XiaoMi-AI文件搜索系统
World File Search System并行计算

q-secure:用于资源约束的物联网设备加密
摘要 - 物联网(IoT)在塑造我们生活的不同方面起着重要作用。物联网设备由于其连接,收集和分析数据,自动化流程,提高安全性和效率并提供个性化体验的能力而变得越来越重要。但是,量子计算机开发的进步对资源受限的物联网设备构成了重大威胁。这一新一代的合并者可以打破这些物联网设备中实现的经典公钥加密计划和数字签名。在保护IoT设备免受量子计算机攻击的同时构成了许多挑战,研究人员在开发轻质的量子后加密算法方面不断取得重大进展,以实现有效的键换交换机制和量身定制的数字签名算法,以克服此问题。本文提出了Q-Secure,Q-Secure是一种用于统一资源约束设备加密的加密后的Quantum Secissivant Security Suserival。这种新颖的方案使任何物联网系统都可以利用网络中其他设备的帮助,以使用分布式和并行计算来生成给定尺寸的任何提出的量子加密密钥。索引术语 - post-quantum,物联网,加密式,5G-iot技术,基于晶格的基于晶格,isogenie,关键封装,密钥一代。
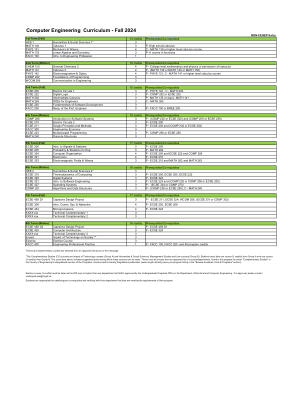
计算机工程课程 - 2024 年秋季
学分 先决条件/共同条件 ECSE 307 线性系统与控制 4 P - ECSE 206、ECSE 210 ECSE 335 微电子学 4 P - ECSE 331 ECSE 403 控制 4 P - ECSE 307 ECSE 408 通信系统 4 P - ECSE 205、ECSE 308 ECSE 412 离散时间信号处理 3 P - ECSE 206 ECSE 415 计算机视觉简介 3 P - ECSE 205、(ECSE 206 或 ECSE 316) ECSE 416 电信。网络 4 P - (ECSE 250 或 COMP 250)和 ECSE 205 和(ECSE 308 或 ECSE 316)ECSE 420 并行计算 3 P - ECSE 427 ECSE 422 容错计算 3 P - ECSE 324 和(ECSE 250 或 COMP 250)ECSE 428 软件工程实践 3 P - (ECSE 321 或 COMP 335)ECSE 435 混合信号测试技术 3 P - ECSE 206,ECSE 335 ECSE 439 软件语言工程 3 P - (ECSE 321 或 COMP 303)ECSE 508 多智能体系统 3 P - ECSE 205 或同等学历 ECSE 510 随机系统的过滤和预测 3 P - ECSE 500,ECSE 509 或同等学历ECSE 544 计算摄影 4 P - ECSE 205,ECSE 206

部分A。个人信息名称Enrique S. ...
Tectrogies,S.L。和Qsimov Quantum Computing,S.L。,总资金为150,000欧元,加上184,000美元。At the level of scientific results, I have published 151 papers in indexed journals (102 in the last 10 years, since 2014), in many cases in collaboration with researchers from centers such as The University of Texas at Austin, University of Tennessee at Knoxville, The University of Manchester, Karlsruhe Institute of Technology, Max Planck Institute for Dynamics of Complex Technical Systems, École Polytechnique FédéraledeLausanne(EPFL),IBM ResearchZürich和Argonne National Laboratory。这些出版物中有很多是由19个博士学位的监督(过去十年中的11个)的结果。毕业后,其中一些博士是由Google慕尼黑(G. Flegar),Cern(X。Valls),EthZürich(T. Smith),巴塞罗那超级计算中心(S.Catalán),DKRZ Hamburg(M.F。Dolz)和Univ等公司聘用的。de valladolid(R。Carratalá)。我目前是期刊ACM Trans的区域编辑器。数学计算和并行计算。过去,我曾担任《杂志并发与计算:实践与经验》的4期特殊问题的客座编辑,《超级计算杂志》的特刊,《平行计算》杂志的特刊以及《 Int杂志》的特刊。高性能计算和应用。

IAC-23,D1,1,5,x79712 空间量子计算 - ORBilu
量子电路是量子计算的基本计算模型。它由一系列量子门组成,这些量子门作用于一组量子比特以执行特定的计算。对于量子电路的实现,可编程纳米光子芯片提供了具有大量量子比特的有希望的基础。当前的研究探索了在可编程纳米光子芯片上实现量子电路用于太空技术的可能性。最近的研究结果表明,量子电路比传统电路具有多项优势,例如指数级加速、多重并行计算和紧凑的尺寸。除此之外,纳米光子芯片还具有许多优于传统芯片的优势。它们提供高速数据传输,因为光比电子传播得更快。光子传输数据所需的能量比电子少,因此纳米光子芯片比传统芯片消耗的功率更少。纳米光子芯片的带宽大于传统芯片的带宽,因此它们可以同时传输更多数据。它们可以轻松缩放到更小的尺寸,密度更高,并且比传统芯片更能抵御极端温度和辐射。本研究的重点是量子电路如何通过为各种与太空相关的应用提供更快、更高效的计算来彻底改变太空技术。所有深入分析都是在考虑当前可用的最先进技术的情况下进行的。

用于解决 MAXCUT 的随机神经形态电路
摘要 — 寻找图的最大割点 (MAXCUT) 是一个经典的优化问题,它推动了并行算法的开发。虽然 MAXCUT 的近似算法提供了有吸引力的理论保证并展示了令人信服的经验性能,但这种近似方法可能会将主要的计算成本转移到随机采样操作上。神经形态计算利用神经系统的组织原理来启发新的并行计算架构,提供了一种可能的解决方案。自然大脑的一个普遍特征是随机性:生物神经网络的各个元素都具有内在的随机性,这是实现其独特计算能力的资源。通过设计利用与自然大脑类似的随机性的电路和算法,我们假设微电子设备中的内在随机性可以转化为神经形态架构的宝贵组成部分,从而实现更高效的计算。在这里,我们展示了神经形态电路,它将一组随机设备的随机行为转化为有用的相关性,从而为 MAXCUT 提供随机解决方案。我们表明,与软件求解器相比,这些电路的性能更佳,并认为这种神经形态硬件实现提供了扩展优势的途径。这项工作展示了将神经形态原理与内在随机性相结合作为新计算架构的计算资源的实用性。
![arXiv:2003.04930v1 [quant-ph] 2020 年 3 月 10 日](/simg/b\b941c74a8b9f4500017798a3f6f0c5ad7ab13579.webp)
arXiv:2003.04930v1 [quant-ph] 2020 年 3 月 10 日
Google PageRank 是一种流行且有用的算法,用于对网络中节点或网站的重要性进行排名,最近有人提出了一种 PageRank 算法的量子对应算法,与 Google PageRank 相比,该算法的排名准确率更高。量子 PageRank 算法本质上基于量子随机游动,可以用 Lindblad 主方程表示,然而,该算法需要求解 O(N4) 维的 Kronecker 积,并且当网络中的节点数 N 增加到 150 以上时,需要大量的内存和时间。在这里,我们提出了一种高效的量子 PageRank 求解器,使用 Runge-Kutta 方法将矩阵维数降低到 O(N2),并使用 TensorFlow 进行 GPU 并行计算。我们在为多达 922 个节点的美国主要航空公司网络求解量子 PageRank 时展示了其性能。与之前的量子 PageRank 求解器相比,我们的求解器将所需的内存和时间分别大幅减少到仅为 1% 和 0.2%,这使得它在 100 秒内就可以在具有 4-8 GB 内存的普通计算机上运行。这种高效的大规模量子 PageRank 和量子随机游走求解器将极大地促进实际应用中的量子信息研究。

电气和计算机工程部
计算机工程的课程要求围绕着大量的工程核心课程以及电气工程和计算机科学所需的课程。数学,基础科学和工程科学的要求提供了所有工程学科所需的范围。基本的电气工程要求包括电路理论,电子和数字设备,这些设备由计算机架构中的高级课程以及计算机辅助设计的数字系统设计。基本的计算机科学课程包括一个协调的顺序,该顺序提供了数据结构,算法,面向对象的编程,软件工程,实时应用程序和软件开发工具方面的基本知识。这些课程是在多个平台上开发的,并基于Python语言。还提供了数据通信和计算机网络,算法和操作系统中的高层课程。希望获得通信,并行计算,VLSI,嵌入式系统或信号处理的学生可以通过从认可的列表中选择的技术选修课或与教职员工顾问协商的技术选修课来实现这一目标。所需的沟通技巧,社会科学和人文科学课程提供了在基于广泛的教育中传统的非技术领域的研究。Capstone高级设计课程要求学生应用新发现的知识并探索企业家精神。学生研究和确定问题,并在使用硬件和软件组合来开发解决方案的团队中工作。批判性和最终设计评论使学生能够发展其专业演示能力。

Tongsheng Geng、Marcos Amaris、Stéphane Zuckerman、Alfredo Goldman、Guang Gao 等人。一种基于配置文件的人工智能辅助异构架构动态调度方法。国际并行编程杂志,2022 年,50 (1),第 115-151 页。 10.1007/s10766-021-00721-2。hal-03606185
虽然异构架构在高性能计算系统中越来越受欢迎,但其有效性取决于调度程序将工作负载分配到合适的计算设备上的效率,以及通信和计算如何重叠。随着不同类型的资源集成到一个系统中,调度程序的复杂性也相应增加。此外,对于在不同异构资源上具有不同问题规模的应用程序,最佳调度方法可能会有所不同。因此,我们引入了一种基于配置文件的人工智能辅助动态调度方法,以动态和自适应地调整工作负载并有效利用异构资源。它结合在线调度、应用程序配置文件信息、硬件数学建模和离线机器学习估计模型,实现异构架构的自动应用设备特定调度。硬件数学模型提供粗粒度计算资源选择,而配置文件信息和离线机器学习模型估计细粒度工作负载的性能,在线调度方法动态自适应地分配工作负载。我们的调度方法在事件驱动的运行时系统中对控制规则应用程序、2D 和 3D Stencil 内核(基于 Jacobi 算法)和数据不规则应用程序稀疏矩阵向量乘法 (SpMV) 进行了测试。实验结果表明,PDAWL 的表现与产生最佳结果的 CPU 或 GPU 相当或远远优于后者。关键词:异构多核计算、工作负载平衡、自适应建模、机器学习辅助调度、并行计算

人工智能芯片入门——它们是什么以及为什么重要
引言和总结 3 芯片创新的规律 7 晶体管缩小:摩尔定律 7 效率和速度改进 8 提高晶体管密度可实现改进的设计,从而提高效率和速度 9 晶体管设计正在达到基本尺寸极限 10 摩尔定律的放缓和通用芯片的衰落 10 通用芯片的规模经济 10 成本增长速度快于半导体市场 11 半导体行业的增长率不太可能增加 14 随着摩尔定律的放缓,芯片得到了改进 15 晶体管的改进仍在继续,但速度正在放缓 16 提高晶体管密度可实现专业化 18 AI 芯片动物园 19 AI 芯片类型 20 AI 芯片基准 22 最先进 AI 芯片的价值 23最先进的人工智能芯片意味着成本效益 23 计算密集型人工智能算法受到芯片成本和速度的瓶颈制约 26 美国和中国的人工智能芯片及其对国家竞争力的影响 27 附录 A:半导体和芯片基础知识 31 附录 B:人工智能芯片的工作原理 33 并行计算 33 低精度计算 34 内存优化 35 领域特定语言 36 附录 C:人工智能芯片基准研究 37 附录 D:芯片经济模型 39 芯片晶体管密度、设计成本和能源成本 40 代工、组装、测试和封装成本 41 致谢 44

Q-EEGNet:一种用于边缘运动想象脑机接口的节能 8 位量化并行 EEGNet 实现
摘要 —运动想象脑机接口 (MI- BMI) 通过分析脑电图 (EEG) 记录的大脑活动,实现人脑与机器之间直接且可访问的通信。延迟、可靠性和隐私限制使得将计算转移到云端并不合适。实际使用案例需要可穿戴、电池供电且平均功耗低的设备以便长期使用。最近,出现了用于分类 EEG 信号的复杂算法,尤其是深度学习模型。虽然这些模型达到了出色的准确性,但由于其内存和计算要求,它们通常会超出边缘设备的限制。在本文中,我们展示了 EEGN ET 的算法和实现优化,EEGN ET 是一种适用于许多 BMI 范式的紧凑型卷积神经网络 (CNN)。我们将权重和激活量化为 8 位定点,4 类 MI 的准确度损失为 0.4%,可忽略不计,并利用其定制的 RISC-V ISA 扩展和 8 核计算集群,在 Mr. Wolf 并行超低功耗 (PULP) 片上系统 (SoC) 上实现了节能的硬件感知实现。通过我们提出的优化步骤,与单核分层基线实现相比,我们可以获得 64 倍的整体加速和高达 85% 的内存占用减少。我们的实现仅需 5.82 毫秒,每次推理消耗 0.627 mJ。凭借 21.0 GMAC/s/W,它的能效比 ARM Cortex-M7 上的 EEGN ET 实现(0.082 GMAC/s/W)高 256 倍。索引词——脑机接口、边缘计算、并行计算、机器学习、深度学习、运动意象。