XiaoMi-AI文件搜索系统
World File Search SystemTeNS

量子Hoare类型理论
状态崩溃在观察状态时。模拟超过数十个量子位是昂贵或不可能的。在物理量子计算机上运行程序的成本很高;如果我们运行不正确的程序会变得更糟。因此,重要的是在静态上确保正确性。

人工智能加速器(Tensor Processor)的翻译器
该客户专门开发和制造专用张量处理单元 (TPU),用于基于矩阵乘法块的快速神经网络计算,它以每周期数万次运算的速度执行最耗资源的计算。

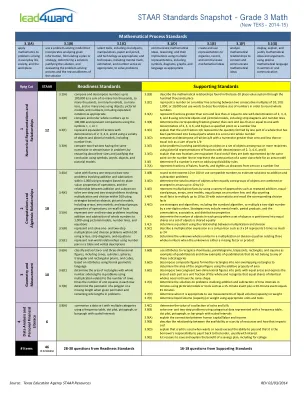
STAAR 标准概览 - 三年级数学
3.2(A) 使用实物、图形模型和数字(包括适当的扩展符号),将 100,000 以内的数组成和分解为多少个万、多少个千、多少个百、多少个十和多少个一的总和

诚信至上:企业、金融机构、城市和地区的净零承诺
中国经历了 60 年来最干旱的夏天,长江水位缩减至原来的一半。与此同时,巴基斯坦遭受洪水侵袭,三分之一国土被淹没,3000 多万人流离失所。佛罗里达州西南墨西哥湾沿岸遭受了一场猛烈的飓风袭击,而西欧则遭遇了夏季的最高气温。此外,非洲之角的数千万人面临严重的粮食短缺。总而言之,这些和其他气候灾害造成了数万亿美元的损失,数千万人流离失所。今年迄今为止,已发生 29 起损失超过 10 亿美元的灾害。损失的不仅是人类,还有大自然。在过去五十年里,由于气候变化和其他人类活动,全球野生动物数量下降了近 70%。

评估加州的气候政策——发电
RPS 可能成为以适中的每吨成本实现减排的重要驱动因素。根据一些“粗略”计算,我们估计可再生能源组合标准 (RPS) 计划 (1) 在 2018 年将年度排放量减少了数千万吨,并且 (2) 每减少一吨能源采购成本约为 60 至 70 美元。各种其他成本(例如传输和集成成本)难以量化,但可能会使每吨成本增加数十美元。尽管该计划可能产生其他好处(例如减少当地空气污染物并促进全球太阳能价格下降),但这些影响的程度似乎相对较小。重要的是,未来增加可再生能源发电的成本可能与过去的成本大不相同。这是因为由于可再生能源价格下降,未来可再生能源的采购成本可能会低得多,但这至少可能会被更高的集成成本部分抵消。

无标记的非电源癌细胞...
基于CMOS的微电极阵列(CMOS MEAS)包含数千个密集的传感器位点,并且通常用于生物技术应用中,以记录高空间(几乎没有……几十µm)和高时间分辨率的神经元活性和高度分辨率(高达20 kHz带翼)。CMOS MEAs能够以几毫秒数的时间精度和数十微米的空间精度刺激活性[1-3]。未开发的CMOS MEA的应用是它们通过记录和分析由电阻粘附裂隙引起的电压噪声来检测粘附细胞的能力[4-6]。这可能归因于该方法,该方法需要考虑传感器位点的规模,粘附单元的大小,连接电容和相应的采样频率。在这里,我们采用两种不同类型的CMOS MEA和相应的记录系统来评估其可靠的无标签检测能力检测粘附细胞培养的能力(癌细胞系HT-29)。细胞粘附电压噪声通过光谱功率密度(S V)分析。


随机性,交换性和保形预测
随机性的功能理论是在Vovk [2020]中以非算力的随机性理论的名义提出的。Ran-Domness的算法理论是由Kolmogorov于1960年代启动的[Kolmogorov,1968年],并已在许多论文和书籍中开发(例如,参见Shen等人。2017)。它一直是直觉的强大来源,但其弱点是对特定通用部分可计算函数的选择的依赖性,这导致其数学结果中存在未指定的加性(有时是乘法)常数。Kolmogorov [1965,Sect。 3] speculated that for natural universal partial computable functions the additive constants will be in hun- dreds rather than in tens of thousands of bits, but this accuracy is very far from being sufficient in machine-learning and statistical applications (an addi- tive constant of 100 in the definition of Kolmogorov complexity leads to the astronomical multiplicative constant of 2 100 in the corresponding p-value). 与VOVK [2020]中提出的未指定常数打交道的方式是表达有关随机性算法作为各种函数类之间关系的算法。 它将在教派中引入。 2。 在本文中,我们将这种方法称为随机性的功能理论。 虽然它在直观的简单性方面失去了一定的损失,但它越来越接近实用的机器学习和统计数据。 读者将不会假设对随机性算法理论的形式知识。 在本文中,我们有兴趣将随机性的功能理论应用于预测。 3。Kolmogorov [1965,Sect。3] speculated that for natural universal partial computable functions the additive constants will be in hun- dreds rather than in tens of thousands of bits, but this accuracy is very far from being sufficient in machine-learning and statistical applications (an addi- tive constant of 100 in the definition of Kolmogorov complexity leads to the astronomical multiplicative constant of 2 100 in the corresponding p-value).与VOVK [2020]中提出的未指定常数打交道的方式是表达有关随机性算法作为各种函数类之间关系的算法。它将在教派中引入。2。在本文中,我们将这种方法称为随机性的功能理论。虽然它在直观的简单性方面失去了一定的损失,但它越来越接近实用的机器学习和统计数据。读者将不会假设对随机性算法理论的形式知识。在本文中,我们有兴趣将随机性的功能理论应用于预测。3。机器学习中最标准的假设是随机性:我们假设观察值是以IID方式生成的(独立且分布相同)。先验弱的假设是交换性的假设,尽管对于无限的数据序列而言,随机性和交换性证明与著名的de Finetti代表定理本质上是等效的。对于有限序列,差异是重要的,这将是我们教派的主题。我们开始讨论在教派中预测的随机性功能理论的应用。2。在其中介绍了置信度预言的概念(稍微修改和推广Vovk等人的术语。2022,Sect。2.1.6)。然后,我们根据三个二分法确定八种置信预测因素:
