XiaoMi-AI文件搜索系统
World File Search System标准偏差

数据驱动的预防性护理分配,并应用于糖尿病
Age (in years) 47.07 17.93 46.84 18.32 50.62 9.28 Sex (0=male; 1=female) 0.51 0.50 0.50 0.50 0.54 0.50 Systolic blood pressure (in mm Hg) 122.84 17.11 122.54 16.51 127.43 24.01 Diastolic blood pressure (in mm Hg) 77.26 12.78 77.16 12.93 78.80 10.12体重指数(以kg/m 2)29.05 5.64 28.95 5.62 30.52 5.73 HBA1C(in%)5.56 0.36 0.36 5.36 5.34 0.34 5.34 5.87 5.87 0.34 SD =标准偏差

第28届全球年度首席执行官调查 - 亚太地区
索引分数值来自对公司在过去五年中采取以下措施的范围的因素分析:开发的创新产品或服务,实施了与其他组织合作的新定价模型,针对新的市场途径;并针对新的客户群。索引分数值代表与平均值的标准偏差 - 更高的分数表示更多的重塑。橙线代表回归建模的预测,该预测是针对利润率调整的调整(上一个财政年度),首席执行官任期,市场集中度,所有权,员工人数,行业部门和领土;阴影区域代表95%可靠的间隔。

第28届年度全球首席执行官调查 - 泰国
注意:索引分数值来自对公司在过去五年中采取以下行动的范围的因素分析:开发的创新产品或服务,实施了新的定价模型,与其他组织合作,针对新的市场途径;并针对新的客户群。索引分数值代表与平均值的标准偏差 - 更高的分数表示更多的重塑。橙线代表回归建模的预测,根据利润率调整了(上一个财政年度),首席执行官任期,市场集中度,所有权,员工人数,行业部门和地区;阴影区域代表95%可靠的间隔。

某些替代密码的进化关系
讨论:发现表明,异常检测方法在减少侵入检测系统中的假阳性方面起着至关重要的作用。卡方和ANOVA测试的重要p值证实,这些方法比传统技术更有效地最大程度地减少了误报。如标准偏差所示,假阳性率的可变性表明,虽然异常检测通常提高精度,但其有效性可能会取决于特定的实施和网络条件。这些见解强调了精炼异常检测算法以进一步提高准确性并减少错误警报的重要性。

基于...
内部语音是一种自我指导的对话形式,它在认知发展,语音监测,执行功能和心理病理学中起着重要作用。尽管对其现象学,发展和功能的知识越来越多,但对内部语音的科学研究的方法仍然存在差异,并且在很大程度上是不整合的。脑电图(EEG),它是一种非侵入性脑部计算机界面(BCI)的方法,为内部语音研究带来了新的选择。由于脑电图的优势,越来越多的研究与内部语音有关。在此贡献中,内部语音中表达的不同单词通过应用EEG信号和支持向量机(SVM)来区分。使用向公众开放的“大声思考”数据集的脑电图数据。在实验中,从位于头顶上的128个传感器中获取了许多脑电图数据。因此,在第一个步骤中填写数据。之后,选定的数据通过经验模式分解(EMD)分解为各种固有模式函数(IMFS)。此外,使用希尔伯特变换来转换IMF,以检查适合区分内部语音的脑波带。最后,IMF的单个或组合由支持向量机(SVM)与各种内核进行分类。使用最合适的IMF和内核时,每个主题方案的平均结果为:F-评分:99.24%,准确性:99.24%和标准偏差(SD):0.95。所有主题方案的最佳结果是:F-评分:99.67%,准确性:99.66%和标准偏差(SD):0.27。获得的结果表明,所提出的方法可以很好地与内部语音差异。

全差分电容耦合高 CMRR 低...
摘要 干电极的使用正在迅速增加。由于干电极的阻抗很高,因此在电极和放大器之间的连接节点处有一个高阻抗节点。这会导致吸收电力线信号,而高 CMRR 放大器对于消除这种情况至关重要。在本文中,我们提出了一种具有高 CMRR 的低功耗低噪声斩波稳定放大器。为了最大限度地降低输入参考噪声,采用了基于反相器的差分放大器。同时,设计了一个直流伺服环路来抑制电极的直流偏移。由于所有级都需要共模反馈,因此每个放大器都使用了合适的电路。此外,在最后一级实施了斩波尖峰滤波器以衰减斩波器的尖峰。最后,为了消除失配和后期布局造成的偏移效应,采用了直流偏移抑制技术。设计的电路采用标准 180 nm CMOS 技术进行仿真。设计的斩波放大器在 1.2 V 电源下仅消耗 1.1 l W。中频带增益为 40 dB,带宽为 0.5 至 200 Hz。其带宽内的总输入参考噪声为 1 l V rms。因此,设计电路的 NEF 和 PEF 分别为 2.7 和 9.7。为了分析所提出的斩波放大器在工艺和失配变化下的性能,进行了蒙特卡罗模拟。根据 200 次蒙特卡罗模拟,CMRR 和 PSRR 分别为 124 dB(标准偏差为 6.9 dB)和 107 dB(标准偏差为 7.7 dB)。最终,总面积消耗为 0.1 mm 2(不含焊盘)。

机器学习和人工智能系统的数据代表性
图 3. 使用覆盖样本与使用完整人口普查加州训练数据相比,在 10 次迭代采样和训练线性回归模型时平均性能改善/恶化。覆盖样本占完整人口普查训练数据的 20%。误差线表示标准偏差。正值表示在覆盖样本上训练的模型的平均 MSE 比完整人口普查训练数据模型的平均 MSE 有所改善。负值表示与使用完整人口普查训练数据相比,抽样会降低性能。所有州的平均性能提高了 2.1%。

增材制造 316L 不锈钢
[1] 免责声明:本数据表中发布的所有数据仅供参考,不足以设计或认证零件。不对这些结果提供任何保证或担保。[2] 界限基于每个方向和机器的每个总体的十个样本的一个标准偏差。测试样本是从试样 (75x75x13mm) 加工而成的直径为 6.35 毫米的圆棒。方向 XY 数据是 X 和 Y 水平构建方向的平均值。[3] 使用其他粉末切割 (316L-D) 和/或 AM 工艺 (DED 和 PBF-EB) 生产的 AM 构建的工艺参数和热处理可根据特定应用要求进行优化。
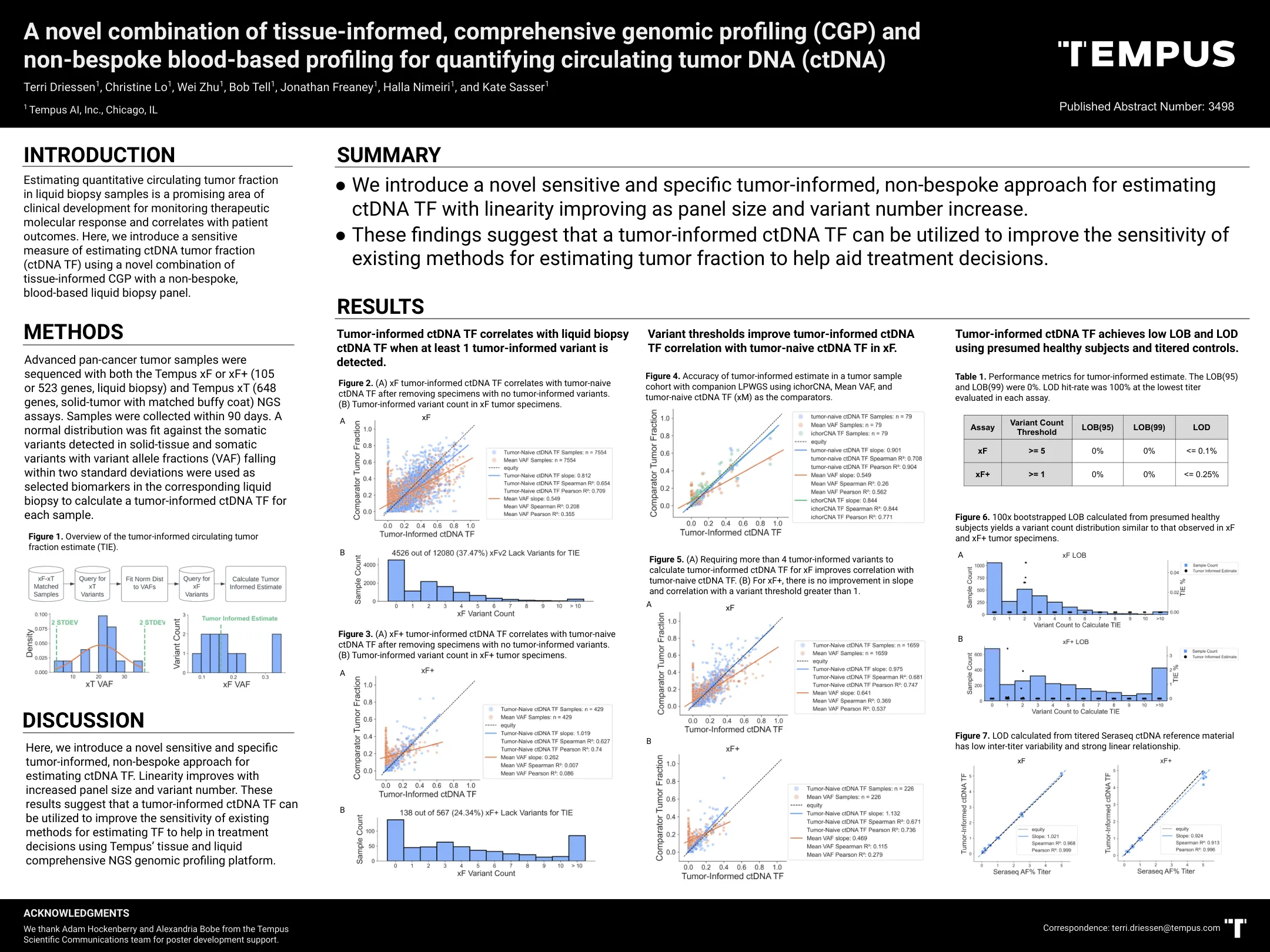
估计液体活检样品中定量循环肿瘤分数是监测治疗摩尔的临床发展领域
与TEMPUS XF或XF+(105或523基因,液体活检)和Tempus XT(648个基因,具有匹配的Buffy Coat匹配的固体肿瘤)NGS NGS测定法对晚期泛体肿瘤样品进行测序。在90天内收集样品。在固体组织和体细胞变体中检测到的躯体变异符合正态分布,并将落入两个标准偏差内的变异等位基因级分(VAF)作为相应液体活检中的选定生物标志物,以计算每个样品的肿瘤 - 信息CTDNA TF。

基于...
内部语音是一种自我指导的对话形式,它在认知发展,语音监测,执行功能和心理病理学中起着重要作用。尽管对其现象学,发展和功能的知识越来越多,但对内部语音的科学研究的方法仍然存在差异,并且在很大程度上是不整合的。脑电图(EEG),它是一种非侵入性脑部计算机界面(BCI)的方法,为内部语音研究带来了新的选择。由于脑电图的优势,越来越多的研究与内部语音有关。在此贡献中,内部语音中表达的不同单词通过应用EEG信号和支持向量机(SVM)来区分。使用向公众开放的“大声思考”数据集的脑电图数据。在实验中,从位于头顶上的128个传感器中获取了许多脑电图数据。因此,在第一个步骤中填写数据。之后,选定的数据通过经验模式分解(EMD)分解为各种固有模式函数(IMFS)。此外,使用希尔伯特变换来转换IMF,以检查适合区分内部语音的脑波带。最后,IMF的单个或组合由支持向量机(SVM)与各种内核进行分类。使用最合适的IMF和内核时,每个主题方案的平均结果为:F-评分:99.24%,准确性:99.24%和标准偏差(SD):0.95。所有主题方案的最佳结果是:F-评分:99.67%,准确性:99.66%和标准偏差(SD):0.27。获得的结果表明,所提出的方法可以很好地与内部语音差异。