XiaoMi-AI文件搜索系统
World File Search SystemVariance

方差和时间方差*
表格中的 edf 和置信因子按以下方式获得:N =l,OW,m = 128,M = 1025-3~128+1 = 642(估计中的加数数量),q = M/m =5.0156,= 1.225,ul = 0.589 来自'IBble I,edf = 6.9617 来自等式 (4)。对于 95% 的置信度,我们需要计算 2.5% 和 975% 的卡方水平。逆卡方算法,Y = 6.9617 和 p = 0.025,给出 2 = 1.6720 作为 25% 水平,在公式 (2) 中用 a 表示。同样,97.5% 水平为 15.928,用 b 表示。计算出的置信因子为 1 - = 03389,m- 1 = 1.0405。(请注意,表 I1 中的值是根据和 al 的值计算出来的,这些值的有效数字比表 I 中给出的值要多。)

方差分析
深度学习(DL)培训算法利用非确定性来提高模型的准确性和训练效率。因此,多个相同的培训运行(例如,相同的培训数据,算法和网络)产生了具有不同准确性和训练时间的不同模型。除了这些算法因素外,由于并行性,优化和浮点计算,dl libraries(例如Tensorflow和Cudnn)还引入了其他方差(称为实现级别差异)。这项工作是第一个研究DL系统差异以及研究人员和实践中这种差异的认识的工作。我们在三个具有六个流行网络的数据集上进行的实验显示了相同的培训运行中的总体准确性差异。即使排除了弱模型,精度差也为10.8%。此外,仅实施级别的因素会导致相同培训运行的准确性差异高达2.9%,每类准确性差异高达52.4%,训练时间差为145.3%。所有核心库(Tensorflow,CNTK和Theano)和低级库(例如Cudnn)在所有评估版本中均显示实现级别的差异。我们的研究人员和从业人员的调查显示,有83.8%的901名参与者不知道或不确定任何实施级别差异。此外,我们的文献调查显示,最近顶级软件工程(SE),人工智能(AI)和系统会议中,只有19.5±3%的论文使用多个相同的培训运行来量化其DL AP-ap-paraches的方差。本文提高了对DL差异的认识,并指导SE研究人员执行诸如创建确定DL实现之类的挑战任务,以促进调试和提高DL软件和结果的可重复性。

附录 A:变更请求
• 提出请求之前,请先检查是否已为该主题提供了解决方案: o VHA HEFP EHRM - 解决方案交付指导文件 (sharepoint.com) o VHA HEFP EHRM - 设计警报 (sharepoint.com) • 通过 EHRM HEFP SEP 网络基础设施项目站查询 (SI 工具) 请求 EHRM 差异:医疗保健工程 - 主页 (sharepoint.com) • 提交 EHRM HEFP SEP 网络基础设施项目站查询 - 工作帮助.pdf。 • 将所有其他请求发送至:OIT 数据中心和基础设施工程 (DCIE) VAITESEDatacenterEngineering2@va.go v。 • 主题行:包括站/站点名称_VISN XX_项目编号_EHRM(如果适用)_高级项目描述_差异请求_(请求性质)。 • 示例:Bronx NY_VISN 10_10-369_EHRM_Remodel MCR_Variance Request_(Power)。提交者必须在 Outlook 的“选项”标题下对电子邮件进行数字签名。

差异或 HAACP 计划
a) 食品上应有标记,或以其他方式明确标识,标明食品脱离温度控制后的时间已超过四小时;b) 食品应在脱离温度控制后四小时内烹制并上桌、可立即食用后上桌或丢弃;c) 装在未标记的容器或包装中或装在标记的容器中,超过四小时限制的食品必须丢弃;d) 食品企业应制定书面程序,确保遵守上述 a、b 和 c 项以及《休斯顿食品条例》第 20.21.3(b)(2) 节关于在作为公共卫生标准之前制备、烹制和冷藏的食品的规定。

HDANOVA:方差的高维分析 HIMA:高维中介分析 pqrbayes:贝叶斯惩罚分位数回归 rmonocypher:使用强现代密码学易于加密R对象 Photobiology.pdf 素食主义者:生态多样性 GDM:广义差异建模
apca。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。2 ASCA。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 3 ASCA_FIT 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。2 ASCA。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。3 ASCA_FIT。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。5 ASCA_PLOTS。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。7 ASCA_RESULTS。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。9块。data.frame。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。10热。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 11蜡烛。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 12个dummyCode。 。 。 。 。 。 。 。 。 。 。 。 。 。10热。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。11蜡烛。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。12个dummyCode。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。12 Extended.Model.Frame。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。13 limmpca。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。14 Model.Frame.asca。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。15 MSCA。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。16 PCANOVA 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 17个pcanova_plots。 。 。16 PCANOVA。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。17个pcanova_plots。。。。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>19 pcananova_ sensults。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>20个永久性。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>。 div>21中心。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。22时图。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。23 UPDATE_WITHOUT_FACTOR。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。24

附件 9——递延和差异帐户。......
本工作簿模型受版权保护,仅供您准备费率申请。您可以为此目的使用和复制本模型,并向任何为您提供建议或协助的人员提供本模型的副本。除上述情况外,未经安大略能源委员会书面同意,禁止复制、翻印、出版、销售、改编、翻译、修改、逆向工程或以其他方式使用或传播本模型。如果您向为您提供建议或协助准备或审查费率单草案的人员提供本模型的副本,您必须确保该人员理解并同意上述限制。

standa差异21-ECV-064-900-ESS/19-BCB
当前的C22.1:21 - 加拿大电气代码,第一部分还指出,ESS的使用电池应允许安装在电气设备库中,附录B注释表明,替代位置可能被视为与当地建筑物或消防安全密码官员或具有司法管辖权(AHJ)的适当权威的官员或适当的机构进行讨论。即使设备符合ANSI/CAN/UL 9540,ANSI/CAN/UL 90540A标准,位置,大小和间距仍应具有一组标准的限制。这些限制的主要目的是确保乘员有足够的时间和出口点,以便在发生大火时退出房屋。已通过加拿大住宅使用并经过认证的系统,并对ANSI/CAN/UL9540进行了测试,ANSI/CAN/UL 9540A现在存在。

可负担住房价格差异
a. 一套占地 200 平方米、步行 300 米即可到达阿德莱德地铁“Go Zone”巴士站的住宅,最高售价可达 544,500 澳元(495,000 美元 + 10% 的交通差异)。b. 一套环境可持续的“7 星级”住宅,最高售价可达 519,750 澳元(495,000 美元 + 5% 的环境差异)。c. 一套占地不到 250 平方米、步行 400 米即可到达阿德莱德地铁“Go Zone”巴士站的小型到中型住宅,该住宅被评估为 7 星级,售价为 569,250 澳元(495,000 美元 + 15% 的差异)。d. 一套位于大阿德莱德地区、价值 600,000 澳元的住宅,与 HomeStart Finance 共享股权一起出售。该房屋必须出售,并且必须强制要求符合条件的购房者使用共享股权贷款,因为售价超过了批准的价格点 544,500 澳元(495,000 澳元 + 10% 的融资差异)。e. 大阿德莱德地区一套 530,000 澳元的房屋,与 HomeStart Finance 共享股权相结合出售。该房屋可以出售,并可选择符合条件的
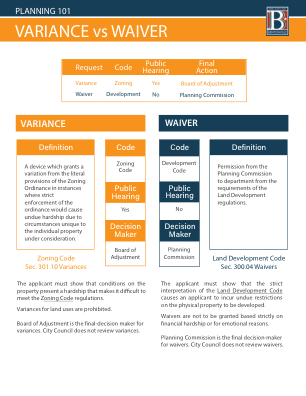
规划 101 - 差异与豁免
规划委员会可能会讨论该项目并向申请人提问。如果该项目是大型开发项目或初步规划的一部分,则将首先讨论和处理豁免问题。成员可以提出动议。如果随后有人附议,则将对该项目进行表决。动议可以是批准、有条件批准、拒绝或搁置。规划委员会对豁免采取最终行动。

神经网络的方差稳定优化
摘要 — 提出了一种基于测量变化特性和稳定性的神经网络训练新框架。该框架具有许多有用的属性,可以最大限度地利用数据,并以原则性的方式帮助解释结果。这是通过方差稳定和随后的标准化步骤实现的。该方法是一种通用方法,可用于任何有重复性数据的情况。以这种方式进行标准化可以量化拟合优度,并从统计角度解释测量数据。我们展示了该框架在先进制造数据分析中的实用性。索引词 — 方差稳定、神经网络、多层感知器、简化卡方、自由度卡方、金属增材制造在本文中,采用神经网络作为广义回归量,研究金属增材制造 (AM) 工艺参数与 IN718 超级合金的熔池几何特性之间的关系。本文以用例的形式介绍了增材制造数据的分析,但框架本身是通用的,可用于任何有可重复性数据的方法。增材制造是一种逐层构建组件的 3D 打印工艺;熔池是熔融原料和基材的体积。了解材料与熔池之间的潜在物理原理和关系是工艺优化的关键,然而现场测量的机会有限,因此缺乏对基本工艺的理解。使用神经网络分析先进制造工艺数据特别困难,因为收集高质量数据成本高、流程复杂且需要精心规划。这通常会导致数据集样本数量较少 [1]、[2],需要系统的方法来帮助进行可靠的解释。