XiaoMi-AI文件搜索系统
World File Search System均化

化学化学
This course aims at introducing the basic concepts and techniques in carrying out chemical analysis by using various modern spectroscopic and chromatographic instruments.Students will learn how to use modern instruments to determine the amounts of substances present in a mixture down to part per million levels (ppm), and identify the structure of a compound.Techniques such as UV-visible spectroscopy, infrared spectroscopy, mass spectrometry, nuclear magnetic resonance spectroscopy, gas chromatography and high performance liquid chromatography will be covered.This course will also discuss some common standard practices of collecting and preparing samples for laboratory testing, the accreditation system in testing laboratories.This course is conducted in the format of lecture.本课程旨在介绍化学分析中所用到的现代光谱和色谱仪器的基本概念和技术。学生将学习使用该 等仪器来分析浓度水平低至百万分之一的物质,并确定化合物的结构。课程内容包括紫外 − 可见光 谱法、红外线光谱法、质谱分析法、核磁共振、气相色谱法及高效能液相色谱法的操作技巧,以 及化验工作中的收集及制备样本的常用标准技巧和香港化验室所实行的认可系统。课程以讲课形 式进行。 Medium of Instruction:

高对比度复合材料的均质化......
摘要。我们通过变异技术得出,这是在线性差异约束下对一类积分函数的限制描述。功能旨在编码高对比度复合材料的能量,即一种异质材料,在微观层面上,该材料由定期穿孔的基质组成,其腔体被填充的物理特性填充而占据。我们的主要结果提供了γ-连接分析,因为周期性趋于零,并表明功能的变化极限是两种贡献的总和,一种是由矩阵中存储的能量而产生的,另一个是由存储在包含物中的能量。由于潜在的高对比度结构,该研究在L P中的标准拓扑方面缺乏矫正性,我们通过两尺度收敛技术来解决。为了处理差异约束,我们建立了有关线性,k -th顺序,具有恒定系数和恒定等级的均质差分运算符的电势和约束的扩展运算符的新结果。

气候元数据和均质化指南
气象数据受到各种观测实践的影响。数据取决于仪器、其暴露、记录程序和许多其他因素。需要记录所有这些元数据,以便尽可能充分利用数据。本指南将确定所有类型的站点应了解的最低限度信息,例如位置和测量单位。额外的信息对于数据用户和提供者都大有裨益。本指南讨论了理想情况下应该存储的完整元数据列表,并包括最佳实践列表。完整的元数据描述了站点自建立到现在以及希望未来的历史。大多数元数据必须从站点的文档(包括当前和历史文档)中获取,而其他一些元数据可以从数据本身获取。为了提供高质量的数据集,维护全面的站点文档并保持更新至关重要。站点管理员和网络管理员应共同建立必要的程序,以确保考虑到所有元数据需求。
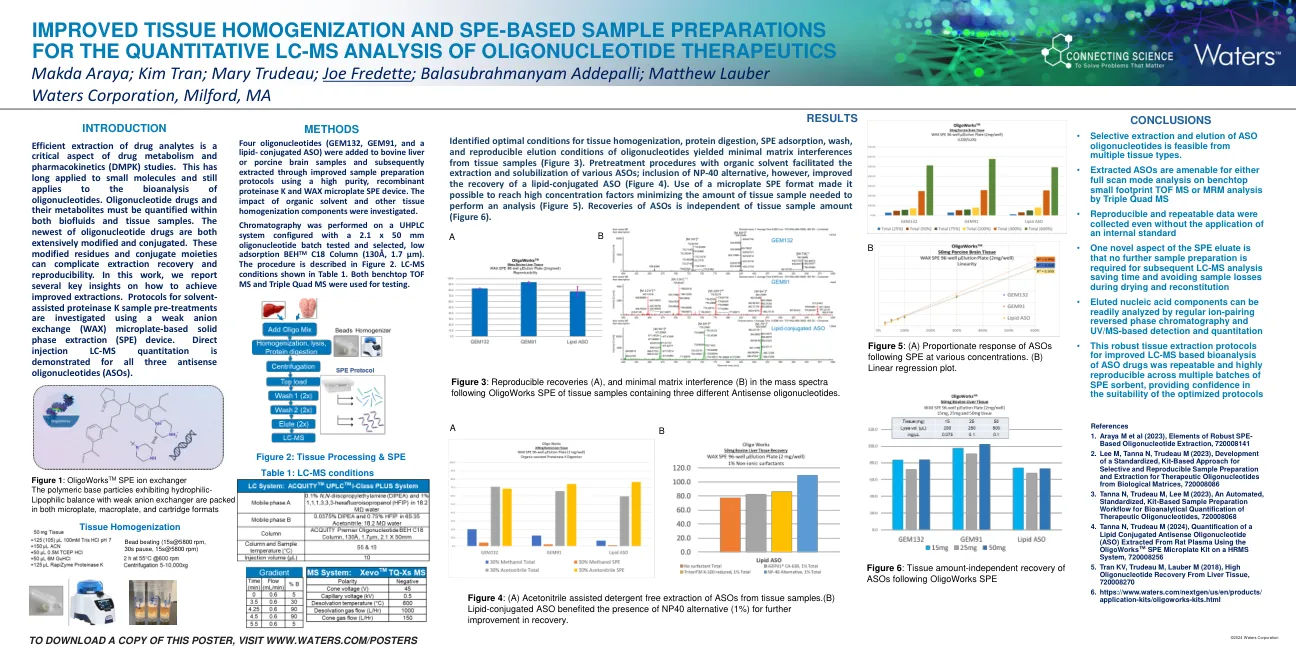
改善了组织均质化和基于SPE的样品...
有效提取药物分析物是药物代谢和药代动力学(DMPK)研究的关键方面。这长期用于小分子,仍然适用于寡核苷酸的生物分析。寡核苷酸药物及其代谢产物必须在生物流体和组织样品中进行定量。最新的寡核苷酸药物都经过广泛修饰和共轭。这些修改后的残基和共轭部分会使提取恢复和可重复性复杂化。在这项工作中,我们报告了有关如何实现改进提取的几个关键见解。使用弱阴离子交换(WAX)基于微板的固相萃取(SPE)设备来研究溶剂辅助蛋白酶K样品预处理的方案。直接注射LC-MS定量已证明了所有三种反义寡核苷酸(ASOS)的定量。

定量非线性均质化:振荡的控制
线性椭圆运算符的定量随机均质化已经被众所周知。在此贡献中,我们向前迈进了具有P-生长的单调操作员的非线性设置。这项工作致力于定量的两尺度扩展结果。通过处理2≤p<∞的指数范围d≤3,我们能够考虑真正的非线性椭圆方程和系统,例如 - a(x)(x)(1 + |∇| p-p-p-2)∇u = f(使用随机,非不必要的对称)。从p = 2到p> 2时,主要困难是分析相关的线性化操作员,其系数是退化的,无限的,并取决于通过非线性方程的解决方案的随机输入a。我们的主要成就之一是控制这种复杂的非线性依赖性,导致迈耶对线性化运算符的估计值,这是我们得出的最佳定量两尺度扩展结果的关键(这在周期性设置中也是新的)。

定量均质化障碍物问题及其自由边界
1。简介。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。2 1.1。主要结果摘要。。。。。。。。。。。。。。。。。。。。。。。。。5 1.2。手稿的组织。。。。。。。。。。。。。。。。。。。。。。。9 2。背景理论。。。。。。。。。。。。。。。。。。。。。。。。。。。10 2.1。符号。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。10 2.1.1功能空间。。。。。。。。。。。。。。。。。。。。。。。。。。。10 2.2。有用的不平等。。。。。。。。。。。。。。。。。。。。。。。。。。。。。11 2.3。均质理论,假设和已知估计值。。。。。。。12 2.3.1周期均质化。。。。。。。。。。。。。。。。。。。。。。12 2.3.2几乎是周期性的均质化。。。。。。。。。。。。。。。。。。13 2.3.3随机均质化。。。。。。。。。。。。。。。。。。。。。13 2.4。经典障碍物问题。。。。。。。。。。。。。。。。。。。。。。15 2.4.1与可测量的系数17 3。障碍问题的均质化。。。。。。。。。。。。。。。18 3.1。两个障碍问题的紧密感。。。。。。。。。。。。。。。。。。18 3.2。惩罚障碍问题。。。。。。。。。。。。。。。。。。。。。。。。20 3.3。惩罚障碍问题的均质化。。。。。。。。。。。。22 4。大规模C 1,1-溶液的常规性。。。。。。。。。。。。。。27 5。自由边界的同质化和大规模规律性。。31 5.1。自由边界的定性平坦度。。。。。。。。。。。。。。。。。33 5.2。改善平坦度。。。。。。。。。。。。。。。。。。。。。。。。。。38附录A.尺寸一中的示例。。。。。。。。。。。。。。。。。。。。。。44

高压均质化 - 其用法和理解的最新信息
https://doi.org/10.26434/chemrxiv-2022-x2cml-v2 orcid:https://orcid.org/0000-0000-0001-6216-296x chemrxiv未通过chemrxiv peer-review dectect。许可证:CC BY-NC-ND 4.0

IT和AI的发展、地方创生、少子化对策
资料来源:https://towardsdatascience.com/machine-learning-methods-to-aid-in-coronavirus-response-70df8bfc7861、https://bdtechtalks.com/2020/03/09/artificial-intelligence-covid-19-coronavirus/、https://news.yahoo.co.jp/byline/kazuhirotaira/20200326-00169744/

生物均质化可以使景观景观森林多功能
fons van van der plas a,b,1,皮特·曼宁A,B,圣地亚哥索要A,埃里克·艾伦(Eric Allan) Benneter K,Damien Bonal L,Olivier Bouriaud M,Helge Bruelheide F,N,Filippo Bussotti O,2,Monique Carnol P,Bastien Castagneyrol I,J,J,Yohan Charbonnier I,J,J,J,David Anthony Coomes Q,Andrea Coppi Or,Andrea Coppi or,Andrea Coppi C. Bastina C. Bastinans C. Bastias C. Thyme Domisch U,LeenaFinérU,Arthur Gessler V,AndréGranierL,Charlotte Grossiord W,Virginie Guyot I,J,J,X,StephanHättenschwilerY,HervéJactelI,J,J,J,Bogdan Jaroszewicz Z,François-xavavierJolyYOLY YOLY YOLYS THOMAS。 Jucker Q, Julia Koricheva AA, Harriet Milligan AA, Sandra Mueller C, Bart Muys T, Diem Nguyen BB, Martina Pollastrini or, Sophia Ratcliffe E, Karsten Raulund-Rasmussen S, Federico Selvi or, Jan Stenlid BB, Fernando Valladares R, CC, Lars Vesterdal S, DawidZielínskiZ和Markus Fischer A,B,DD

城市化推动了中国鸟类社区的生物均质化
城市化驱动的生物均质化已在本地和全球范围的各种生态系统中记录下来。但是,在发展中国家,它在很大程度上没有探索。关于不同分类单元和生物区域的实证研究表明结果颇具(即生物均质化与生物分化);因此,社区组成在响应人为障碍以及控制这一过程的因素的响应程度需要阐明。在这里,我们使用了中国760种鸟类的编译数据库来量化自然和城市组合之间的成对β多样性的多个位点β多样性和距离衰减,以评估城市化的生物质量。我们使用广义差异模型(GDM)来阐明城市化前后的空间和环境因素在鸟类社区差异中的作用。城市组合中的多个位点β多样性明显低于天然组合中的多种多样性,并且天然组合中成对相似性的距离衰减更快。这些结果在分类学,系统发育和功能方面是一致的,支持了由URBANIPAIND驱动的一般生物均质化。GDM结果表明地理距离和温度是鸟类社区差异的主要预测指标。但是,地理距离和气候因素在解释城市组合中的组成差异时的贡献减少。与自然组合相比,城市组成差异的变化要低得多,地理和环境距离的地理和环境距离要比自然组合的差异要低得多,这意味着在进一步的气候变化和人为的干扰下,模型预测的不确定性可能存在潜在的风险。我们的研究得出结论,分类,系统发育和功能维度阐明了中国城市化驱动的生物均质化。