XiaoMi-AI文件搜索系统
World File Search System未知的
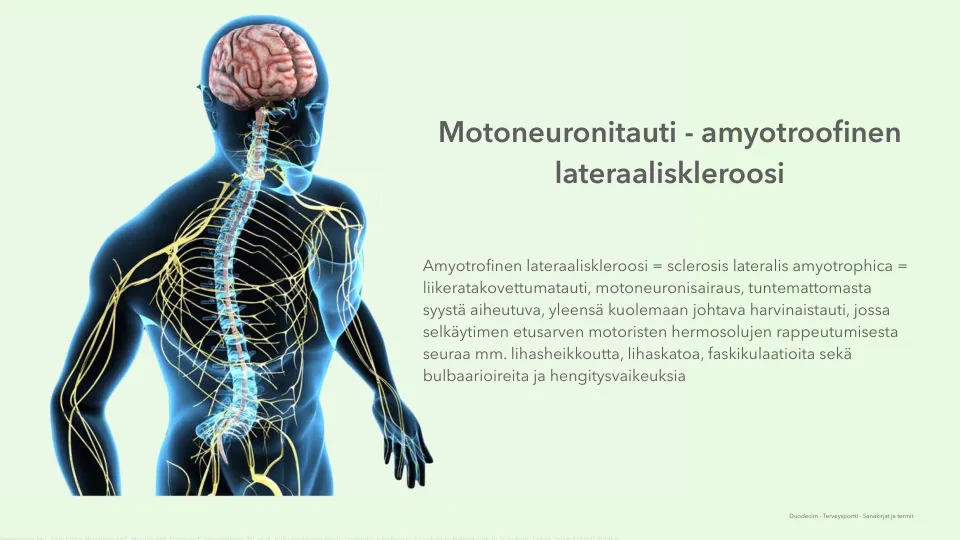
运动神经元疾病 - 氨基卫星侧硬化
肌萎缩性侧面硬化症=硬化症latetrophica =商业胎面胎面,运动神经元疾病,未知的稀有疾病,通常是由于未知的死亡原因,脊髓中运动神经细胞的退化。肌肉无力,肌肉丧失,迷人,鳞茎症状和呼吸困难

用于图形搜索问题的基于学习的算法
我们考虑了Banerjee等人最近引入的预测图形搜索问题。(2023)。在此问题中,从某个顶点r开始的代理必须使用A(可能未知的)图G找到隐藏的目标节点G,同时最小化总距离。我们研究一个设置,在该设置中,在任何节点V中,代理都会收到从V到G的距离的嘈杂估计。我们在未知的图表上为此搜索任务设计算法。我们在未知的加权图上建立了第一个正式保证,并提供了下限,表明我们提出的算法对预测误差具有最佳或几乎最佳的依赖性。此外,我们进行了数值实验,证明除了对对抗性误差造成反对,我们的算法在误差是随机的典型情况下都很好地形成。最后,我们在Banerjee等人的属性上提供了更改的天然简单性能界限。(2023)对于在已知图表上进行搜索的情况,并为此设置建立新的下限。
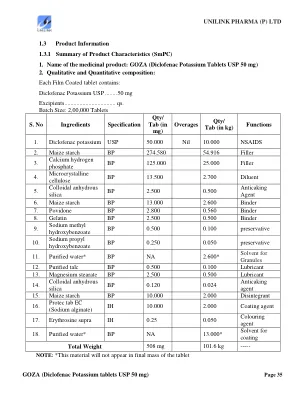
goza(双氯芬酸钾片USP 50 mg)
以下不良影响包括与其他短期或长期使用报告的效果。血液和淋巴系统疾病非常罕见的血小板减少症,白细胞减少症,贫血(包括淋巴结和性贫血),肿瘤细胞增多症。免疫系统疾病罕见的超敏反应,过敏反应和过敏反应(包括低血压和休克)。非常罕见的Angioneyerotic水肿(包括面部水肿)。精神疾病非常罕见的迷失方向,抑郁,失眠,噩梦,烦躁,精神病。神经系统疾病常见的头痛,头晕。罕见的脾气暴躁,疲倦。非常罕见的时代症,记忆力障碍,抽搐,焦虑,震颤,无菌性脑膜炎,味觉障碍,脑血管事故。未知的混乱,幻觉,感觉不适的眼睛疾病非常罕见的视觉障碍,视力模糊,复视。未知的视神经炎。耳朵和迷宫疾病常见的眩晕。非常罕见的耳鸣,听力受损。心脏疾病不常见*心肌梗死,心脏衰竭,呼吸症,胸痛。未知的Kounis综合征血管疾病





人工智能:强大的诉讼工具
一些律师害怕人工智能。它是新的。它是未知的。它会取代我们吗?对未知的恐惧是一种常见的防御机制。但是,如果我们把头埋在沙子里,我们更勇敢的对手就会使用这项技术,让我们处于竞争劣势。另一方面,一些律师将人工智能视为灵丹妙药。他们设想只要按一下按钮,我们的简报就会为我们写好,上面还打上一个漂亮的蝴蝶结。这两种观点都过于简单了。人工智能是一种工具。与任何其他工具或技术进步一样,它有优点和缺点。为了正确使用人工智能,我们必须理解并利用它的好处,同时理解并尊重它目前的局限性。人工智能的速度和效率优势不算什么

科学学士学位(B.Sc.)教学大纲
单元详细信息i人工智能介绍(AI)的AI工具历史记录,用于AI编程及其概述什么是认知科学以及AI搜索智能代理的感知应用问题的问题,未知的搜索搜索技术,未知的搜索技术1-通过搜索空间,搜索搜索技术2-搜索搜索技术2-搜索搜索,并实现了搜索,并实现了搜索,并实现了搜索,并进行了搜索,并实现了搜索,并进行了搜索,并实现了搜索,并实现了搜索,并实现了搜索,并实现了搜索,并实现了验证,并实现了验证,并实现了策略,并实现了策略,并实现了策略,并实现了策略, A*算法,AO*算法对抗搜索,游戏玩

mathias-miedreich-优秀的起始位置-。......
请读者注意,前瞻性陈述包括已知和未知的风险,并受重大商业、经济和竞争不确定性和偶然性的影响,其中许多超出了优美科的控制范围。