XiaoMi-AI文件搜索系统
World File Search Systemdatabases

教育工作者的定量研究工具
研究人员可以浏览学术和商业数据库,以检查是否有适当的工具。他们可以检查学术和商业数据库,以发现其主题的适当工具(Burns&Grove,2011; Devellis,2017; McDowell,2006)。学术数据库是找到经过验证和测试的研究工具的绝佳工具,以获得可靠性和有效性。此外,商业数据库可能会出售或提供对工具的访问。但是,在研究项目中使用仪器之前,必须对其进行验证和评估以确保可靠性和有效性。此外,可能需要在研究人员利用该工具之前获得原始作者或版权持有人的许可。此外,研究人员可以参考图书馆可用的论文或论文。

软件工程师实习生 - 麻烦aluaa
教育南达科他州立大学,布鲁金斯SD计算机科学科学学士学位预期毕业:2026年5月:数据结构,数据库管理系统,面向对象的编程,软件工程,软件工程,软件项目管理计算机架构,操作系统,操作系统,离散数学技能编程和抄写: Scripting AI & Machine Learning: TensorFlow (Basics), Scikit-learn (Basics), Stable Diffusion, Ollama, Google AI Studio, OpenCV, Pandas, NumPy Software & Development Tools: Visual Studio, VS Code, Linux, Docker, Git, GitHub, Jupiter Notebooks, PowerShell, Quartus Prime, PgAdmin Web & Application Development: .NET, Django, RESTful APIs, UI/UX Design, Figma, Cloudflare, HTML, CSS, Chrome DevTools Databases & Data Management: PostgreSQL, MySQL, MongoDB, Data Analytics, Data Visualization Additional Skills: Agile/Scrum, Cybersecurity Basics, Microsoft Office, Slack, Teams, Customer Service PROJECTS Diabetes Prediction System [ GitHub Repository ] January 2025教育南达科他州立大学,布鲁金斯SD计算机科学科学学士学位预期毕业:2026年5月:数据结构,数据库管理系统,面向对象的编程,软件工程,软件工程,软件项目管理计算机架构,操作系统,操作系统,离散数学技能编程和抄写: Scripting AI & Machine Learning: TensorFlow (Basics), Scikit-learn (Basics), Stable Diffusion, Ollama, Google AI Studio, OpenCV, Pandas, NumPy Software & Development Tools: Visual Studio, VS Code, Linux, Docker, Git, GitHub, Jupiter Notebooks, PowerShell, Quartus Prime, PgAdmin Web & Application Development: .NET, Django, RESTful APIs, UI/UX Design, Figma, Cloudflare, HTML, CSS, Chrome DevTools Databases & Data Management: PostgreSQL, MySQL, MongoDB, Data Analytics, Data Visualization Additional Skills: Agile/Scrum, Cybersecurity Basics, Microsoft Office, Slack, Teams, Customer Service PROJECTS Diabetes Prediction System [ GitHub Repository ] January 2025
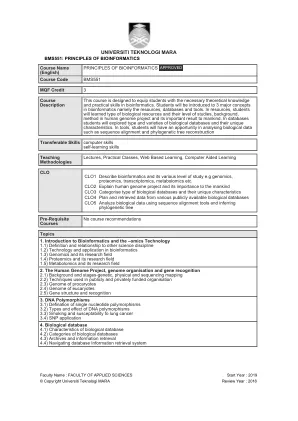
BMS551:生物信息学原理
本课程旨在使学生在生物信息学方面具有必要的理论知识和实践技能。将向学生介绍生物信息学中的3个主要概念,即资源,数据库和工具。在资源中,学生将学习生物资源的类型及其研究水平,背景,人类基因组项目中的方法及其对人类的重要结果。在数据库中,学生将探讨生物数据库的类型和品种及其独特的特征。在工具中,学生将在分析生物学数据(例如序列比对和系统发育重建

SAP NetWeaver 应用服务器 ABAP/Java 与 Oracle Exadata Cloud@Customer X10M
• 每个 VM 的本地存储量决定了可以在 VM 中部署多少个用于数据库安装的 Oracle 数据库主目录 ( ORACLE_HOME )。Oracle 数据库主目录会随着时间的推移而增长,并且对于使用所需的 SAP 捆绑补丁进行持续维护,需要多个 Oracle 数据库主目录副本 ( SAP 说明 2799959 )。对于 SAP NetWeaver 部署,Oracle 数据库主目录需要 200 GB 的磁盘空间,并且需要三年的时间,不包括每个 VM 的 184 GB 固定开销(用于操作系统和网格基础架构)。每个 VM 群集的最大 SAP NetWeaver 数据库数量取决于 Oracle 数据库主目录的配置方式。如果 SAP NetWeaver 数据库使用自己的 Oracle 数据库主目录,则每个 VM 群集最多只能使用四个 SAP NetWeaver 数据库。如果将共享的 Oracle 数据库主目录用于同一 Oracle 数据库版本的多个 SAP NetWeaver 数据库,则可以在 VM 群集上使用更多 SAP NetWeaver 数据库。可在 VM 集群上配置的使用共享 Oracle Database home 的 SAP NetWeaver 数据库的数量取决于数据库的大小以及在 VM 集群节点上运行的数据库实例所需的主内存量。需要进行适当仔细的规模调整,以确定运行 SAP NetWeaver 环境所需的 Exadata Cloud@Customer X10M 系统。

扭伤 - 菌株和肌力性脑脊髓炎/慢性疲劳综合征和纤维肌痛之间的因果关系
•2024年5月15日进行了全面而系统的文献搜索。• The search was done on commercial medical literature databases, including BIOSIS Previews (1969 to 2008), Embase (1974 to 2024 Week 19), Medline and Epub Ahead of Print, Medline In-Process, In-Data-Review & Other Non-Indexed Citations, Medline Daily and Medline (1946 to May 14, 2024), Joanna Briggs Institute Evidence Based Practice Database (Current to May 08, 2024年),Cochrane临床答案(2024年4月),可通过OVID平台获得。•我们通过研究扭伤/压力的作用以及ME/CFS或纤维肌痛的发展开始了搜索。在检查了我们关于扭伤/应变文献发现的标题和摘要之后,我们扩大了搜索,以包括对ME/CFS或纤维肌痛的发展的任何身体伤害的作用。这些文献搜索中采用了关键字的组合。这些关键字包括:

将COVID-19疫苗接种纳入黎巴嫩的初级卫生保健网络
进行了对文献的全面搜索,以确定关注将COVID-19-19疫苗接种到PHC,需求,障碍和反理的话题的文章。Search strategy consisted of reviewing the following databases: Medline/ Pubmed (MeSH terms: Coronavirus Infections, Viral Vaccines, Vaccination, Primary Health Care), IMEMR (keywords: COVID-19 vaccine, coronavirus vaccine, primary health care), Health Evidence (keywords: COVID-19 vaccine, coronavirus vaccine, primary health care), Health Systems Evidence (关键字:Covid-19疫苗,冠状病毒疫苗,初级卫生保健)和EMBASE(关键字:Covid-19-19疫苗,冠状病毒疫苗,初级卫生保健)。此外,还包括从WHO,FDA,CDC,黎巴嫩MOPH,临床试验中检索到的数据。手工搜索还具有两个目标:1)搜索支持数据和2)进行精细的搜索。由于这种方法,本文档中包括93个文章和数据源。

研究入学考试(RET)的教学大纲...
第1节:研究方法显微镜技术:光,相比,荧光,共聚焦,扫描和传播电子显微镜,细胞测量法和流式细胞仪,固定和染色,荧光内杂交(FISH),GISH(GISH(GISH),基因组中的基因组合杂交)。使用分子方法访问微生物多样性,例如剥落梯度凝胶电泳(DGGE),温度梯度凝胶电泳(TGGE),扩增的RRNA限制分析,终末限制性片段长度多态性(T-RFLP),16S rdna测序,Metagenomics to BiioInmics and Intermins(Ww Ww Ww Ww) HTML, URLs, Netscape, Explorer, Google, PUBMED), database management system, database browsing, data retrieval, sequence and genome database, databases such as GenBank, EMBL, DDBJ, Swissprot, PIR, TIGR, TAIR, Searching for sequence database like FASTA and BLAST algorithm, multiple sequence alignment, phylogenetic analysis and detection of open reading帧(ORF)。

计算生物学的基本原理3学分课程(2 ...
单元1。使用序列(基础I):在本单元中,学生将了解生物序列数据规范和表示的细节。将教授不同格式的序列,不同类别的数据库类别和一些重要的开源数据库的概述。

课程结构和教学大纲(从 2018-19 学年起)
模块 2:关系查询语言 关系代数、元组和域关系演算、SQL3、DDL 和 DML 构造、开源和商业 DBMS -MYSQL、ORACLE、DB2、SQL 服务器 关系数据库设计 域和数据依赖性、阿姆斯特朗公理、范式、依赖保存、无损设计 查询处理和优化 关系代数表达式的评估、查询等价性、连接策略、查询优化算法 模块 3:存储策略 索引、B 树、散列 模块 4:事务处理 并发控制、ACID 属性、调度的可序列化性、基于锁定和时间戳的调度程序、多版本和乐观并发控制方案、数据库恢复 模块 5:数据库安全 身份验证、授权和访问控制、DAC、MAC 和 RBAC 模型、入侵检测、SQL 注入 模块 6:高级主题 面向对象和对象关系数据库、逻辑数据库、Web 数据库、分布式数据库、数据仓库和数据挖掘

数字化转型与创业基础
作业 # 1(小组作业,30%):数字化转型文献综述 搜索学术研究数据库(此类数据库的示例有:Web of Science 核心合集;EBSCO;Business Source Complete;Google Scholar;或其他数据库),以创建 12-20 篇关于数字化转型的同行评审学术文章列表,重点关注小组选择的特定子主题。例如,您可以使用以下关键词进行搜索:“数字化转型”和“颠覆”或“颠覆性创新”;“数字化转型”和“价值主张”;“数字化转型”和“业务流程改进”;“数字化转型”和“创业机会”;“数字化转型”和“竞争优势”等。