XiaoMi-AI文件搜索系统
World File Search SystemWit

海军妇女倡议团队成立情况说明书 POC
为了通过建立更强大、更具包容性的作战队伍为海军做好战斗准备,并招募和留住来自美国各地的人才,本届海军管理委员会成立了海军妇女倡议小组 (Navy-WIT)。 海军妇女倡议小组 (Navy-WIT) 的目的是扩大认识并影响政策变化,以增加整个海军的女兵招募和留用。 海军妇女倡议小组将定期开会,以建立社区、制定最佳实践并讨论相关问题,从而为海军领导层消除性别障碍创造机会。 目前,国防部已设立妇女倡议小组,海军正在有意与该组织建立联系。虽然这不是一个新概念,但目前存在像妇女倡议小组这样的非正式临时组织,而没有确定和消除整个海军障碍所需的组织。 在发布本届海军管理委员会公告后的 60 天内,以下各指挥部应以书面形式指定一名军官(O4 及以上)和一名士兵(E7 及以上)海军妇女倡议小组企业负责人。任命文职雇员为海军 WIT 成员是可选的。任命和参与并非仅限于女性。 虽然领导职位仅限于上述级别,但任何人都可以成为海军 WIT 成员,无论级别如何,也无论他们是文职还是军人。
2020 年 3 月 1 日至 2020 年 6 月 30 日之间收到
他们与我以及任何被视为嫌疑人、相关人员或实际或潜在证人持有的与您在联邦刑事案件 (b )( 6) I 2 中被指控或控告的罪行有关的证据。政府与任何检方证人或其律师或代表之间就案件编号达成的任何口头或书面承诺、协议、谅解或安排的存在和实质,以及执行或履行的方式。Kb )( 6) I 其中政府已同意:(a) 不以任何罪行起诉证人;(b) 建议减轻指控。目前在任何司法管辖区待决的刑事诉讼中的证人; (c) 向任何司法管辖区的当局建议不对证人所犯的任何罪行或涉嫌罪行提出潜在指控; (d) 正式授予法定豁免权,或非正式保证证人不会因其提供的任何证词而受到起诉; (e) 建议对证人被定罪的任何罪行从轻量刑; (f) 建议对证人被定罪的任何罪行判处特定刑罚; (g) 为证人本人或其朋友或亲属提供优惠待遇或考虑,以换取证人的合作和证词; (h) 妥协或减少,或建议妥协或减少他或她所欠的任何联邦、州或地方税。3.任何代理人制作的所有手写笔记,包括但不限于与他们与您以及任何被视为有利益嫌疑的人或您在联邦刑事案件 N~(b)(6) 14 中被指控或控告或起诉的实际或潜在证人进行的任何采访、审讯和接触直接相关的笔记。参与此案的任何地方或州执法人员生成的所有调查报告。尤其是那些与任何被视为嫌疑人、相关人员或实际或潜在证人的人有过直接接触的人,这些证人是您被指控、指控或起诉的罪行。5.任何检察官或调查人员向被告提出、暗示或提出的所有认罪协议的副本,无论这些认罪协议是否被接受、提出或拒绝。6.与案件编号相关的 NCIC 犯罪历史记录副本。7.l( b ) (6) l 由州和联邦执法机构保存,记录在您和任何被视为嫌疑人、相关人员或您被指控的罪行的实际或潜在证人,在您被逮捕、指控或起诉的管辖范围内。政府判前调查报告 (PSR/PSI) 的完整副本。(记录搜索的日期范围:从 2015 年 1 月 1 日到 2020 年 2 月 6 日)。(记录搜索的日期范围:从 2015 年 1 月 1 日到 2020 年 2 月 6 日)

用地热热为农业食品链动力
从以下专家那里收到:HéctorMiguelAviña和Eduardo Pererez Gonzalez(墨西哥自主国立大学),Manon Stover(基准资本),Peter Omenda,Peter Omenda(顾问),艾滋病Ana Lucia Alfaro Murillo和Rafael Edgardo Parada Perez(Giz),GuðniAxelsson(Gro GTP),Cristian Irias(Honduras -sen),Volkanöztürk和Ufuk和地质),Maged Mahmoud(可再生能源和能源效率的区域中心-RRECEE),Luca Guglielmetti(日内瓦大学),Andre Ottir和Joeri Frederik de Wit(世界银行ESPARAP)。
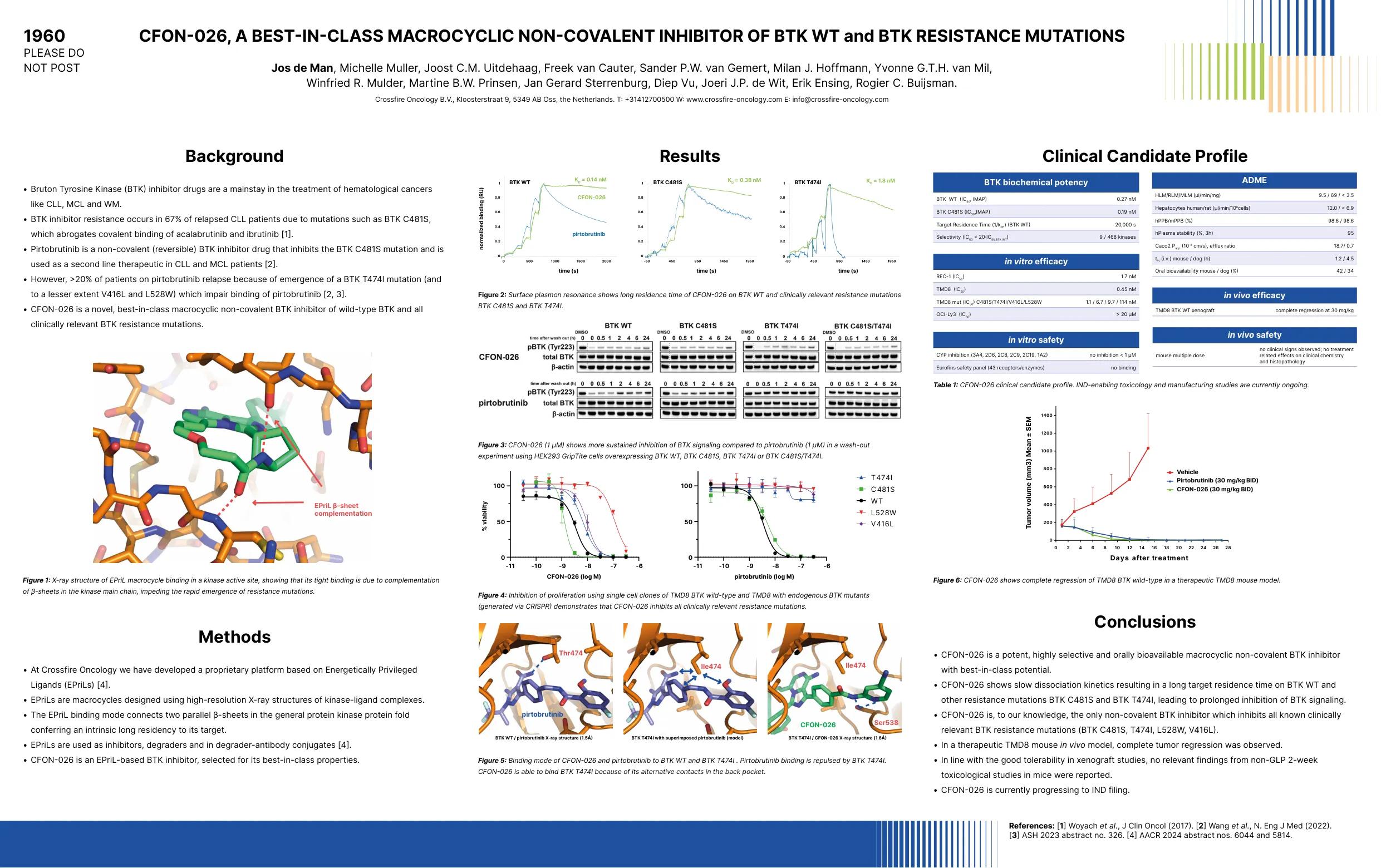
1960 CFON-026,一流的大环非...
Jos The Man,Michelle Muller,Joost C.M. 扩展,凯特(Cauter)的释放,桑德(Sander)P.W. <组,米兰J. Courtfmann,Yvonne G.T.H. Mill,Winfried R. Mulder,Martine B.W. 原则,Jan Gerard Sterrenburg,Deep V.P,Joeri J.P.白人,埃里克·恩(Erik Ensing),罗吉尔·贝斯曼(Rogier C. Bistman)。Jos The Man,Michelle Muller,Joost C.M.扩展,凯特(Cauter)的释放,桑德(Sander)P.W.<组,米兰J. Courtfmann,Yvonne G.T.H.Mill,Winfried R. Mulder,Martine B.W. 原则,Jan Gerard Sterrenburg,Deep V.P,Joeri J.P.白人,埃里克·恩(Erik Ensing),罗吉尔·贝斯曼(Rogier C. Bistman)。Mill,Winfried R. Mulder,Martine B.W.原则,Jan Gerard Sterrenburg,Deep V.P,Joeri J.P.白人,埃里克·恩(Erik Ensing),罗吉尔·贝斯曼(Rogier C. Bistman)。

verif.ai:迈向带有参考和可验证答案的开源科学生成的提问系统
混合搜索利用词汇和语义搜索的优势,有效地找到具有精确匹配和类似含义的文档。y timiquel y优先级文档,并提供了平衡的方法。

可持续性报告2023-24
Wipro Limited(NYSE:WIT,507685,NSE:WIPRO)是全球企业的IT服务提供商。Our IT Services business provides a range of IT and IT-enabled services which include digital strategy advisory, customer-centric design, technology consulting, IT consulting, custom application design, development, re-engineering and maintenance, systems integration, package implementation, global infrastructure services, analytics services, business process services, research and development, and hardware and software design to leading enterprises worldwide.它因其全面的服务组合,对可持续性的坚定承诺以及良好的企业公民身份而获得全球认可。


实现 AI 和 ML 合规性的 5 个关键点
Wipro Limited (NYSE: WIT, BSE: 507685, NSE: WIPRO) 是一家全球领先的信息技术、咨询和业务流程服务公司。我们利用认知计算、超自动化、机器人、云、分析和新兴技术的力量,帮助我们的客户适应数字世界并取得成功。我们是一家以其全面的服务组合、对可持续发展的坚定承诺和良好的企业公民意识而享誉全球的公司,拥有超过 175,000 名敬业的员工,为六大洲的客户提供服务。我们共同探索创意,将点点滴滴串联起来,打造一个更美好、更大胆的新未来。

Macworld 2000 年 8 月 - 经典苹果
超高效汽油发动机,配备先进的电动机,无需插电。无需充电站。无需插头。不妥协。Prius 采用革命性的丰田混合动力系统,该系统储存减速时产生的能量并将其转换回电能。它速度快,驾驶乐趣十足,有害排放量减少 90%。Prius。这改变了一切。

2024-2027 年战略计划
CUC-OM 是乡村大学中心 (CUC) 网络的一部分,该网络始于一个简单而有力的认识——地方人民应该拥有根据他们的需求量身定制的学习空间,在他们的社区内,并提供支持,帮助个人发展技能和知识,从而取得成功。因此,CUC 模式诞生了,由地方人民为地方人民而建。