XiaoMi-AI文件搜索系统
World File Search SystemLat

本期内容 - 陆军航空杂志
Armyaviationmagazine.com › archive PDF 2023 年 6 月 27 日 — 2023 年 6 月 27 日 sion,其他分支为飞机与运营虽然飞机的实际服务帐篷......社论有两个方面,纬度,100 小时

GSV接口:新的Python访问气候数字...
lon(ncells)float64 101MB 45.0 45.04 44.96 ... 315.0 315.0 315.0 lat(ncells)float64 101Mb 0.0373 0.0746 0.0746 0.0746 0.0746 ... 315.0 315.0 lat_bounds (ncells, cell_corners) float64 403MB 0.0746 0.0373 ... -0.0373 * time (time) datetime64[ns] 192B 2024-01-01 ... 2024-01-01T23:00:00 Dimensions without coordinates: ncells, cell_corners Data variables:

阅读我们的 2023 年可持续发展报告
与此同时,我们遍布全球的业务部门也在连接节点方面取得了重大进展。PSA Indonesia 与 PT Kereta Api Indonesia (Persero) (KAI) 合作,以增强铁路和铁路物流生态系统,促进高效、可持续的多式联运网络。泰国东海林查班码头与 JWD 运输服务公司合作推出了绿色运输通道服务,这是一条专用于林查班海港和拉卡邦干港之间的电动汽车货运路线。该服务是泰国首创,与传统柴油货运相比,它减少了碳排放,为货主提供了可持续的解决方案。除了港口外,全电动集装箱卡车将用于拉卡邦内陆集装箱仓库和林查班港之间的行程。

TM论坛自主网络和开放标准
ex:exampleintent1 a icm:intent;例如:E1 A ICM:交付期; ICM:目标EX:T1; ICM:targetType sli:切片。ex:e1 a icm:property Expection; ICM:目标EX:T1; ICM:ONEOF(例如:C1 EX:C2)。ex:C1 A ICM:条件; ICM:较小(ICM:CEM值:LAT [ICM:值10; CEM:单位“ GBIT/S”])。


6月4日第50/2024号建议书......
当使用 HPV 检测或联合检测时,后续宫颈癌筛查检查之间的建议间隔为 5 年(BCC 2024、CCA 2022、ACS 2020、CADTH 2019、USPSTF 2018)、5-10 年(WHO 2021)或至少 3 年(GGPO 2022)。对于具有特殊风险的个体,建议缩短筛查间隔,例如患有免疫缺陷症的个体、宫内暴露于 DES 的个体、因 2 级(中级宫颈上皮内瘤变,II 级)、CIN3(高级别宫颈上皮内瘤变,III 级)或癌症而接受手术治疗的个体。

在磁场,电气和标量电势井中旋转时凝结
在凝结物理学中,旋转超氟4和冷原子气体的行为进行了广泛的研究,请参见。[1 - 6]及其中的参考。具有低角速度,ω<ωc 1,超氟4和冷原子气体,放置在最初静止的容器内,由于基本激发的随后旋转而不会响应,因为在这种情况下,基本激发和涡流的产生在这种情况下是无能为力的。随着旋转频率ω的增加,对于ω>ωc1,系统会产生浸入超氟物质中的正常物质的细丝涡旋。然后,对于ω>ωlat>ωC1,涡旋形成三角形晶格,该晶格模拟了容器的刚体旋转。对于ω>ωC2>ωlat>ωC1,经典的冷凝物场被完全破坏。静息金属超导体对外部均匀恒定磁场h的作用做出反应,与中性超氟在旋转方面的响应类似,请参见。[1,7]。通过在该表面层中发生的超导电流(Meissner-Higgs效应),筛选在超导体上的低磁场h(在边界附近的磁场L H(有效光子质量)的所谓穿透深度上进行筛选。超导体在两个类别(第一和第二种的超导体)上细分,这是在Ginzburg-Landau参数的依赖性的依赖性的,其中L ϕ是所谓的相干长度,是公寓

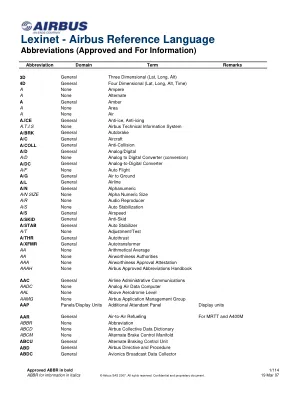
Lexinet - 空中客车参考语言 - SmartCockpit
3D 常规 三维(纬度、经度、高度) 4D 常规 四维(纬度、经度、高度、时间) A 无 安培 A 无 备用 A 常规 琥珀色 A 无 区域 A 无 空中 A.ICE 常规 防冰、防结冰 A.T.I.S 无 空中客车技术信息系统 A/BRK 常规 自动刹车 A/C 常规 飞机 A/COLL 常规 防撞 A/D 常规 模拟/数字 A/D 无 模拟到数字转换器(转换) A/DC 常规 模拟到数字转换器 A/F 无 自动飞行 A/G 常规 空对地 A/L 常规 航空公司 A/N 常规 字母数字 A/N SIZE 无 字母数字大小 A/R 无 音频再现器 A/S 无 自动稳定 A/S 常规 空速 A/SKID 常规 防滑 A/STAB 常规 自动稳定器 A/T 无 调整/测试 A/THR 常规 自动推力 A/XFMR 常规自耦变压器 AA 无 算术平均值 AA 无 适航当局 AAA 无 适航批准证明 AAAH 无 空客批准缩写手册

旱地批准司法裁定表 1
C. 项目位置和背景信息 州:密西西比州 县/教区/自治市镇:麦迪逊县 城市:里奇兰 场地中心坐标(纬度/经度,十进制格式):纬度。32.456606°,经度。-90.174815° 通用横轴墨卡托坐标:15 最近水体名称:Haley Creek 流域名称或水文单元代码 (HUC):03180002