XiaoMi-AI文件搜索系统
World File Search Systemdrl

对安全强化学习的批判性评论...
摘要 - 现代智能电力系统中分布式能源资源(DER)的高渗透引入了电力部门的不可预见的不确定性,从而增加了电力系统的运行和控制的复杂性和难度。作为一种尖端的机器学习技术,近年来已广泛实施深入的加固学习(DRL),以处理电力系统的不确定性。但是,在关键基础架构(例如电力系统)中,安全问题始终获得重中之重,而DRL可能并不总是满足电力系统运营商的安全要求。安全加固学习的概念(安全RL)正在成为克服电源系统操作和控制中常规DRL的缺点的潜在解决方案。本研究对重点是安全RL的最新研究工作进行了严格的评论,以得出电力系统控制政策,同时考虑了电网的独特安全要求。此外,这项研究突出显示了在电力系统领域内的不同应用中应用的各种安全RL算法,从单网格连接的电力转换器,住宅智能家居和建筑物到大型配电网络。对于所有概述的方法,还提供了有关其瓶颈,研究挑战的讨论以及电源系统应用程序的操作和控制机会。本评论旨在支持安全RL算法领域的研究,在DERS的高度不确定性中,采用安全性限制的智能电力系统操作。

使用主动学习和超参数优化的图像切解分解
图像切解分析检测数字图像中隐藏的数据,对于增强数字安全性至关重要。传统的切解方法通常依赖于大型预先标记的图像数据集,这些数据集很困难且昂贵。为了解决这个问题,本文介绍了一种创新的方法,该方法结合了积极的学习和非政策深度强化学习(DRL),以使用最小标记的数据来改善图像ste缩。主动学习允许模型智能选择应注释哪些未标记的图像,从而减少有效培训所需的标记数据量。传统的主动学习策略通常使用限制灵活性且不能很好地适应动态环境的静态选择方法。为了克服这一点,我们的方法结合了用于战略数据选择的非政策DRL。DRL中的非政策可以提高样本效率,并显着提高学习成果。我们还使用差分进化(DE)算法来微调模型的超参数,从而降低了其对不同设置的敏感性并确保更稳定的结果。我们对广泛的BossBase 1.01和BOWS-2数据集进行了测试,证明了该方法区分未更改和隐形图像的强大能力,在BossBase 1.01和BOSS-2数据集对BossBase 1.01和91.834%的平均F量表达到93.152%。总而言之,这项研究通过采用先进的图像切解分析来检测隐藏数据,从而增强了数字安全性,从而通过最小的标记数据显着提高了检测准确性。
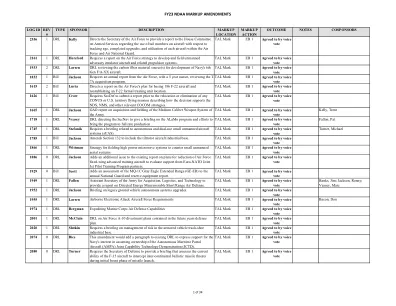
FY23 NDAA 标记修订
2231 2 DRL DesJarlais 指示国防部研究与工程部副部长与工业界合作,启动大规模、跑道发射、能够以 5 马赫以上速度飞行的高马赫飞机的需求开发流程,目标是参加原型设计竞赛。

通过联合行动选择在线组合资源分配与任意行动空间
当前的DRL算法通常假设固定数量的可能动作,然后一次选择一个动作,从而使它们在任意较大的空间中的资源分配问题效率低下。顺序操作选择需要为所选的每个操作更新状态,这增加了决策深度,状态空间,不确定性和执行次数。这会影响算法的收敛性并减慢执行速度。此外,当前的DRL算法对于在线资源分配问题的效率不高,因为它们采用固定数量的操作,而任意数量的任务到达数量。为了应对这些挑战,我们提出了一种新颖的结合作用选择方法,使DRL算法能够同时从具有任意数量的可能动作的集合中选择一个任意数量的动作的联盟。通过在每个时间步骤做出同时决策,联盟行动选择避免了由多次更新状态更新的顺序决策引起的计算成本和较大的状态空间。我们使用在线组合资源分配问题评估了联盟行动选择和顺序行动选择方法的绩效和复杂性。结果表明,联盟行动选择方法保留了在线组合资源分配问题的各种在线交通需求到达率的最佳离线性能,而顺序动作选择方法的性能随着问题的大小的增加而降低。实验还揭示了联盟行动选择的计算复杂性比顺序作用选择要低得多。
![基于多核纤维的太空分层多路复用网络的深增强学习RMSCA [邀请教程]](/simg/a\a7dc23a2ed6945ae588b3a67352e043368864ba0.webp)
基于多核纤维的太空分层多路复用网络的深增强学习RMSCA [邀请教程]
对网络能力的不断升级的要求催化了太空层多路复用(SDM)技术的采用。随着多核光纤(MCF)制造的持续进展,基于MCF的SDM网络被定位为可行且有前途的解决方案,可在多维光学网络中实现更高的传输能力。然而,借助基于MCF的SDM网络提供的广泛网络资源带来了传统路由,调制,频谱和核心分配(RMSCA)方法的挑战,以实现适当的性能。本文提出了一种基于基于MCF的弹性光网(MCF-eons)的深钢筋学习(DRL)的RMSCA方法。在解决方案中,具有基本网络信息和碎片感知奖励函数的新型状态表示旨在指导代理学习有效的RMSCA策略。此外,我们采用了一种近端策略优化算法,该算法采用动作面膜来提高DRL代理的采样效率并加快培训过程。用两个不同的网络拓扑评估了所提出的算法的性能,其交通负荷不同,纤维具有不同数量的核心。结果证实,所提出的算法在将服务阻断概率降低约83%和51%方面优于启发式方法和最先进的基于DRL的RMSCA算法。此外,提出的算法可以应用于具有和没有核心切换功能的网络,并且具有与现实世界部署要求兼容的推理复杂性。

一个统一的批处理层次加固学习框架,用于教学策略诱导,深度分配指标
摘要。智能辅导系统(ITS)利用AI适应个人学生,许多ITS采用教学政策来决定面对替代方案的下一个教学行动。许多研究人员应用了加固学习(RL)和Deep RL(DRL)来诱导有效的教学政策。大部分先前的工作是针对特定的,并且不直接应用于另一个工作。在这项工作中,我们提出了一个询问收入框架,该框架结合了深度BI模拟M eTrics和DRL(名为MTL-BIM),以诱导跨不同领域的两个不同ITS的统一教学政策:逻辑和概率。基于经验课堂结果,我们的统一RL政策的执行效果明显优于专家制作的政策,并在这两个ITS上都独立诱导了DQN政策。

通过深钢筋学习
摘要 - 由于物流和仓储环境中的广泛应用,垃圾箱包装问题(BPP)最近引起了热情的研究兴趣。真正必须优化垃圾箱以使更多对象被包装到框中。对象包装顺序和放置策略是BPP的两个关键优化目标。但是,BPP的现有优化方法,例如遗传算法(GA),是高度计算成本的主要问题,准确性相对较低,因此在现实的情况下很难实施。为了很好地缓解研究差距,我们提出了一种新颖的优化方法,用于通过深度增强学习(DRL)定期形状的二维(2D)-BPP和三维(3D)-BPP,最大程度地利用空间,并最大程度地减少盒子的使用数量。首先,提出了由编码器,解码器和注意模块组成的修改指针网络构建的端到端DRL神经网络,以达到最佳对象包装顺序。第二,符合自上而下的操作模式,基于高度图的放置策略用于在框中排列有序的对象,从而防止对象与盒子中的盒子和其他对象碰撞。第三,奖励和损失功能被定义为基于对政治演员批评的框架进行培训的紧凑性,金字塔和用法数量的指标。最后,实施了一系列实验,以将我们的方法与常规的包装方法进行比较,我们从中得出结论,我们的方法在包装精度和效率方面都优于这些包装方法。

©2023 IEEE。允许个人使用此材料。必须在任何其他用途中获得IEEE的许可,在任何当前或将来的Media,Inc
摘要 - 具有低地球轨道(LEO)卫星的Non-Trrestrial网络(NTN)被认为是支持全球无处不在的无线服务的有前途的补救措施。由于狮子座卫星的快速流动性,特定用户设备(UE)经常发生梁间/卫星切换。为了解决此问题,已经研究了地球固定的细胞场景,其中Leo卫星将其横梁方向调节朝向其停留时间内的固定区域,以保持UE的稳定传输性能。因此,LEO卫星需要执行实时资源分配,但是,Leo卫星的计算能力有限。为了解决这个问题,在本文中,我们建议在NTN中进行两次尺度的协作深度强化学习(DRL)方案(DRL)计划,其中Leo卫星和UE具有不同的控制周期,以不同的控制周期更新他们的决策政策。具体来说,UE更新其政策主题,以提高两个代理的价值功能。fur-hoverore,Leo卫星仅通过有限步骤推出,并通过从UE收到的参考决策轨迹做出决策。仿真结果表明,所提出的方案可以有效地平衡传统贪婪搜索方案的吞吐量性能和计算复杂性。索引术语 - 非事物网络(NTN),地球固定细胞,资源分配,深度强化学习(DRL),多时间级马尔可夫决策过程(MMDPS)。

云边端协作网络中 AI 驱动的节能内容任务卸载
Error 500 (Server Error)!!1500.That’s an error.There was an error. Please try again later.That’s all we know.

在MCC
关键任务交流(MCC)是5G中的主要目标之一,它可以利用多个设备对设备(D2D)连接来增强关键任务交流的可靠性。在MCC中,D2D用户可以重复使用没有基站(BS)的蜂窝用户的非正交无线资源。同时,D2D用户将对蜂窝用户产生共同通道干扰,因此会影响其服务质量(QoS)。为了全面改善用户体验,我们提出了一种新颖的方法,该方法涵盖了资源分配和功率控制以及深度加强学习(DRL)。在本文中,精心设计了多个程序,以帮助制定我们的建议。作为起动器,将建模具有多个D2D对和蜂窝用户的场景;然后分析与资源分配和权力控制有关的问题,以及我们优化目标的制定;最后,将创建基于频谱分配策略的DRL方法,这可以确保D2D用户获得足够的QoS改进资源。使用提供的资源数据,D2D用户通过与周围环境进行交互来捕获的资源数据可以帮助D2D用户自主选择可用的通道和功率,以最大程度地提高系统容量和频谱效率,同时最大程度地减少对蜂窝用户的干扰。实验结果表明,我们的学习方法表现良好,可显着改善资源分配和功率控制。©2020作者。由Elsevier B.V.这是CC下的开放访问文章(http://creativecommons.org/licenses/4.0/)。