XiaoMi-AI文件搜索系统
World File Search Systemunseen

TD-Zero:使用零拍学习
摘要 - 供应链漏洞为攻击者提供了将硬件木马植入系统 - 芯片(SOC)设计的机会。虽然基于机器学习(ML)的特洛伊木马检测是有希望的,但它具有三个实际局限性:(i)可能无法获得黄金模型,(ii)缺乏人类专业知识来选择Trojan特征,并且(iii)有限的可传递性可能会导致在新的基准标准中无法获得未观察的Trojans的新基准标准。虽然基于转移学习的最新方法解决了其中一些问题,但仍需要重新训练以使用特定于域特异性(例如,硬件特洛伊木马功能)知识对模型进行微调。在本文中,我们提出了一个利用零射击学习来应对上述挑战的特洛伊木马检测框架。所提出的框架采用了自我监督学习的概念,其中利用预训练的图形卷积网络(GCN)来提取有关硬件Trojans的下划线常识,而指标学习任务用于衡量测试输入和恶意样本之间的相似性来进行分类。广泛的实验评估表明,与最先进的技术相比,我们的方法具有四个主要优势:(i)在特洛伊木马检测过程中不需要任何黄金模型,(ii)可以处理未知的特洛伊木马和未见的基准测试,而不会更改网络的任何变化,(iii)培训时间和(iv)的估计效率的显着提高(iv)的均值提高效率显着(iv)的均值(10.5%)(10.5%)5%(10.5%)。5%(10.5%)。

3D可见性 - 可见的可通用的神经辐射场,用于相互作用的手
神经辐射场(NERFS)是场景,物体和人类的有希望的3D代表。但是,大多数措施方法都需要多视图输入和每场培训,这限制了其现实生活中的应用。此外,熟练的方法集中在单个受试者的情况下,留下涉及严重障碍和挑战性视图变化的互动手的场景。为了解决这些问题,本文提出了一个可见的可见性 - 可见性的NERF(VA-NERF)框架,用于互动。具体来说,给定相互作用的手作为输入的图像,我们的VA-NERF首先获得了基于网格的手表示,并提取了相应的几何和质地。随后,引入了一个功能融合模块,该模块利用了查询点和网格顶点的可见性,以适应双手的特征,从而可以在看不见的区域的功能中进行重新处理。此外,我们的VA-NERF与广告学习范式中的新型歧视者一起进行了优化。与传统的分离器相反,该官员预测合成图像的单个真实/假标签,提议的判别器生成了一个像素的可见性图,为看不见的区域提供了精细的监督,并鼓励VA-NERF提高合成图像的视觉质量。互惠2.6m数据集的实验表明,我们所提出的vanerf的表现明显优于常规的nerfs。项目页面:https://github.com/xuanhuang0/vanerf。

黎巴嫩经济危机:现状与未来方向
-遗憾的是,当整个世界,特别是我们整个中东和北非地区正在从大流行的萎缩中复苏,并在 2021 年实现健康的正增长率时,黎巴嫩去年却经历了又一年的萎缩,原因是投资几乎缺失(投资总额处于内战以来的最高水平——没有人投资)和实际消费总量疲软(在家庭实际收入急剧下降的情况下),而由于强烈的财政整顿要求和随之而来的紧缩需求,政府支出无法弥补这一损失。


估计分布变化以预测基于脑电图的心理负荷评估中的跨受试者泛化
在现实条件下评估心理负荷是确保执行需要持续注意力的任务的工人表现的关键。先前的文献已经为此采用了脑电图 (EEG),尽管已经观察到脑负荷与脑电图的相关性因受试者和身体压力而异,因此很难设计出能够同时呈现不同用户可靠表现的模型。领域适应包括一组策略,旨在提高机器学习系统在训练时对未见数据的性能。然而,这些方法可能依赖于对所考虑的数据分布的假设,而这些假设通常不适用于 EEG 数据的应用。受这一观察的启发,在这项工作中,我们提出了一种策略来估计从不同受试者收集的数据中观察到的多种数据分布之间的两种差异,即边际和条件偏移。除了阐明对特定数据集成立的假设之外,使用所提出的方法获得的统计偏移估计值还可用于研究机器学习管道的其他方面,例如定量评估领域适应策略的有效性。具体来说,我们考虑了从在跑步机上跑步和在固定自行车上踩踏板时执行心理任务的个体收集的脑电图数据,并探索了通常用于减轻跨受试者变异性的不同标准化策略的影响。我们展示了不同的标准化方案对统计变化的影响,以及它们与在训练时对未见过的参与者进行评估的心理工作量预测准确性的关系。

目标导向设计代理:将视觉模仿与一步前瞻优化相结合以实现生成设计
工程设计问题通常涉及大型状态和动作空间以及高度稀疏的奖励。由于无法穷尽这些空间,因此人类利用相关领域知识来压缩搜索空间。深度学习代理 (DLAgents) 之前被引入使用视觉模仿学习来模拟设计领域知识。本文以 DLAgents 为基础,并将其与一步前瞻搜索相结合,以开发能够增强学习策略以顺序生成设计的目标导向代理。目标导向的 DLAgents 可以采用从数据中学习到的人类策略以及优化目标函数。DLAgents 的视觉模仿网络由卷积编码器 - 解码器网络组成,充当与反馈无关的粗略规划步骤。同时,前瞻搜索可以识别由目标指导的微调设计动作。这些设计代理在一个无约束桁架设计问题上进行训练,该问题被建模为一个基于动作的顺序配置设计问题。然后,根据该问题的两个版本对代理进行评估:用于训练的原始版本和带有受阻构造空间的未见约束版本。在这两种情况下,目标导向型代理的表现都优于用于训练网络的人类设计师以及之前反馈无关的代理版本。这说明了一个设计代理框架,它可以有效地利用反馈来增强学习到的设计策略,还可以适应未见的设计问题。[DOI:10.1115/1.4051013]

计划条例2024–2025
该项目的评估是由三个要素进行的:初步书面报告,最终书面报告和看不见的书面考试。,对于所有评估的组合,您必须获得40%或以上的总体加权平均分数;通过最终项目报告并通过书面考试。初步报告的百分比值为10%,最终报告为65%,笔试为25%。如果您未能进行该项目,并且有资格进行进一步的尝试,则您将被要求提交新的初步报告,新的最终报告,并在下一个学年进行书面考试。

最佳控制问题的强化学习
强化学习(RL)是机器学习的跨学科领域(ML),而这是人工智能(AI)的研究领域。ai是机器或计算机展示的智能。ML是指可以从数据中学习并推广到看不见的算法或方法,从而在没有明确指令的情况下执行任务。rl是一组算法,其中智能代理(机器)决定动态环境中的动作以最大程度地提高累积奖励(从数据中学习);名字来自的地方,代理人获得了良好的决定。
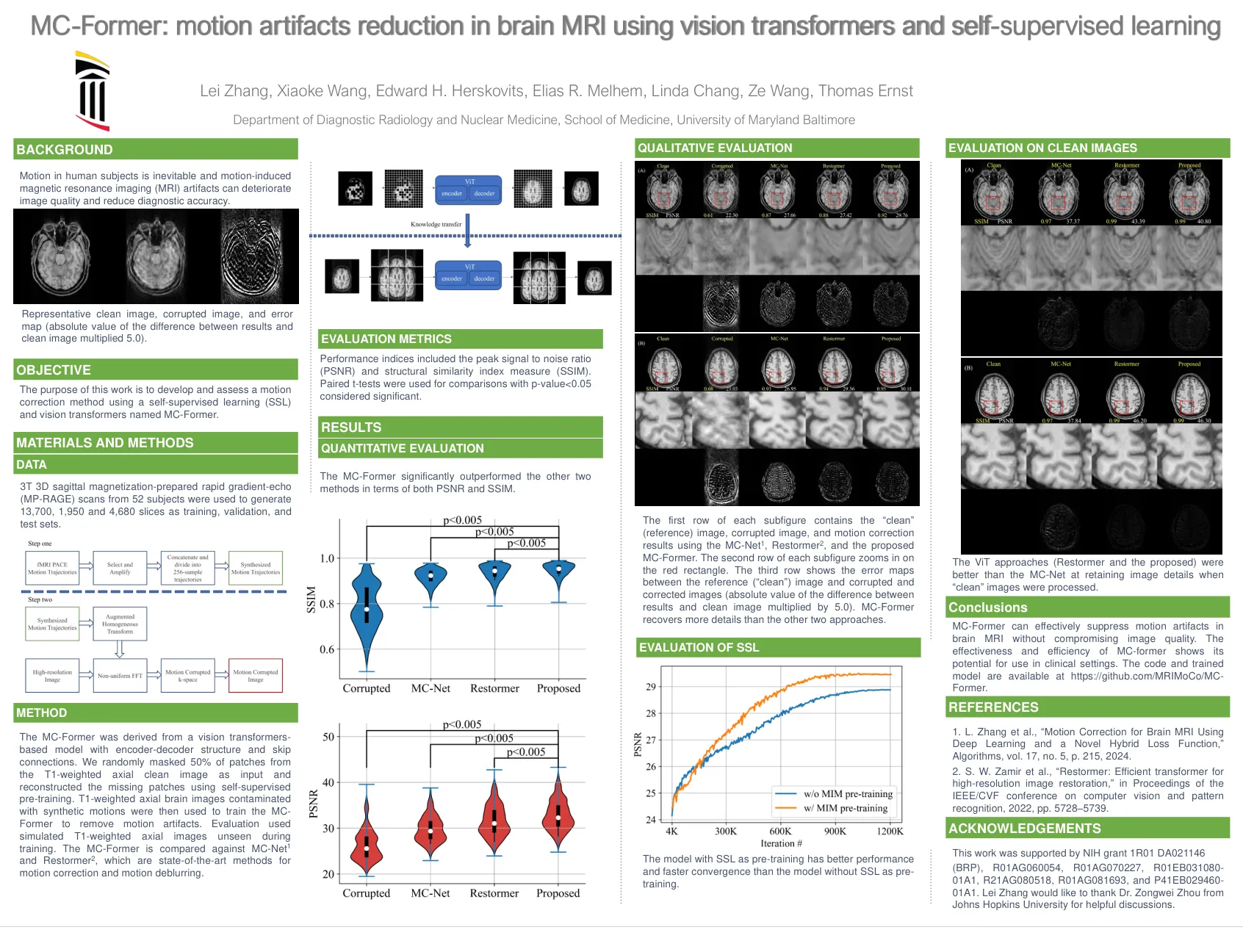
mc-former:使用...
MC形式是从带有编码器编码器结构和跳过连接的基于视觉变压器的模型得出的。我们从T1加权轴向清洁图像中随机掩盖了50%的补丁,并使用自我监督的预训练重建了缺失的补丁。T1加权轴向脑图像被合成运动污染,以训练MC-前者去除运动伪影。评估在训练过程中使用了模拟的T1加权轴向图像。将MC形式与MC-NET 1和RESTORMER 2进行了比较,后者是运动校正和运动去膨胀的最新方法。
