XiaoMi-AI文件搜索系统
World File Search SystemLeve

在诊断中使用轻巧,轻巧和硬技术
电子邮件:anapauloesteves@unifeso.edu.br摘要糖尿病神经病(ND)是一种病理疾病,其特征是临床或亚临床上的异质群,影响外周神经系统(SNP)作为糖尿病的复杂性(糖尿病)。从这个意义上讲,ND似乎是发展溃疡,畸形,下肢截肢以及其他微血管并发症的发展的重要危险因素。这些反过来又与医院住院,非创伤截肢和残疾的最高率有关,因此被认为是重要的公共卫生问题。因此,本研究项目对ND签署中的光,轻型技术的使用进行了书目审查。这是一项基于棱镜分析模型的定性和描述性研究。数据是从索引数据库中的搜索中收集的:Scielo,PubMed和Lilacs。从对选定研究的分析中,缺乏科学作品,这些作品描绘了使用轻质和轻量级技术在ND的医学诊断中的重要性,因为它们保证了一种更具人性化的治疗方法,专注于用户,而不仅仅是以硬技术的使用为中心。关键词:糖尿病神经病,诊断,技术。摘要糖尿病神经病(DN)是一种病理状况,其特征是一组临床或亚临床表现,影响周围神经系统(PNS)作为糖尿病并发症(DM)的并发症。从这个意义上讲,DN似乎是溃疡,畸形,下肢截肢以及其他微血管并发症发展的重要危险因素。这些反过来又与较高的住院率,非创伤截肢和残疾有关,并且是

计算机体系结构基础:处理器、内存、输入和输出设备、应用软件和系统软件:编译器、解释器、高级
计算机体系结构基础:处理器、内存、输入和输出设备、应用软件和系统软件:编译器、解释器、高级和低级语言、结构化编程方法简介、流程图、算法、伪代码(冒泡排序、线性搜索 - 算法和伪代码)

新闻稿发行:2023年5月13日00.01 CET应力激素怀孕期间可能会改善儿童的早期语言发展
新闻稿发行:2023年5月13日00.01怀孕期间的CET压力激素可能会改善儿童的早期语言发育,在怀孕第三个妊娠中期,在儿童生活的前3年,在怀孕的第三个妊娠中期,在妊娠三年中,可以改善言语和语言技能,这可能会提高儿童生活的前三年。这些发现有助于研究人员进一步了解皮质醇在胎儿和儿童发育中的作用。童年时期的语言发展可以表明子宫中婴儿的神经系统的发展程度。产前暴露于皮质醇 - 一种有助于人体应对压力的类固醇激素 - 指导胎儿的生长,并影响其大脑发育。但是,皮质醇对早期语言发展的影响仍然未知。在这项研究中,奥登大学医院的研究人员分析了关于怀孕三个月的1,093名丹麦妇女皮质醇水平的数据,以及来自Odense儿童队列的1,093名12-37个月的丹麦儿童的言语和语言技能。他们发现,子宫中暴露于高皮质醇水平的男孩在12-37个月中可能会说更多单词,而女孩更擅长理解12-21个月的更多单词。“据我们所知,这是一项研究,随着时间的流逝,儿童皮质醇水平与语言发展之间的关联,还考虑了后代性行为和孕产妇的教育水平,”参与研究的Anja Fenger Dreyer博士说。她补充说:“我们已经获得了大型研究队列,高质量的分析方法和相关的协变量,这使我们的研究成为对胎儿成熟和儿童发育中对产前皮质醇暴露的生理理解的重要贡献。”该团队接下来将评估子宫中暴露于高皮质醇的儿童是否更有可能具有更高的智能(IQ)分数。除了有关母体皮质醇水平和早期语言发展的数据外,Odense儿童队列还具有7岁儿童进行的智力测试数据。“儿童的早期语言发展被称为以后生活中认知功能的预测指标,例如注意力,记忆和学习,因此我们要研究产前皮质醇暴露是否也与7岁儿童的智商分数有关,” Fenger Dreyer博士说。

个人简介 Ramesh Kumar Agrawal 手机
课程机构/大学 博士学位 德里大学 M.Tech(CS)IIT,德里 教学经验:约 30 年 行政任命:通信和信息服务首席协调员,2022 年 8 月至今 工程学院院长:2018 年 1 月 - 2020 年 1 月 计算机与系统科学学院院长:2015 年 7 月 - 2017 年 7 月 研究领域:数据挖掘、机器学习、模式识别和医学成像 研究合作(对象):Madhuri Behari 教授、Senthil Kumaran 教授、Achal Kumar Srivastava 教授、AIIMS 的 Leve Joseph 博士 赞助项目数量:04(已完成)01(正在进行):(与 AIIMS 的 Leve Joseph 博士联合开展的项目),使用计算机断层扫描血管造影术检测和评估颅内动脉粥样硬化疾病的计算机辅助诊断系统,由 DBT 赞助, (2020 年 3 月 11 日至 2023 年 3 月 10 日) 专业机构会员资格:IEEE、ACM

RBHS-个性化护理计划(IPOC)。 ...
硕士学位合格的临床专业人员必须与受益人一起审查IPOC,并根据受益人的每个受益人的治疗目标评估受益人的进步。跨学科团队的多个工作人员可以参与开发,准备和/或审查IPOC的过程。•LPHA或Master's Leve的签名合格临床专业人员


集成了Hitop和RDOC框架第I部分
整合hitop和RDOC框架第一部分:外在化和内部化心理病理学的遗传结构Christal N. Davis 1,2,Yousef Khan 2,Sylvanus Toikumo Toikumo 1,2,热爱Jinwala 2,Dorret I. Booms M. Booms M. Booms M. Booms M. Booms Ma 3,Daniel F. Leve 4,5,Henry krker&Henry krker krran kran joel geel&kern&keeld&kern&kern&kern&kell&kell&keeld&keeld&kell&kell&kell y。 1,2
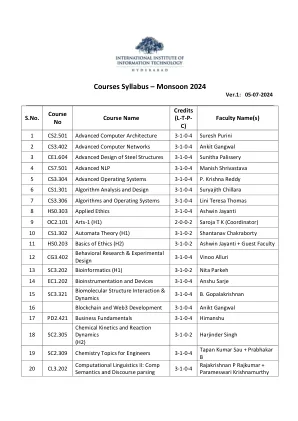
课程教学大纲 - 季风2024 -pgadmissions@iiit.ac.in
co-1:解释现代处理器设计(认知水平:理解)CO-2的原理和实践:解释记忆层次结构设计(认知水平:理解)CO-3的原理和实践CO-3:能够分析定性和定量的处理器/记忆架构的不同方面,并进一步策略策略,并进一步制定策略性策略。(认知堤防:应用,分析,评估和创建)CO-4:解释和确定现代计算系统中的安全漏洞。能够提出技术来规避确定的威胁。(认知水平:理解)3。图表(cos)与程序结果(POS)和程序特定结果(PSO) - 课程表达矩阵PO1 PO1 PO1 PO3 PO3 PO3 PO3 PO3 PO4 PO4 PO7 PO7 PO7 PO7 PO1

年度回顾 - ILGA-欧洲
教育是抵制 LGBTI 人群及其权利以及在社会核心层面建立接受度的战场。性教育的进步正在受到根本性的挑战。教师们报告称,他们害怕在匈牙利课堂上提到 SOGIESC;荷兰有 36 所正统学校要求学生和家长发表反 LGBTI 声明;比利时的“成就目标”被推翻,中学教育课程中没有 SOGI。塞尔维亚计划修改讨论多样性的生物学书籍。意大利新任右翼总理乔治亚·梅洛尼公开主张禁止学校进行性教育,并在儿童读物中排除 LGBT 人群;而英国政府则向学校施压,要求其撤回支持跨性别学生的指南。

神经科学培训项目(NTP)
介绍哺乳动物神经系统的解剖学和生理学。讲座将涵盖人类大脑主要分支、主要感觉和运动系统以及高级功能的神经解剖学。实验室/讨论部分将强调阅读主要文献和动手解剖。必备条件:NEURODPT/NTP 610 或研究生/专业地位课程名称:级别 - 高级 L&S 学分 - 计入 L&S 研究生 50% 的文科和理科学分 - 计入 50% 的研究生课程要求可重复获得学分:否上次授课:2025 年春季学习成果:1. 描述哺乳动物神经系统的组织和结构,包括脊髓、脑干、丘脑、大脑皮层、小脑、基底神经节、边缘系统及其在系统层面上的互连受众:研究生和本科生