XiaoMi-AI文件搜索系统
World File Search SystemSegment
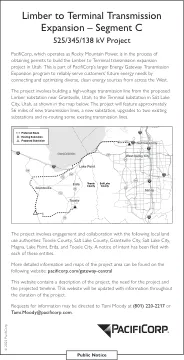
灵活至终端输电扩建 - C 段
该项目涉及从犹他州格兰茨维尔附近的拟建林伯变电站到犹他州盐湖城的终端变电站修建一条高压输电线,如下图所示。该项目将包括约 56 英里的新输电线、一个新变电站、对两个现有变电站的升级以及重新布置一些现有输电线。

伽利略地面控制段挑战被带到了...
还必须提到所有相关公司的共同部门,他们使得在一夜之间改变工作方式成为可能,他们能够提供继续有效工作的手段和工具,他们确保了连接和访问,通常冒着个人健康风险。我们不应忘记那些勇敢的员工,他们不得不面对疫情风险,留在公司场所进行实验室工作或管理机密材料和文件,或者不得不出差来支持部署活动,这些活动始于第一波新冠疫情期间,并持续到 2021 年夏季的后续波次。

RFP附录A-1.6 - 电池能量存储...终端传输扩展的肢体 - 段C
2024年3月21日下午5:00下午7:00湖角消防局1528 Sunset Road Tooele,UT 84047更多详细信息和项目区域的地图,请访问以下网站:Pacificorp.com/gateway- Central。该网站包含项目的描述,即对项目的需求和预测的时间表。本网站将在整个项目期间更新信息。请求请求可以通过(801)220-2217或tami.moody@pacificorp.com向Tami Moody致电Tami Moody。

神经网络是学习时间段的模型...
本文提出了一种新颖的学习方法,用于复发神经网络(RNN)专家模型的混合,该模型可以通过在专家之间动态切换来获取生成所需序列的能力。我们的方法基于使用梯度下降算法的最大似然估计。此方法类似于常规方法中使用的方法。但是,我们通过添加一种机制来改变每个专家的差异来修改似然函数。所提出的方法被证明是成功地学习了一组9个Lissajous曲线之间的Markov链切换,而常规方法会失败。根据所提出的方法的概括能力分析的学习绩效也被证明优于常规方法。随着添加门控网络,该提出的方法成功地应用于小型类人机器人的感觉 - 运动流,作为时间序列预测和生成的现实问题。©2008 Elsevier Ltd.保留所有权利。

高级细分市场:蓝色经济的脱碳机会和挑战
海上运输对全球贸易至关重要,因为大约80%的全球商品贸易按数量持续。然而,海上运输是全球温室气体排放的重要贡献者。因此,国际海事组织(IMO)设定了目标,以减少国际运输中的温室气体排放。在需要时,它引起了人们的关注,因为缓解措施以实现这一目标可能会进一步加剧他们在较高的贸易成本方面的挑战,包括较高的货运率和SIDS和LDC的运输连接较低。尽管面临这些挑战,但通过多边框架,海上运输中的脱碳途径可以提供比仅仅通过全国范围的努力更快地提高排放量的机会。例如,正在围绕多边经济措施进行讨论,例如对运输排放的征税,可能会产生资金以支持最脆弱的经济体。

空间系统地面段数据分析探索
摘要。空间系统必须处理由空间和地面传感器收集的大量时空地球和空间观测数据。尽管通信中存在数据延迟,但数据收集速度非常快,并且建立了复杂的地面站网络来收集和存档遥测数据。地面部分接收到的数据可以提供给最终用户。除了存档数据之外,可用数据还为数据分析提供了机会,可以支持决策过程或为目标需求提供新的见解。不幸的是,对于从业者来说,识别空间领域数据分析的潜力和挑战并不容易。在本文中,我们反思并综合了现有文献的发现,并为在空间系统环境中建立和应用数据分析提供了综合概述。为此,我们首先介绍空间系统中采用的流程,并描述数据科学和机器学习过程。最后,我们确定了可以映射到数据分析问题的关键问题。

Nemak宣布在EV/SC细分市场中裁员
墨西哥蒙特雷。2024年12月30日。Nemak,S.A.B。 de C.V. (BMV:NEMAK)(“ Nemak”或“ Company”)今天宣布了对其运营和项目计划的战略调整,用于为奖励业务生产全电动汽车的电池壳体。 此调整涉及该项目的合同能力降低,这将导致该计划在电子操作性,结构和机箱应用程序(“ EV/SC”)细分市场中预期的未来收入减少。Nemak,S.A.B。de C.V. (BMV:NEMAK)(“ Nemak”或“ Company”)今天宣布了对其运营和项目计划的战略调整,用于为奖励业务生产全电动汽车的电池壳体。此调整涉及该项目的合同能力降低,这将导致该计划在电子操作性,结构和机箱应用程序(“ EV/SC”)细分市场中预期的未来收入减少。

打造 AI 就绪型组织的 10 个基本步骤 - Segment
• 最终,不良数据会导致糟糕的客户体验、忠诚度下降和收入损失。在我们依赖人工智能来改善客户体验和推动增长的世界中,我们必须努力获得高质量的数据,作为准确预测、个性化互动和明智决策的基石。没有它,企业就有可能损害其人工智能计划的有效性。

洞察细分市场的人工智能进步 - 2024 年第三季度
• Dig Insights 的 Upsiide AI 创意生成器利用生成式 AI 来改进洞察生成,并为产品、功能和标语提供新颖的概念。• Dig 使用基于 NLP 的 AI 工具来总结来自开放式研究问题的定性消费者反馈,提取主要主题和关键思想。• Dig 还在其 Upsiide 平台内开发了一个 AI 主持的视频收集模块,可大规模提供定性反馈和分析。• Dig 甚至开发了 Upsiide 的开放文本分析平台等工具,该平台彻底改变了情绪分析,利用 AI 来增强主题识别并通过非结构化数据分析解码消费者行为。• Dig 的 Story Teller Platform 目前正在开发中,它将通过 AI 辅助报告和分析个性化结果和洞察的交付。

使用任意片段模型分析微生物样本
细菌、真菌、病毒、酵母和原生动物等微生物污染物引起了食品制造商的极大兴趣和担忧,因为它们可能存在食物中毒或食物腐败的风险(Maruthamuthu 等人,2020 年)(Talo,2019 年)。对数字微生物数据的需求不断增长,为微生物学家和实验室专业人员提供了轻松检测微生物的机会(Egli 等人,2020 年)。这种变化可以个性化诊断和治疗,提高数字数据质量,并降低医疗成本。传统的基于培养的微生物检测方法非常耗时,而数字成像因其快速的方法而备受关注。数字微生物学还有可能对公共卫生和病原体监测产生重大影响。为了实现数字化,微生物实验室必须发展数字医学和食品分析方面的专业知识,包括数据处理、感知和基础设施(Soni 等人,2022 年)。近年来,计算机视觉、人工智能 (AI) 和机器学习 (ML) 等在大量标记数据上进行训练的方法越来越多地用于自动分析医学图像和微生物样本 (Goodswen et al., 2021)。这些方法可用于识别四种不同类型的微生物:细菌、藻类、原生动物和真菌 (Rani et al., 2022)。卷积神经网络和 ResNet-50 等模型可用于确定微生物样本的类别 (Majchrowska et al., 2021) (Rani et al., 2022) (Talo, 2019)。语义分割是一种计算机视觉方法,用于分析微生物样本的图像,当需要根据语义含义精确确定图像的不同区域时,为图像中的每个像素分配一个类标签 (Zawadzki et al., 2021)。 Faster R-CNN 和 Cascade R-CNN 等模型可用于计数微生物样本图像中的细菌菌落,这些模型可以检测单个物体并确定其类别。实例分割方法旨在通过区分图像中单个细菌菌落的不同实例并将每个像素分配给唯一的菌落来提供对图像的详细理解(Zawadzki 等人,2021 年)。Meta 公司开发和训练的 Segment Anything Model (SAM) 用于图像分割(实例分割)(Kirillov 等人,2023 年)。该模型使用超过 10 亿个掩模对 1100 万张图像进行了训练。SAM 模型具有零样本泛化的可能性,因此无需额外训练即可用于图像中对象的分割。SAM 模型可以分析来自广泛领域的图像,包括生物医学、农业、自动驾驶等。2. 方法