XiaoMi-AI文件搜索系统
World File Search SystemSFT

独脚金内酯通过诱导 miR319- LA 促进开花
独脚金内酯是一类植物激素,在植物发育、应激反应和与根际(微生物)生物的相互作用中发挥各种功能。虽然它们对营养发育的影响已被充分研究,但人们对其在生殖中的作用知之甚少。我们研究了基因和化学改造独脚金内酯水平对番茄 (Solanum lycopersicum L.) 开花时间和强度的影响,以及这种影响背后的分子机制。结果表明,无论是内源的还是外源的,地上部独脚金内酯水平都与开花时间呈反比,与花朵数量和叶片中成花素编码基因 SINGLE FLOWER TRUSS (SFT) 的转录水平呈正相关。转录本定量结合代谢物分析表明,独脚金内酯通过诱导叶片中 microRNA319 - LANCEOLATE 模块的激活来促进番茄开花。这反过来又降低了赤霉素含量并增加了 SFT 的转录。用独脚金内酯处理后,顶端分生组织中会诱导出几种其他花标记和发育进程的形态解剖特征,从而影响花的转变,更明显地影响花的发育。因此,独脚金内酯通过诱导花转变前后的 SFT 来促进分生组织的成熟和花的发育,而它们的作用在表达 miR319 抗性 LANCEOLATE 的植物中被阻断。我们的研究将独脚金内酯置于模型作物物种的开花调控网络的背景下。
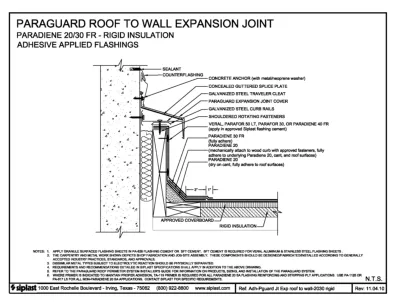
PARAGUARD 屋顶至墙壁伸缩缝
注意事项:1.使用 PA-828 防水水泥或 SFT 水泥涂抹颗粒表面防水板。各种铝和不锈钢防水板均需使用 SFT 水泥。2.所示的木工和金属加工描绘了车间制造和工地组装。这些组件应根据普遍接受的行业惯例、标准和批准进行设计、制造和安装。3.受电解反应影响的不同金属类型应进行物理分离。4.除上述图纸外,还应适用 SIPLAST 规格中详述的要求和建议。5.有关 PARAGUARO 系统的产品、尺寸和安装的信息,请参阅 PARAGUARO 屋顶周边系统安装指南。6.如果需要使用底漆来保持适当的附着力,则所有 PARADIENE 20 SA 防水加固和剥离层应用都需要使用 TA-119 底漆。使用 PA-1125 或

构建系统收敛的途径?
○我们共同努力,改善了满足我们所有要求的通用工具。○SFT构建通用,HEPMC,仿真,分析和ML软件包组,并在CVMFS上分发它们,专门优化该工具,以使用CVMFs作为软件和可重复使用的产品的有效分发渠道。○使用相同工具的实验添加和维护其存储库,同时从共享的包装构建配方中受益。○不同的CI管道同时运行(可能在相同的共享构建基础架构上),优化了人力和计算资源的使用情况。○每个人都快乐

通过实验反馈
蛋白质语言模型(PLM)已成为用于蛋白质序列设计的最先进工具。plms并没有固有地设计具有超出自然界的功能的新序列,这表明了与蛋白质工程的未对准,该目标是重新设计具有增强功能的蛋白质序列的蛋白质工程目标。在自然语言处理领域,通过人类反馈(RLHF)的强化学习使大型语言模型Chat-gpt通过监督的微调(SFT)和近端政策优化(PPO)使首选响应一致。我们使用实验数据适应了SFT和PPO来对PLM的功能排列,并使用实验反馈(RLXF)调用此方法增强学习。我们使用RLXF将ESM-2和生成的变分自动编码器对齐,以设计与氧无关的荧光蛋白Creilov的5个突变体变体。我们发现,对齐的ESM-2的设计较大,具有活性,至少与Creilov一样明亮,并带有体内荧光测定。我们将RLXF作为一种多功能方法,用于使用实验数据重新设计实验数据在功能上对齐PLM。

2023年德克萨斯州国际博览会的经济影响
表3运营和资本支出直接间接诱发次县总县的财政影响$ 1,430,753 $ 127,279 $ 385,936 $ 385,936 $ 1,943,968 Sub County Special Districts $ 2,362,057 $ 163,657 $ 823,637州$ 4,810,072 $ 432,311 $ 1,301,801 $ 6,544,185联邦政府$ 10,305,654 $ 1,716,985 $ 3,985 $ 3,915,105 $ 6,403,865 $ 28,459,274资料来源:SFT财务数据

大语言扩散模型
自回旋模型(武器)被广泛地成为大型语言模型(LLMS)的基石。我们通过介绍LLADA挑战了这一概念,这是一种扩散模型,该模型在训练和监督的细调(SFT)范式下从头开始训练。llada通过向前数据掩盖过程和反向过程进行分散模型,该过程由香草变压器参数列出以预测掩盖的令牌。通过操作可能性结合的可能性,它为概率引发提供了一种限制的生成方法。在广泛的基准测试中,Llada表现出强大的可伸缩性,表现优于我们的自我建造的手臂基线。明显地,LLADA 8B具有强大的LLM,例如LLAMA3 8B在秘密学习中,并且在SFT之后,在诸如多转变型号之类的案例研究中表现出令人印象深刻的跟随能力。此外,Llada解决了诅咒,在逆转诗的完成任务中超过了GPT-4O。我们的发现将扩散模型建立为武器的可行且有前途的替代方案,挑战了上面讨论的关键LLM功能固有地与武器相关的假设。项目页面和代码:https://ml-gsai.github.io/llada-demo/。

从演示和偏好共同学习奖励和政策可以改善一致性
与人类的偏好和/或意图保持一致是当代基础模型的重要要求。为了确保对准,诸如人类反馈(RLHF)等流行方法将任务分为三个阶段:(i)基于大型示范数据的监督微调(SFT)计算的模型,(ii)基于人类反馈数据和(III II)的估计,(ii)将使用(III)估算了(ii II),以进一步的模型(RL)进一步估算了该模型(RL)。演示和人类反馈数据以不同的方式反映了人类用户的偏好。结果,仅从人类反馈数据获得的奖励模型估计可能不如从演示和人类反馈数据获得的奖励模型估计值那么准确。一种优化从演示和人类反馈数据获得的奖励模型估计值的政策模型可能会表现出更好的对齐性能。我们引入了一种可访问的算法,以找到奖励和政策模型并提供有限的时间绩效保证。此外,我们通过广泛的实验(包括LLMS中的比对问题和Mujoco中的机器人控制问题)来证明所提出的解决方案的效率。我们观察到,所提出的解决方案的表现优于现有的对齐算法。
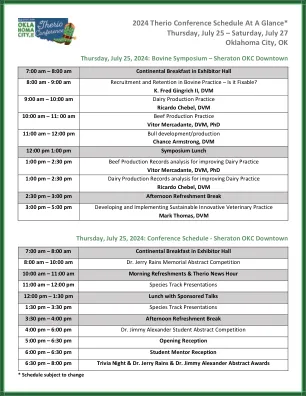
2024 THE THE THERIO会议时间表*星期四...
上午10:00 - 11:00 AM SFT商务会议11:00 AM - 12:00 PM ACT商业会议12:00 PM - 1:30 PM午餐和海报摘要摘要摘要摘要问答问答,下午1:00 - 5:00 PM物种轨道赛道播放6:00 pm - 9:00 pm therio therio Foundation sundown Sundown sundown Soiree在National Cowboy&Western cowboy&Western Heritage Museum * tf sunieree trve <<
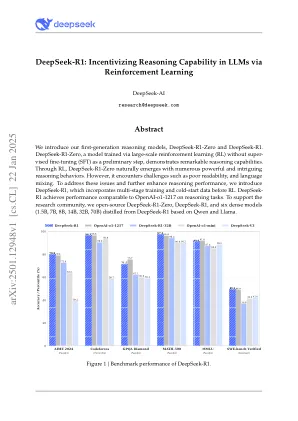
DeepSeek-R1:通过增强学习激励LLM中的推理能力
我们介绍了第一代推理模型,即DeepSeek-R1-Zero和DeepSeek-R1。DeepSeek-R1-Zero,一种通过大规模增强学习(RL)训练的模型,没有超级微调(SFT)作为初步的步骤,表现出显着的推理能力。通过RL,DeepSeek-R1-Zero自然出现,具有许多强大而有趣的推理行为。但是,它遇到了挑战,例如不良的可读性和语言混合。为了解决这些问题并进一步提高了推理性能,我们引入了DeepSeek-R1,该问题在RL之前结合了多阶段培训和冷启动数据。DeepSeek-R1在推理任务上实现与OpenAI-O1-1217相当的性能。为了支持研究社区,我们开放源DeepSeek-R1-Zero,DeepSeek-R1和六种密集的型号(1.5b,7b,8b,8b,14b,32b,32b,70b),根据Qwen和Llama蒸馏出了DeepSeek-R1。

教务委员会人工智能工作组
教务委员会人工智能工作组 人工智能技术 (AI) 的出现带来了许多挑战和机遇,影响着所有学科的高等教育。斯托克顿大学最近与教学设计中心 (CTLD) 采取了初步行动,在教学大纲中提供了在课程中可能使用 AI 的预测。在 8 月 31 日由 SFT 赞助的研讨会上以及 2023 年 9 月 1 日举行的秋季教师会议上,教师们还表示需要研究 AI 与学术、教学法和学术诚信的关系。决定教务委员会组建一个由教师领导的工作组,让斯托克顿校园社区参与进来,考虑如何将 AI 技术可持续地融入我们的工作中。由于 AI 的复杂性及其在高等教育许多方面的应用,该工作组将负责: