XiaoMi-AI文件搜索系统
World File Search Systemepochs

人工智能专利数据集 (AIPD) 2023 年更新
20 我们对 80/20 训练运行使用了分层划分(其中分层为种子、反种子、正决策边界、负决策边界、正考官注释和负考官注释),并且每次运行对模型进行最多 40 个训练周期的训练。我们根据平均 F1 得分(超过 5 次运行)的变化情况来选择要使用的周期数,挑选出近似最大化 F1 的周期数(以避免过度拟合)。对于最终模型,我们使用了所有训练数据(即没有 80/20 划分)和上一步中选择的周期数。

社会脑电图 - 学习实验室
图 2 EEG 数据事件和按代码分离的示意图。(a)连续 EEG 数据(5 秒连续数据),父电极在上方,子电极在下方。事件开始和 1 秒时期的事件标记用垂直线表示。(b)演示如何将 EEG 时间序列数据分离为用于分析或排除的数据。将对应于新行为状态开始的事件代码(实线)添加到 EEG 文件中,以创建 1 秒时期。500 毫秒的过渡期(虚线表示开始)被排除,以及不能完全适合 1 秒时期的额外时间。然后拒绝剩余伪影的时期,只留下无伪影的时期

使用可穿戴脑感应头带的EEG信号引起的驱动器嗜睡的研究文章检测
摘要:驾驶员嗜睡检测在道路安全和高级驾驶辅助系统领域起着重要作用。脑电图(EEG)信号是疲劳和嗜睡最准确,最可靠的指标之一,但在检测嗜睡的情况下,其医学分级测量系统可能对驾驶员来说是侵入性的。这项研究的目的是测试消费者分级的脑电图传感器的可行性和可用性,以在驾驶员嗜睡检测系统中使用。实验是通过使用Muse的大脑感应头带进行的。快速傅立叶变换(FFT)方法用于从EEG信号中提取特征。然后,提取的特征数据随后用于构建两个分类模型,即支持向量机(SVM)和人工神经网络(ANN)。嗜睡的检测是二进制分类任务,它是在昏昏欲睡的时期和警报时期进行分类。在仅检测到昏昏欲睡的时期的情况下,SVM模型检测到82.7%的昏昏欲睡时期,这比ANN模型更好,而ANN模型只能检测到81.25%的昏昏欲睡时期。但是,在昏昏欲睡和警报时期的检测中,ANN模型的性能要比SVM更好。使用不同的内核函数测试了SVM模型,而精细的高斯SVM模型的精度最高为87.8%。ANN模型的执行略高于SVM模型,精度为87.9%。在这项研究中验证了消费者分级的EEG传感器在嗜睡检测系统中使用的能力。关键字:驱动程序嗜睡检测,脑电图(EEG),脑部计算机接口(BCI),支持向量机(SVM),人工神经网络(ANN)

生物启发的学习比反向发展更好吗?基准测试生物学习与Backprop
摘要 - Bio启发的学习最近一直在越来越受欢迎,因为反向传播(BP)在生物学上不合理。在文献中提出了许多算法,它们在生物学上比BP更合理。然而,除了克服BP的生物学不可使用之外,仍然缺乏使用生物启发算法的强大动机。在这项研究中,我们对BP与多种生物启发的算法进行了整体比较,以回答生物学习是否比BP的其他好处的问题。我们在不同的设计选择下测试生物叠加,例如仅访问部分培训数据,训练时期数量的资源约束,神经网络参数的稀疏以及在输入样本中添加噪声。通过这些实验,我们明显发现了生物算法比BP的两个关键优势。首先,当不提供整个培训数据集时,生物算法的表现要比BP好得多。当仅20%的培训数据集可用时,五个生物算法中的四个测试的均优于BP的精度高达5%。其次,即使有完整的数据集可用,生物叠加学的学会更快地学习,并在较小的训练时期融合到稳定的精度,而不是BP。Hebbian学习,特别是在仅5个时代学习,而BP则需要100个时代。 这些见解提出了利用生物学习的实际原因,而不仅仅是它们的生物学合理性,还指出了有趣的新方向,以实现生物学习的未来工作。Hebbian学习,特别是在仅5个时代学习,而BP则需要100个时代。这些见解提出了利用生物学习的实际原因,而不仅仅是它们的生物学合理性,还指出了有趣的新方向,以实现生物学习的未来工作。
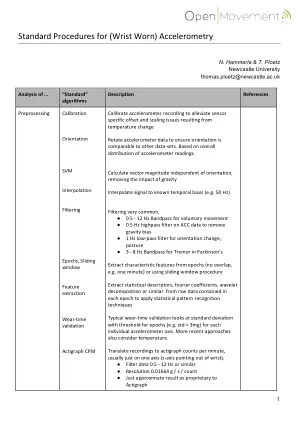
(腕戴式)加速度计的标准程序 - Axivity
从各个时期提取特征特征(无重叠,例如一分钟)或使用滑动窗口程序从每个时期包含的原始数据中提取统计描述符、傅立叶系数、小波分解或类似内容,以应用统计模式识别技术典型的佩戴时间验证着眼于每个加速度计轴的各个时期的标准偏差和阈值(例如std < 3mg)。较新的方法还考虑了温度。将记录转换为每分钟的活动记录仪计数,通常只在一个轴上(z 轴指向手腕外)。

附录
对于所有实验,源解析器都是一个神经 PCFG [64],具有 20 个非终结符和 20 个前终结符。所有实验共享的其他模型设置包括:(1)Adam 优化器,学习率 = 0.0005、β1 = 0.75、β2 = 0.999,(2)梯度范数剪裁为 3,(3)L2 惩罚(即权重衰减)为 10-5,(4)Xavier Glorot 均匀初始化,以及(5)训练 15 个 epoch,并在验证集上提前停止(大多数模型在 15 个 epoch 之前就收敛得很好)。SCAN 和风格迁移数据集的批次大小为 4,机器翻译数据集的批次大小为 32。由于内存限制,在实践中我们使用批次大小 1,并通过梯度累积模拟更大的批次大小。我们观察到训练有些不稳定,一些数据集(例如 SCAN 和机器翻译)需要使用 4 到 6 个随机种子进行训练才能表现良好。一般来说,我们发现过度参数化语法和使用比必要更多的非终结符是可以的 [13]。

基于最大熵形式的量子态层析成像变分方法
图 3:对于范围从 2 到 6 的量子比特,该图显示了在每一步优化中使用重建的量子态获得的 Hermitian 算子的 IC 集的真实期望值和生成的期望值之间的时期数的函数即均方误差 (MSE) 损失。

睡眠结构差异的评估……
脑电图(EEG):用于诊断、监测和管理与癫痫和睡眠障碍相关的神经生理疾病。多导睡眠图中对睡眠和觉醒的定义也是利用EEG技术进行的。许多流行病学和临床研究已经检验了抑郁症和睡眠障碍之间的关系。临床观察和研究表明,抑郁症患者的睡眠结构变化很敏感,甚至具有特异性。本研究旨在利用Itakura距离测量法研究健康受试者和抑郁症患者在非快速眼动(NREM)、非快速眼动(N2)和快速眼动(REM)阶段睡眠脑电图的结构差异。在健康受试者的N2和REM时期之间进行比较时,距离较小。在抑郁症受试者彼此之间以及与健康受试者的N2和REM时期之间的比较中,发现距离较大。研究表明,患者的睡眠脑电图在N2阶段与在REM阶段的差异很大。

CVPR 2024的第一位解决方案自主挑战赛
A100 GPU。批处理大小设置为64,随机GRA-211 DIENT下降(SGD)[2]和基本学习率为0.05。212训练包括100个时期,队列大小为213,动量编码器为3,276,800。类似于Mocov2 [4]中描述的En-214 Hancements,我们利用了相同的215损耗函数和数据增强技术; (2)点216云预测阶段。在此阶段,我们在32 nvidia a100 gpus上训练217型。训练涉及218使用5帧的历史多视图图像和迭代219 219变压器解码器6次,以预测点云220,即接下来的3秒钟,每个框架间隔为0.5 sec-221 ONDS。为了保存GPU内存,我们在每个训练步骤中分离出222个其他预测的梯度。使用ADAMW [8] Opti-224 Mizer,初始学习速率为2E-4的系统223的系统进行了8个预训练时期,并通过余弦退火策略调整了225。226

微型 AI 应用的神经形态模拟实现
NASP 解决方案使用迁移学习的原理,其中负责原始数据预处理的神经网络的大多数层(1)在一定数量的训练周期后保持不变(固定模拟核心),并且只有最后几层(2)在接收新数据和重新训练时进行更新(灵活数字核心)。