XiaoMi-AI文件搜索系统
World File Search Systemmodal

结构可控性预测功能模式和大脑刺激益处与工作记忆
大脑是一个固有的动态系统,许多工作都集中在通过局部扰动和全局网络集合功能变化来修饰神经活动的能力上。网络可控性是网络神经科学中的最新概念,该概念旨在预测单个皮质位点对全球网络状态和状态变化的影响,从而对局部对全球脑动力学的影响产生统一的说明。尽管该概念在工程科学中被接受,但在神经科学中的持续辩论中,将网络可控性与大脑活动和人类行为联系起来的经验证据仍然很少。在这里,我们提出了一组源自fMRI,扩散张量成像和在线重复的经颅磁刺激(RTMS)的多模式的大脑 - 行为关系 - 在由两个男女个人执行的单独校准的工作记忆任务中应用的。描述结构网络系统动力学的模式显示了与任务难度相关的大脑活动的直接关系,并且在硬任务条件下有助于功能性脑状态的难度到范围的模式。模态可控性(量化难以到达模式的贡献的措施)在受刺激的站点上预测了与任务难度增加和RTMS对任务绩效的益处相关的fMRI激活。此外,fMRI解释了模态可控性和与5 Hz在线RTMS相关的工作记忆益处之间64%的差异。因此,这些结果为网络控制理论的功能有效性提供了证明,并概述了整合结构网络拓扑和功能活动的清晰技术,以预测刺激对后续行为的影响。

希格斯机制和超导性:形式类比的案例研究
在实验性发现Higgs玻色子之后,物理学家通过吸引了用凝聚态物理学的类比向公众解释了这一发现。这些类比的历史根源是与超导性模型的类比,该模型在1960年代初将自发对称性破裂(SSB)引入粒子物理学中。分别对电子(EW)相互作用的HIGGS模型以及Ginsburg-landau(GL)和Bardeen-Cooper-Schrie qarie(BCS)模型分别进行了历史和哲学分析。我们分析的结论是,两组类比纯粹是正式的,因为它们伴随着大量的物理脱离。在特定的类似物中,在Higgs模型中,形式类似物没有绘制超导性,对时间,因果或模态结构的SSB的时间,因果或模态结构。这些实质性的物理分离意味着与超导模型的类比不能为EW SSB的物理解释提供基础。但是,SSB在超导性和HIGGS模型中的物理解释之间的对比确实有助于一些基本问题。与SSB不同的超级限度不同,标准模型的Higgs扇区中的SSB(不添加新物理学)既不是时间或因果过程。我们讨论了对希格斯模型中质量增益的“饮食”隐喻的含义。此外,现象学GL模型与动力学BCS模型之间的区别并未延续到EW模型,这表明了EW SSB的所谓“动力学”模型(例如,最小技术)。最后,Higgs模型的发展是科学哲学家的一个启发性案例研究,因为它说明了纯粹的形式类比在物理学中扮演富有成果的启发角色。

视觉到脑电图跨模态知识提炼,实现持续情绪识别
视觉模态是当前连续情绪识别方法中最主要的模态之一。与视觉模态相比,EEG 模态由于其固有的局限性(例如主体偏见和低空间分辨率)而相对不太可靠。这项工作尝试利用来自视觉模态的暗知识来改善 EEG 模态的连续预测。教师模型由级联卷积神经网络-时间卷积网络 (CNN-TCN) 架构构建,学生模型由 TCN 构建。它们分别由视频帧和 EEG 平均频带功率特征输入。采用两种数据划分方案,即试验级随机分流 (TRS) 和留一主体剔除 (LOSO)。独立的老师和学生可以产生优于基线方法的连续预测,并且使用视觉到 EEG 跨模态 KD 进一步改善了预测,具有统计显著性,即 TRS 的 p 值 < 0.01 和 p 值 < 0。 05 用于 LOSO 分区。训练后的学生模型的显着性图显示,与活跃价态相关的大脑区域并不位于精确的大脑区域。相反,它来自各个大脑区域之间的同步活动。与其他波段相比,频率为 18 − 30 Hz 和 30 − 45 Hz 的快速 beta 和 gamma 波对人类情绪过程的贡献最大。代码可在 https://github.com/sucv/Visual _ to _ EEG _ Cross _ Modal _ KD _ for _ CER 获得。

通过靶向增强子启动途径在患者来源的胰腺癌细胞中进行启动治疗
a 马赛癌症研究中心 (CRCM)、INSERM U1068、CNRS UMR 7258、Luminy 科学与技术公园、艾克斯-马赛大学和保利-卡尔梅特研究所,法国 b 布宜诺斯艾利斯大学、国家科学技术研究委员会、药理学和植物学研究中心 (CEFYBO)、医学院,布宜诺斯艾利斯,阿根廷 c 布宜诺斯艾利斯大学、医学院、微生物学、寄生虫学和免疫学系,布宜诺斯艾利斯,阿根廷 d 肿瘤身份证计划 (CIT)、法国抗癌联盟,巴黎,法国 e Laboratoire Modal ' X - UMR 9023,巴黎南泰尔大学,法国南泰尔 f 巴黎萨克雷大学、AgroParisTech、INRAE、UMR MIA Paris-Saclay, Palaiseau 91120,法国 g 基因组学和精准医学中心(GSPMC),威斯康星医学院,美国威斯康星州密尔沃基 h 威斯康星医学院外科系研究部,美国威斯康星州密尔沃基 i 雷恩大学,CNRS,INSERM,IGDR(雷恩遗传和发展研究所)- UMR 6290,ERL U1305,雷恩,法国 j 巴黎城大学,炎症研究中心(CRI),INSERM,U1149,CNRS,ERL 8252,巴黎 F-75018,法国 k 埃尔克鲁塞阿尔塔综合医院,Florencio Varela,文学士,阿根廷 l 阿图罗·豪雷切大学,Florencio Varela,文学士,阿根廷

模式识别
视觉方式是当前连续情绪识别方法的最主要方式之一。与脑电图的内在限制(如受试者偏置和低空间分辨率)相比,脑电图的声音相对较小。这项工作试图通过使用视觉模态的黑暗知识来改善脑电图模式的持续预测。教师模型是由级联卷积神经网络建立的 - 时间卷积网络(CNN -TCN)体系结构,学生模型由TCN构建。它们分别由视频框架和EEG平均频带功率功能馈送。采用了两个数据分配方案,即试验级随机shu ffl ing(TRS)和剩余的受试者(LOSO)。独立的老师和学生可以产生优于基线方法的连续预测,而视觉到EEG跨模式KD的使用进一步改善了统计学意义的预测,即p-value <0。01对于TRS和P值<0。05用于LOSO分区。受过训练的学生模型的显着性图表明,与活动价状态相关的大脑区域不在精确的大脑区域。相反,它是由于各个大脑区域之间的同步活动而引起的。和快速β和伽马波的频率为18-30 Hz和30-45 Hz,对人类的情感过程贡献最大。该代码可在https://github.com/sucv/visual _ to _ eeg _ cross _ modal _ kd _ for _ cer上获得。

Trainline - 2022 财年年度报告 - 亚马逊 AWS
交通运输是英国国内温室气体排放的最大贡献者,2018 年占英国国内排放量的 28%,这些排放的主要来源是公路运输中汽油和柴油的使用。同样,在欧洲,交通运输占温室气体排放量的五分之一以上,其中近 72% 来自公路运输,而不到 0.4% 来自铁路运输。英国脱碳交通计划的战略重点之一是加速交通方式转变,使公共交通成为“我们日常活动的自然首选”,并且在汽车仍然适合长途旅行的情况下,增加“来自高速脱碳铁路和零排放客车的竞争”。
Trainline - 2022 财年年度报告 - 亚马逊 AWS
交通运输是英国国内温室气体排放的最大贡献者,2018 年占英国国内排放量的 28%,这些排放的主要来源是公路运输中汽油和柴油的使用。同样,在欧洲,交通运输占温室气体排放量的五分之一以上,其中近 72% 来自公路运输,而不到 0.4% 来自铁路运输。英国脱碳交通计划的战略重点之一是加速交通方式转变,使公共交通成为“我们日常活动的自然首选”,并且在汽车仍然适合长途旅行的情况下,增加“来自高速脱碳铁路和零排放客车的竞争”。
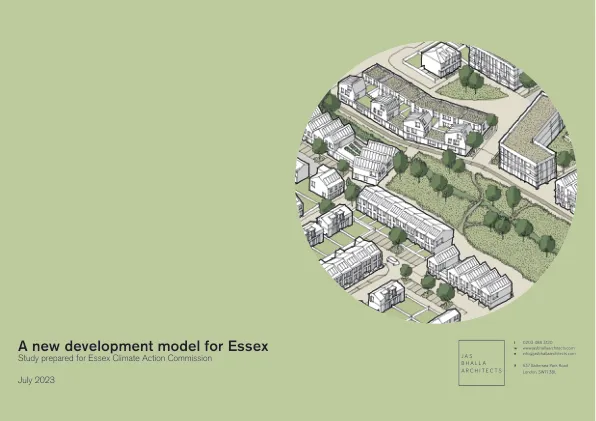
Essex的新开发模型
Walkable Neighbrights Development模型探索了至少4,000套新房屋的大型新社区的解决方案。尽管在埃塞克斯郡(Essex)上提出了4个新的花园社区,但也有大量较小的发展发展,这构成了每年交付的大多数新住房。新的花园社区受益于一系列设计指导和控制,包括设计审查面板,主计划和设计代码,所有这些都旨在广泛提高设计质量并鼓励模态转移。这项研究的关键愿望是分析并提出在一系列范围内的潜在解决方案,从大约100个新房屋到城市扩展和新定居点。

威尔士基础设施投资战略
8. 无论是公共还是私人,基础设施投资——虽然是一个关键的杠杆——只是实现本届政府雄心壮志的解决方案的一部分。因此,必须结合威尔士政府掌握的其他杠杆以及我们无法直接控制的杠杆来看待这一战略。例如,我们对技能基础的投资对于推动经济增长至关重要,而我们对心理健康服务的投资将在改善健康结果方面发挥重要作用。同样,英国政府从 2030 年起禁止销售新的化石燃料汽车将成为推动模式转变的关键杠杆,而电网脱碳将在减少住宅碳排放方面发挥主要作用。

石墨烯涂层极性结构的压电驱动
摘要 - 基于锆钛酸铅(PZT)的铁电材料由于其强大的压电活性而被广泛用作传感器和执行器。然而,由于高处理温度,脆弱性,缺乏共形沉积以及与微电机械系统(MEMS)集成的可能性有限,因此它们的应用受到限制。关于2-D材料中的压电性的最新研究已经证明了它们在这些应用中的潜力,这本质上是由于它们的灵活性和与MEMS的整合性。在这项工作中,我们在无定形的氧化Si 3 N 4膜上沉积了几层石墨烯(FLG),并通过敏感的激光干涉测量法和严格的限定元素建模(FEM)分析研究了它们的压电反应。对FEM进行的模态分析以及与实验结果的比较表明