XiaoMi-AI文件搜索系统
World File Search Systemrecursion

与德勒兹一起思考心灵的运动
在考虑了心智/大脑的技术隐喻(特别是随着图灵机和控制论的发展而成熟的计算机相关隐喻)之后,我认为,一阶控制论极大地改变了我们思考大脑/心智的隐喻,尽管它们仍然植根于人文二元论。另一方面,二阶控制论给了我们大脑是一个自创生系统的概念,它既能解释自主性,也能解释涌现性。二阶控制论中特别重要的是禁止信息跨越自指系统边界的流动,强调两个方面:操作闭包和操作递归。这两个概念特别引起我的兴趣,让我思考当算法推理和人脑开始作为单个自创生系统运作时会发生什么。也就是说,我提出关于数字系统和生物系统同构的问题。我的观点是,计算机不再仅仅是大脑的一个隐喻,因为大脑就是计算机。换句话说,正如德勒兹在他的两本《电影》书中所言,思想中发生了一场真正的控制论运动,类似于电影在图像中带来的真正运动。最后,我认为,操作闭合既可以用神经科学家马克·索尔姆斯和卡尔·弗里斯顿所说的“马尔可夫毯”来理解,也可以用德勒兹的感觉逻辑理论来理解,这可以帮助我们理解算法推理对思想的影响。这是你的大脑信息:大脑/思维的一阶控制论和信息隐喻

量子darwinism对扩展树的编码过渡
Quantum darwinism(QD)提出,经典的客观性是从信息自由度的广播中引起的,以成为多体环境的多个部分。这样的信息广播与在强烈互动下的争夺形成鲜明对比。最近显示,广播和争夺之间插值的量子动力学可能显示出信息传播的尖锐相变,称为QD编码过渡。在这里,我们在通用的非克利福德设置中启动了他们的系统研究。首先,在一般的主题设置中,将信息传播建模为等轴测图,其输入Qudit与参考纠缠在一起,我们提出了对过渡的探测 - 测量环境分数后参考的密度矩阵的分布。此探测器测量分数和注入信息之间的经典相关性。然后,我们将框架应用于张量网络在扩展的树上定义的两个类似模型,对试图播放旋转半旋转的Z组件的嘈杂设备进行建模。我们得出了密度矩阵分布的确切递归关系,我们通过分析和数值分析。因此,我们找到了三个阶段:QD,中间和编码,以及两个连续的过渡。编码中间过渡描述了参考和小环境部分之间非零相关性的建立,并且可以通过对馏分的总旋转的“粗粒度”度量进行探测,该测量是非高斯和对称性的中间空间中的非高斯和对称性破裂。QD-中间的过渡是关于相关性是否完美的。必须通过罚款粒度探测它,对应于复制空间中更微妙的对称性破裂。
bca-云计算
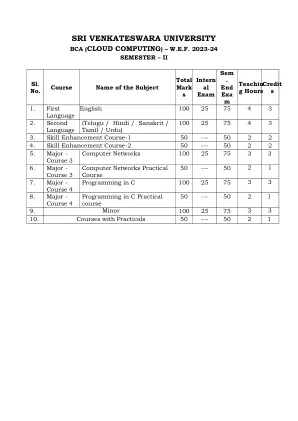
II 教学大纲 第一单元 算法和编程语言简介:算法 – 算法、流程图、编程语言的主要特性 – 编程语言的代 – 编程方法(范式) - C 语言简介:简介 – C 语言的特性 – C 程序的结构 – 编写第一个 C 程序 – C 程序中使用的文件 – 编译和执行 C 程序。 第二单元 编程结构:标记 – 使用注释 – C 语言中的基本数据类型 – 变量 – C 语言中的 I/O 语句 - C 语言中的运算符 - 编程示例。 决策控制和循环语句:决策控制语句简介 – 条件分支语句 – 迭代语句 – 嵌套循环 – Break 和 Continue 语句 – Goto 语句 第三单元 数组:简介 – 数组声明 – 访问数组元素 – 在数组中存储值 – 数组操作 – 一维、二维和多维数组。 字符串:声明和初始化字符串变量、字符和字符串处理函数。单元 IV 函数:简介 – 函数声明/原型 – 函数定义 – 函数调用 – 返回语句 – 函数类别 - 递归 - 参数传递技术 - 变量范围 – 存储类。指针:指针简介 – 声明和初始化指针变量 – 使用指针访问值 - 指针算法 – 动态内存分配。单元 V 结构和联合:简介 – 结构定义 - 访问结构成员 – 结构数组 - 联合定义 – 结构和联合之间的区别,枚举数据类型。文件:文件简介 – 在 C 中使用文件 – 从文件读取数据 – 将数据写入文件 – 检测文件末尾 – 命令行参数。

椰子:结构代码理解不会从树中掉出来
摘要 - LARGE语言模型(LLMS)已显示出涉及结构化和非结构化文本数据的各种任务中的不断表现。最近,LLMS表现出了非凡的能力,可以在不同的编程语言上生成代码。针对代码生成,维修或完成的各种基准测试的最新结果表明,某些模型具有与人类相当甚至超过人类的编程能力。在这项工作中,我们证明了这种基准上的高性能与人类的先天能力理解代码的结构控制流。为此,我们从Hu-Maneval基准测试中提取代码解决方案,相关模型在其上执行非常强烈的执行,并使用从相应的测试集采样的函数调用来追踪其执行路径。使用此数据集,我们研究了7个最先进的LLM与执行跟踪匹配的能力,并发现尽管该模型能够生成语义上相同的代码,但它们仅具有跟踪执行路径的能力有限,尤其是对于更长的轨迹和特定的控制结构。我们发现,即使是表现最佳的模型,Gemini 1.5 Pro只能完全正确地生成47%的人道任务的轨迹。此外,我们引入了一个不在人道主义的三个关键结构的子集,或者仅在有限的范围内包含:递归,并行处理和面向对象的编程原理,包括诸如继承和多态性之类的概念。是oop,我们表明,没有研究的模型在相关痕迹上的平均准确度超过5%。通过无处不在的人道任务进行这些专门的部分,我们介绍了基准椰子:用于导航理解和测试的代码控制流程,该椰子可以衡量模型在相关呼叫(包括高级结构组件)中跟踪代码执行的模型。我们得出的结论是,当前一代LLM仍需要显着改进以增强其代码推理能力。我们希望我们的数据集可以帮助研究人员在不久的将来弥合这一差距。索引术语 - 代码理解,大语言模型,代码执行,基准

卷378编号2全编号1089 2025年2月...
通过粗几何形状885詹妮弗·邓肯(Jennifer Duncan)的厚度嵌入对称空间中,这是球不等式的非线性变体。。。。。。。。。。。。。。。911 Yuchen Bi和Jie Zhou,Varifolds的最佳刚度估计值几乎最小化Willmore Energy。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。943 S.。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。967 Boris Bychkov,Petr Dunin-Barkowski,Kazarian和Sergey Shadrin,拓扑递归的符号义务。。。。。。。。。。。。。。。。1001 Nasrin Altafi,Robert Di Gennnaro,Federico Galetto,Sean Grete,Rosa M. Mir´o-Roig,Uwe Nagel,Artinian Gorenstein,Artinian Gorenstein。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。1055 J. Charatonik,Alexandra Kwiatkowska和Robert P. Roe,。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。1081 Ciprian A. Tudor,多维Stein方法和定量渐近独立性。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。1127 Sean Monahan,Halosphical Stacks和堆放的颜色风扇。。。。。。。。。。。1167 hao pan,Ergodic复发和素数之间的界限。。。。。。。。。。1215 Andr´e Guerra,Xavier Lamy和Konstantinos Zemas,在任意维度中的球体价值图中M obius组的急剧定量稳定性。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。1235 Kevin Ford和Mikhail R. Gabdullin,多项式连续复合值的长字符串。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。1261 Zhicheng Wang,Lusztig对应和有限的Gan-Gross-Prosad问题。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。1283。。。。。。。。。。。。。1329 1329和Coutiannis,Anh N. Le,Joel Moreira,Ronnie Pavlov和Florian K. 1373JoakimFærgeman,第四个钢化D模块。 。 。 。 。 。 。 。 。 。 。 。 1401 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。 。1329和Coutiannis,Anh N. Le,Joel Moreira,Ronnie Pavlov和Florian K.1373JoakimFærgeman,第四个钢化D模块。。。。。。。。。。。。1401。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。1433 VALOV的VESK,同质ANR空间的结构。。。。。。。。。。。。。。1449法国人和马汉MJ,阿诺索夫。1465

通过量子电路表示具有二元特征的二元分类树
决策树是众所周知的预测模型,常用于数据挖掘和机器学习的广泛应用 [1-3]。一般来说,决策树可以看作是一种流程图结构,可用于查询数据。从根开始,每个内部节点代表对查询数据的测试,每个传出分支代表此测试的可能结果。对于二叉树,测试结果是一个布尔值,因此可以是真也可以是假(即每个内部节点有两个分支)。树的每个叶子都可以与一个决策相关联。因此,从根到叶子的路径意味着一组针对查询数据的决策规则,就像一个顺序决策过程。具体来说,我们考虑二叉分类树,其中叶子的决策决定了数据点对预定义的离散类集的成员资格。从给定数据集推断决策树是一项监督机器学习任务,也称为决策树归纳(或决策树学习)。然而,寻找全局最优解是 NP 难问题 [4, 5],因此启发式递归算法在实践中更受青睐 [6]。此类算法通常以贪婪的自上而下的方式工作 [7]:从根开始,通过最小化数据不纯度函数来估计每个内部节点的最佳测试。相应地,沿着两个传出分支将数据集分成两个子集。对每个内部节点递归重复此过程,直到停止标准终止树的遍历并产生一个叶子节点,该叶子节点的分类决策基于节点内数据子集中存在的多数类。当所有路径都通向叶子节点时,算法结束。启发式创建的决策树并不能保证全局最优,但可能仍然适合实际用途。在量子计算的背景下,决策树可以被分配到量子机器学习领域 [8]。之前的几篇论文考虑了决策树和量子计算之间的相互作用。在 [9] 中,研究了决策树的遍历速度,并比较了经典方法和量子方法。作者发现两者之间没有优势。[10] 提出了一种启发式算法来诱导量子分类树,其中数据点被编码为量子态,并使用测量来找到最佳分割。然而,部分算法

人工智能主题:• Mini-Max 算法 • Alpha-Bet
最小最大算法 Alpha-Beta 剪枝 人工智能中的最小最大算法 最小最大算法是一种递归或回溯算法,用于决策和博弈论。它为玩家提供最佳走法,假设对手也发挥最佳。最小最大算法使用递归来搜索游戏树。 最小最大算法主要用于人工智能中的游戏,如国际象棋、跳棋、井字游戏、围棋和各种双人游戏。该算法计算当前状态的最小最大决策。在这个算法中,两个玩家玩游戏,一个称为 MAX,另一个称为 MIN。两个玩家都进行战斗,因为对手玩家获得最小利益,而他们获得最大利益。游戏的两个玩家都是对方的对手,其中 MAX 将选择最大值,而 MIN 将选择最小值。最小最大算法执行深度优先搜索算法来探索完整的游戏树。极小最大算法一直进行到树的终端节点,然后以递归的方式回溯树。 极小最大算法的工作原理 可以用一个例子轻松描述极小最大算法的工作原理。下面我们举一个代表双人游戏的游戏树的例子。在这个例子中,有两个玩家,一个叫做最大化者,另一个叫做最小化者。最大化者将尝试获得最高可能的分数,而最小化者将尝试获得最低可能的分数。该算法应用 DFS,因此在这个游戏树中,我们必须一直穿过叶子才能到达终端节点。在终端节点,给出了终端值,因此我们将比较这些值并回溯树,直到初始状态发生。 Alpha-beta 剪枝 Alpha-beta 剪枝是极小最大算法的修改版本。它是极小最大算法的一种优化技术。正如我们在极小最大搜索算法中看到的那样,它必须检查的游戏状态数量在树的深度上呈指数增长。由于我们无法消除指数,但可以将其减半。因此,有一种技术可以计算出正确的极小极大决策,而无需检查博弈树的每个节点,这种技术称为剪枝。这涉及两个阈值参数 Alpha 和 beta,用于未来扩展,因此称为 alpha-beta 剪枝。它也被称为 Alpha-Beta 算法。

课程与教学大纲
1. 理解和分析算法的空间和时间复杂度。 2. 确定适合给定问题的数据结构。 3. 在各种实际应用中实现图形算法。 4. 实现用于查询和搜索的堆和树。 5. 在高级数据结构操作中使用基本数据结构。 6. 在各种实际应用中使用搜索和排序。 模块:1 函数增长 3 小时 算法和数据结构的概述和重要性 - 算法规范、递归、性能分析、渐近符号 - Big-O、Omega 和 Theta 符号、编程风格、编码细化 - 时空权衡、测试、数据抽象。模块:2 基本数据结构 6 小时 数组、堆栈、队列、链表及其类型、线性数据结构的各种表示、操作和应用 模块:3 排序和搜索 7 小时 插入排序、合并排序、线性时间排序-排序的下限、基数排序、双调排序、鸡尾酒排序、中位数和顺序统计-最小值和最大值、预期线性时间内的选择、最坏情况线性时间内的选择、线性搜索、插值搜索、指数搜索。 模块:4 树 6 小时 二叉树-二叉树的性质、B 树、B 树定义-B 树上的操作:搜索 B 树、创建、分裂、插入和删除、B+ 树。 模块:5 高级树 8 小时 线程二叉树、左撇子树、锦标赛树、2-3 树、伸展树、红黑树、范围树。模块:6 图表 7 小时 图表表示、拓扑排序、最短路径算法 - Dijkstra 算法、Floyd-Warshall 算法、最小生成树 - 反向删除算法、Boruvka 算法。 模块:7 堆和哈希 6 小时 堆作为优先级队列、二叉堆、二项式和斐波那契堆、哈夫曼编码中的堆、可扩展哈希。 模块:8 当代问题 2 小时 总授课时长:45 小时 教科书 1. Cormen, Thomas H.、Charles E. Leiserson、Ronald L. Rivest 和 Clifford Stein。算法简介。麻省理工学院出版社,2022 年。 参考书 1. Skiena, Steven S. “算法设计手册(计算机科学文本)”。第 3 版

苏拉什特拉学院
目标: 让学生理解 C 语言的基本概念 第一单元:C 语言概述:C 语言的历史 –C 语言的重要性 –C 语言的基本结构 – 编程风格 – 常量、变量和数据类型 – 变量的声明、存储类别 – 定义符号常量 – 将变量声明为常量、易失性 – 数据的溢出和下溢。 运算符和表达式:算术、关系、逻辑、赋值运算符 – 增量和减量运算符、条件运算符、位运算符、特殊运算符 – 算术表达式 – 表达式的求值 – 算术运算符的优先级 – 表达式中的类型转换 – 运算符优先级和结合性-数学函数 – 管理 I/O 操作:读写字符 – 格式化的输入、输出。 第二单元:决策和分支:if 语句、if...else 语句 – 嵌套 if ... else 语句 – Else if 阶梯 – Switch 语句 – ?: 运算符 – go to 语句。控制语句:While 语句 – do 语句 – for 语句 – 循环跳转数组:一维数组 – 声明、初始化 – 二维数组 – 多维数组 – 动态数组 – 初始化,UNIT-III:字符串:字符串变量的声明、初始化 – 读写字符串 – 字符串的算术运算 – 将字符串放在一起 – 比较 – 字符串处理函数 – 字符串表 – 字符串的功能。用户定义函数:需要 –

计算机科学与工程系课程大纲...
数字逻辑:逻辑函数、最小化、组合和顺序电路的设计和综合;数字表示和计算机算术(定点和浮点)。计算机组织和架构:机器指令和寻址模式、ALU 和数据路径、CPU 控制设计、内存接口、I/O 接口(中断和 DMA 模式)、指令流水线、缓存和主内存、二级存储。编程和数据结构:C 语言编程;函数、递归、参数传递、范围、绑定;抽象数据类型、数组、堆栈、队列、链接列表、树、二叉搜索树、二叉堆。算法:分析、渐近符号、空间和时间复杂度概念、最坏和平均情况分析;设计:贪婪方法、动态规划、分而治之;树和图遍历、连通分量、生成树、最短路径;散列、排序、搜索。时间和空间的渐近分析(最佳、最坏、平均情况)、上限和下限、复杂性类 P、NP、NP-hard、NP-complete 的基本概念。计算理论:正则语言和有限自动机、上下文无关语言和下推自动机、递归可枚举集和图灵机、不可判定性。编译器设计:词汇分析、解析、语法制导翻译、运行时环境、中间和目标代码生成、代码优化基础。操作系统:进程、线程、进程间通信、并发、同步、死锁、CPU 调度、内存管理和虚拟内存、文件系统、I/O 系统、保护和安全。数据库:ER 模型、关系模型(关系代数、元组演算)、数据库设计(完整性约束、范式)、查询语言(SQL)、文件结构(顺序文件、索引、B 和 B+ 树)、事务和并发控制。信息系统和软件工程:信息收集、需求和可行性分析、数据流图、流程规范、输入/输出设计、流程生命周期、项目规划和管理、设计、编码、测试、实施、维护。计算机网络:ISO/OSI 堆栈、LAN 技术(以太网、令牌环)、流量和错误控制技术、路由算法、拥塞控制、TCP/UDP 和套接字、IP(v4)、应用层协议(icmp、dns、smtp、pop、ftp、http);集线器、交换机、网关和路由器的基本概念。网络安全基本概念:公钥和私钥加密、数字签名、防火墙。Web 技术:HTML、XML、客户端-服务器计算的基本概念。