则改变者(Peter Lang,2019 年)和中央银行数字货币的(近期)未来。全球经济和社会的风险和机遇(Peter Lang,2021 年)。
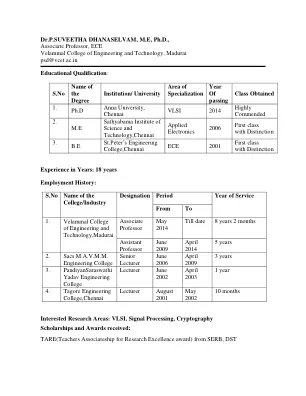
P.SUVEETHA DHANASELVAM 博士,ME,博士
其他简介:https://scholar.google.co.in/citations?user=pXGIwh8AAAAJ&hl=en https://orcid.org/0000-0001-8441-1349?lang=en https://www.researchgate.net/profile/P-Dhanaselvam/publications https://www.scopus.com/authid/detail.uri?authorId=55621663600 https://suveethap.blogspot.com/

迪伦·阿什利
Best-Paper Award , NeurIPS R-FoMo Workshop Rising Star in AI Award , King Abdullah University of Science and Technology Queen Elizabeth II Graduate Scholarship , University of Alberta (C$,) CGS-M , Natural Science and Engineering Research Council of Canada (C$,) Walter H. Johns Graduate Fellowship , University of Alberta (C$,) Science Graduate Scholarship , University of Alberta (C$,) Kao艾伯塔省大学(C $,)艾伯塔大学(C $)艾森科大学(C $)艾伯塔大学(C $,)Suncor Energy奖学金,Suncor Energy(C $,)Jason Lang奖学金(C $,C $,SUNCOR SUNCOR ENFERCE奖学金(C $)Suncor Energy,Suncor Energy,Suncor Energy,Suncor Energy,Suncor Energy,Suncor Energy,Suncor Energy(C $,)

观赏洞穴对环境的影响研究
m和al。,2006年;费尔南德斯 - 委员会和al。,2011年;朗和al。,2015a;朗和al。,2015b;朗和al。,2017年; Lobo和Al。,2014年; Pulid-Bosch和Al。,1997; Šebela等。,2013年; Singh,2011年),灯的增长(例如estevez和al。,2019年; Havlena,2019年; Curnish and al。,2018年; Mulec&Kosi,2009年;钢琴和AL。,2015年; Pulid-Bosch和Al。,1997)我们的污染(例如Chang和Al。 ,2008年;克里斯曼,2019年; Šebela等。 ,2015年),因此,第一个洞穴和保护主题的基本资源(Cigna,2016; Cigna&Forti,2013; 2013; de Freitas,2010)。 国家项目“ Showcave。深入的慈善机构以及对物理学,水文,水文学,水文学,有机考古和物理有机的剥削游客的定量。 这个Chang和Al。,2008年;克里斯曼,2019年; Šebela等。,2015年),因此,第一个洞穴和保护主题的基本资源(Cigna,2016; Cigna&Forti,2013; 2013; de Freitas,2010)。国家项目“ Showcave。深入的慈善机构以及对物理学,水文,水文学,水文学,有机考古和物理有机的剥削游客的定量。这个

对高度选择性OECT基于OECT的锌检测的电聚合噻吩衍生物的光电和氧化还原特性
Tommaso Nicolini,Shekhar Shinde,Reem El-Actar,Gerardo Salinas,Damien Thuau,Mamatimin Abbas,Matthieu Raoux,Jochen Lang,Eric Clout,Eric Clout,Alexander Kuhn,Alexander Kuhn,Alexander Kuhn* T. Nicolini博士,G。Salinas博士,G。Salinas,PROFIV。Bordeaux,CNRS,Bordeaux INP,ISM,UMR 5255,33607 PESSAC,法国电子邮件:kuhn@enscbp.fr S. S. S. S. Shinde,E。Cloutet Uni博士。 Bordeaux,CNRS,Bordeaux INP,LCPO,UMR 5629,33615 Pessac,法国R. El-Actar,D。Thuau博士,M。AbbasUniv博士。 波尔多,CNRS,Bordeux INP,CBMN,UMR 5248,33600 PESSAC,法国,Bordeaux,CNRS,Bordeaux INP,ISM,UMR 5255,33607 PESSAC,法国电子邮件:kuhn@enscbp.fr S. S. S. S. Shinde,E。Cloutet Uni博士。Bordeaux,CNRS,Bordeaux INP,LCPO,UMR 5629,33615 Pessac,法国R. El-Actar,D。Thuau博士,M。AbbasUniv博士。 波尔多,CNRS,Bordeux INP,CBMN,UMR 5248,33600 PESSAC,法国,Bordeaux,CNRS,Bordeaux INP,LCPO,UMR 5629,33615 Pessac,法国R. El-Actar,D。Thuau博士,M。AbbasUniv博士。波尔多,CNRS,Bordeux INP,CBMN,UMR 5248,33600 PESSAC,法国,波尔多,CNRS,Bordeux INP,CBMN,UMR 5248,33600 PESSAC,法国,

北剑桥电池电动总线设施修改
MBTA Capital Delivery – Transit Group • John Schwarz - Acting Deputy Chief of Transit Programs • Jim Caroselli - Senior Director Transit Station and Facilities • Sheryl Diaz - Senior Project Coordinator • Kayla Lang - Resident Engineer • Greg McNally - Senior Project Manager

第 2 阶段主要报告 - 开发栖息地规模 DNA ...
致谢:本研究由苏格兰政府农村和环境科学与分析服务部 SG-RESAS 提供资金。作者要感谢第二阶段项目管理指导小组 (MSG):Pauline Lang(合同经理、首席项目合作伙伴)、Alistair Duguid(苏格兰环境保护署,SEPA)、Colin Bean(NatureScot)、Iveta Matejusova(苏格兰政府海洋局(前身为苏格兰海洋科学,MSS))和 Helen Jones(苏格兰政府农村和环境科学与分析服务部,SG-RESAS)在整个项目中给予的大力支持和建议。我们还要感谢 Colin Bean(NatureScot)、Iveta Matejusova(海洋局(前身为苏格兰海洋科学局,MSS))、Pauline Lang 和 Alistair Duguid(苏格兰环境保护署,SEPA),以及顾问委员会成员 Douglas Yu §(NatureMetrics)、Pippa Howard §(NatureMetrics)、Nadia Barsoum §(森林研究)为本工作提供项目指导、技术建议和同行评审。

阳光健康佛罗里达州医疗补助计划会员手册
如果您不会说英语,请拨打 1-866-796-0530(TTY 1-800-955-8770)。我们提供口译服务,可以帮助您用您的语言回答您的问题。我们还可以帮助您找到能够用您的语言与您交流的医疗保健提供者。如果您不会说英语,请拨打 1-866-796-0530(TTY 1-800-955-8770)。我们提供口译服务来帮助您用您的语言回答问题。我们还可以帮助您找到能够用您的语言与您交流的医疗保健提供者。海地克里奥尔语:如果您不会说英语,请拨打 1-866-796-0530(TTY 1-800-955-8770)。我们已经准备好为您服务,因为我们可以在很长一段时间内解答您的疑问。我们可以拥有或拥有良好的健康,能够以长久或苍白的方式与您进行交流。

论“掘进就是掘模型”的学术思想
MA Hongwei 1, 2 , SUN Siya 1, 2 , WANG Chuanwei 1, 2 , MAO Qinghua 1, 2 , XUE Xusheng 1, 2 , LIU Peng 1, 2 , TIAN Haibo 1, 2 , WANG Peng 1, 2 , ZHANG Ye 1, 2 , NIE Zhen 1, 2 , MA Kexiang 1, 2 , GUO Yifeng 1, 2 , ZHANG Heng 1, 2 , WANG Saisai 1, 2 , LI Lang 1, 2 , SU Hao 1, 2 , CUI Wenda 1, 2 , CHENG Jiashuai 1, 2 , YU Zukun 1, 2