XiaoMi-AI文件搜索系统
World File Search SystemSegment

Genelec是新芬兰Arthouse Cinema
5.x1如FASB ASU 2023-07,FASB ASC 280的“背景信息和结论基础”背景信息部分的BC6段所述。该指南要求通用财务报表包括使用称为管理方法的方法准备的细分信息。管理方法要求基于管理层如何在公共实体内部组织细分市场来报告细分信息,以分配资源和评估绩效。该方法允许财务报表用户通过管理的眼睛看到有关实体的分类信息,并以管理对其进行审查的方式评估细分市场的性能。



中等功率段的风冷发射机
新型风冷 R&S ® NH/NV8200 发射机系列(图 1)专为所有模拟电视标准(B/G、D/K、M/N、I、SECAM、PAL、NTSC)以及所有数字电视标准(DVB-T、DVB-H、ATSC 等)而设计。放大器中的 LDMOS 晶体管可确保高输出功率,同时仅占用最小的空间。与往常一样,所有组件在 UHF 频段 IV/V(470 MHz 至 862 MHz)内都是全宽带的,适用于模拟和数字电视,没有任何限制。一项特殊的创新是最先进的电视激励器 R&S ® Sx800,它仅占用一个高度单位。

可持续发展目标 8 的行动部分
为应对这些挑战和推进可持续发展目标 8,已建立了多项伙伴关系。“公平转型就业和社会保护全球加速器”致力于促进绿色、数字和护理经济中的体面劳动,同时将社会保护扩大到受排斥的人群。“体面劳动生产力生态系统”计划旨在解决生产力增长的制约因素,促进体面就业。工发组织学习与知识发展基金(LKDF)采用公私发展伙伴关系方式,通过针对发展中国家青年和妇女的工业技能发展,促进生产性就业和经济增长。全球社会正义联盟联合了 300 多个合作伙伴,倡导多边合作,加速可持续发展目标的进展。作为这些努力的补充,国际劳工组织人工智能与数字经济劳动观察站充当知识中心,支持政府和社会伙伴管理工作数字化转型。

半乳糖苷酶片段至氨基末端片段...
我们报告了一系列适用于检测和克隆翻译控制信号和外源基因 5' 编码序列的质粒载体的构建和使用。在这些质粒中,乳糖操纵子 β-半乳糖苷酶基因 lacZ 的氨基末端的前八个密码子被去除,并在 lacZ 的第八个密码子附近插入独特的 BamHI、EcoRI 和 SmaI (XmaI) 内切酶切割位点。将含有适当调节信号和 5' 编码序列的脱氧核糖核酸片段引入此类 lac 融合质粒导致产生由 β-半乳糖苷酶残基的羧基末端片段和含有外源脱氧核糖核酸序列编码的氨基末端氨基酸的肽片段组成的混合蛋白。这些杂合肽保留了 1,8-半乳糖苷酶的酶活性,并产生了 Lac' 表型。此类杂合蛋白可用于纯化由外源脱氧核糖核酸片段编码的肽序列,以及用于研究特定肽片段的结构和功能。

IT 和技术服务部门 | MDA
à 一家为高科技行业提供定制设施设计、工程和交付的全球领导者已选择 LTIM 作为其未来五年数字化转型之旅的首选战略合作伙伴 à 一家美国顶级石油和天然气生产商选择 LTIM 作为其端到端技术服务的战略合作伙伴 à 一家多元化的跨国大众媒体公司已选择 LTIM 作为其首选的 ServiceNow 转型合作伙伴 à 一家全球金融服务技术公司已选择 LTIM 进行产品开发计划 à 中东一家公用事业公司继续加强与 LTIM 的关系,签署了另一份为期 3 年的协议,该公司将通过确定扩展领域和优化技术格局来支持他们的转型之旅 à 全球最大的半导体制造商之一已选择 LTIM 作为其关键的数字化转型合作伙伴,以实现其 SAP 应用程序环境的现代化,丰富用户体验,简化业务流程,并在 SAP S/4HANA 和 SAP 云解决方案中提供现代化的数字化运营 à 美国最大的财产和意外伤害保险公司之一已选择 LTIM 作为战略合作伙伴,签订了一份多年的应用程序开发和维护协议一家知名监管机构选择 LTIM 作为其下一代数据仓库实施方案
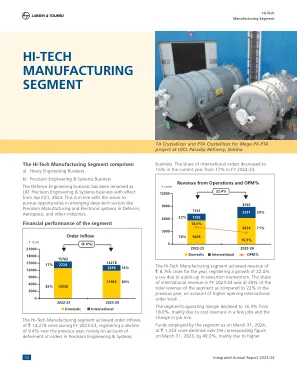
高科技制造部门| MDA
设备,液化天然气/气体加工压力容器和重型柱 - 热传输设备(HTE)PBU专门针对熔融盐反应堆系统,氨和尿素交换器,高压螺丝插头插头热交换器,甲醇转换器,丙烯丙烯(PO),丙烯(PO)反应堆,乙酸含量植物(VAM)反应器(VAM)反应器(VAM)零件(VAM)零件(VAM)零件(VAM)零件(VAM),锅盘(VAM)零售店(Vam) PBU专门从事反应堆和氨转化篮的专有内部质量,用于多硅植物的化学蒸气沉积(CVD)反应器,这些反应器是使用不锈钢,双层/超级双层不锈钢,Inconel,Inconel,Monel,Monel,Hastelloy,Titanium,Titanium,Titanium,Titanium,piTanium,pik> à The Modification, Revamp & Upgrade (MRU) PBU offers value-added end-to-end solutions for FCC (Fluid Catalytic Cracking) revamps, Crude Distillation Unit/ Vacuum Distillation Unit revamps, Multi-Shutdown Facility revamps, Urea Reactor Life extension, Coke Drum repairs, Heat Exchanger revamp, Urea energy-saving projects, debottlenecking/capacity加强石油和天然气单元和工艺工业的紧急维修 - 核PBU专门为核电厂中的蒸汽供应系统提供关键设备。 它制造了核岛的关键组成部分,例如蒸汽发生器,末端盾牌,压力箱,安全热交换器,反应堆标头组件,卡兰德里亚,末端配件等。 à特殊制造单元(SFU)制造了关键的钛管阀,气化厂的复杂内部,循环反应堆,初级淬火式交换机(PQE)和石油化学部门的滤清器à The Modification, Revamp & Upgrade (MRU) PBU offers value-added end-to-end solutions for FCC (Fluid Catalytic Cracking) revamps, Crude Distillation Unit/ Vacuum Distillation Unit revamps, Multi-Shutdown Facility revamps, Urea Reactor Life extension, Coke Drum repairs, Heat Exchanger revamp, Urea energy-saving projects, debottlenecking/capacity加强石油和天然气单元和工艺工业的紧急维修 - 核PBU专门为核电厂中的蒸汽供应系统提供关键设备。它制造了核岛的关键组成部分,例如蒸汽发生器,末端盾牌,压力箱,安全热交换器,反应堆标头组件,卡兰德里亚,末端配件等。à特殊制造单元(SFU)制造了关键的钛管阀,气化厂的复杂内部,循环反应堆,初级淬火式交换机(PQE)和石油化学部门的滤清器

2023 财年各部门业绩
当前的经营环境和举措 纤维与纺织品业务的经营环境依然严峻,受美国和欧洲消费者支出放缓和中国经济低迷的影响,原本有望复苏和扩张的业务也举步维艰。其他因素包括原材料和燃料价格高企和通货膨胀导致的成本上升,以及以大宗商品市场为中心的竞争加剧。此外,鉴于需要解决全球环境问题,企业面临着越来越大的可持续发展压力,因此必须毫无疑问地加速向可持续材料的转变。在这种经营环境下,AP-G 2025 提出的纤维与纺织品业务的主要举措是 (1) 通过最终价值创造提高盈利能力,(2) 基于使用环保材料的高性能、高纹理产品在增长领域的业务扩张,以及 (3) 卓越产品和卓越运营。

航空应用用户群
混合架构称为地面区域增强系统 (GRAS)。基于飞机的方法采用内置于用户航空电子设备中的监视器,不需要外部基础设施(GNSS 卫星本身除外)。这些监视器通过检测危险误导信息 (HMI) 实例(指任何威胁性 GNSS 异常)来构建严格的误差界限。与基于飞机的方法相比,其他类型的增强系统都采用地面参考接收器基础设施。这些接收器网络增强了 HMI 监控的灵敏度。此外,这些网络能够广播差异校正,从而显着提高用户准确性。图 1 显示了所有四类增强系统。ABAS 具有明显的优势,因为它几乎可以在任何可以看到 GNSS 卫星的地方使用。虽然 ABAS 可能包含非 GNSS 传感器,但 ABAS 的一个重要子类别是仅 GNSS 的 RAIM。这种方法使用导航解决方案的最小二乘残差来实现监控。较大的残差对应于与其他测量值不同的测量值。通过从导航解决方案中排除不同的卫星测量值,RAIM 可以检测到较大的 HMI 事件,从而可以对导航传感器误差建立更严格的置信界限。为了获得非零残差,RAIM 至少需要一次