XiaoMi-AI文件搜索系统
World File Search System棋盘

抑制脂肪酸氧化作为治疗原发性阿米巴脑膜脑炎的新靶点
摘要 原发性阿米巴脑膜脑炎 (PAM) 是一种由自由生活的阿米巴原虫 Naegleria 引起的迅速致命的感染。阿米巴沿着大脑神经迁移到大脑,导致癫痫、昏迷并最终导致死亡。先前的研究表明,N. fowleri 的近亲 Naegleria gruberi 更喜欢将脂质而不是葡萄糖作为能量来源。因此,我们测试了几种已经批准的脂肪酸氧化抑制剂以及目前使用的药物两性霉素 B 和米替福新。我们的数据表明,乙莫克舍、奥利司他、哌克昔林、硫利达嗪和丙戊酸可抑制 N. gruberi 的生长。然后我们在 N. fowleri 上测试了这些化合物,发现乙莫克舍、哌克昔林和硫利达嗪是有效的生长抑制剂。因此,脂质不仅是N. gruberi 的首选食物来源,而且脂肪酸的氧化似乎对N. fowleri 的生长也至关重要。抑制脂肪酸氧化可能带来新的治疗选择,因为硫利达嗪可以在感染部位达到的浓度下抑制N. fowleri 的生长。它还可以增强目前使用的治疗方法,因为棋盘分析显示米替福新和乙莫克舍之间存在协同作用。应进行动物试验以确认这些抑制剂的附加值。虽然针对这种罕见疾病开发新药和进行随机对照试验几乎是不可能的,但抑制脂肪酸氧化似乎是一种有前途的策略,因为我们展示了几种正在或曾经使用的药物的有效性,因此将来可以重新用于治疗 PAM。

人类视觉感觉刺激对N1b振幅的影响
摘要:众所周知,具有自适应机制已知。视觉也不例外,其灵敏度的输入依赖性变化。最近的动物工作表明,视觉皮层中神经元之间的连通性增强。本实验的目的是评估一种人类模型,该模型通过快速的视觉刺激来无创地改变人类视觉皮层中N1b成分的振幅。十九个参与者(M = 24岁;男性为52.6%)完成了涉及在视觉场中双侧呈现的黑白逆转棋盘的快速视觉刺激范式。eeg数据,该数据由四个主要阶段,tetanus块,光刺激,tetanus早期和tetanus组成。计算了t前,tetanus的N1b成分的幅度,te虫早期的tetanus和tetanus后期视觉诱发电位。通过从tetanus早期和晚期减去teTanus n1b振幅来计算N1b振幅的变化。结果表明,前tetanus n1b(M = -0.498 µ V,SD = 0.858)和N1B早期(M = -1.011 µ V,SD = 1.088),T(18)= 2.761,P = 0.039,D = 0.633,在tetanus n1b和n1b晚期之间没有观察到差异(p = 0.36)。总而言之,我们的发现表明,有可能诱导人类视觉上的视觉诱发潜在的N1b波形的幅度变化。如果是这样,这将允许检查增强的神经连通性及其与多种人类感觉刺激和行为的相互作用。还需要进行其他工作来证实这项研究中观察到的N1b成分的增强是由于在先前动物研究中观察到的大脑认知结构中表现出的长期增强神经联系所必需的相似机制。

使用神经网络在国际象棋中检测公平侵犯 *
本研究应对在国际象棋中区分人类和计算机产生的游戏的挑战,对于确保在线和锦标赛的完整性和公平性至关重要。随着未经授权的计算机援助变得越来越复杂,我们利用顺序的神经网络来分析大量的国际象棋游戏数据集,采用了传统引擎(例如Stockfish和Leela),以及Maia的创新神经网络,例如Maia及其单个子模型。此分析将centipawn偏差指标纳入了衡量典型的计算机策略,迈亚对人类和特质游戏风格的见解以及对移动的时间分布的评估。我们的方法通过考虑移动序列的战略含义以及在不同的游戏条件下游戏的一致性而扩展,从而增强了我们对人与AI游戏之间细微差异的理解。值得注意的是,我们的算法在识别国际象棋发动机的使用方面达到了约98%的准确性,从而在维持游戏的完整性方面做出了重大进步。为了进一步验证我们的发现,我们使用单独的数据集进行了交叉验证,从而确认了模型的鲁棒性。我们还探索了该算法在其他棋盘游戏中检测AI援助的适用性,这表明其更广泛使用的潜力。这项研究强调了机器学习在打击数字作弊方面的关键作用,强调需要连续适应检测方法以保持发展的发展。此外,我们的发现指出了为游戏中使用AI的道德准则的重要性,从而确保了所有参与者的公平和水平的竞争环境。最后,通过发布我们的方法论和AI检测的标准,我们旨在促进游戏社区内和开发人员之间的公开对话,从而促进透明度和合作,以打击作弊。

用于虚拟现实应用的新型混合脑机接口,采用基于稳态视觉诱发电位的脑机接口和基于眼电图的眼动追踪来提高信息传输速率
基于脑电图 (EEG) 的脑机接口 (BCI) 近来在虚拟现实 (VR) 应用中引起越来越多的关注,成为一种有前途的工具,可以“免提”方式控制虚拟物体或生成命令。视频眼动图 (VOG) 经常被用作一种工具,通过识别屏幕上的注视位置来提高 BCI 性能,然而,当前的 VOG 设备通常过于昂贵,无法嵌入到实用的低成本 VR 头戴式显示器 (HMD) 系统中。在本研究中,我们提出了一种新颖的免校准混合 BCI 系统,该系统结合了基于稳态视觉诱发电位 (SSVEP) 的 BCI 和基于眼电图 (EOG) 的眼动追踪,以提高 VR 环境中九目标基于 SSVEP 的 BCI 的信息传输速率 (ITR)。在以 3×3 矩阵排列的三种不同频率配置的模式反转棋盘格刺激上重复实验。当用户注视九种视觉刺激中的一种时,首先根据用户的水平眼球运动方向(左、中或右)识别包含目标刺激的列,并使用从一对电极记录的水平 EOG 进行分类,该电极可以很容易地与任何现有的 VR-HMD 系统结合使用。请注意,与 VOG 系统不同,可以使用与记录 SSVEP 相同的放大器来记录 EOG。然后,使用多元同步指数 (EMSI) 算法的扩展(广泛使用的 SSVEP 检测算法之一)在选定列中垂直排列的三个视觉刺激中识别目标视觉刺激。在我们对 20 名佩戴商用 VR-HMD 系统的参与者进行的实验中,结果表明,与 VR 环境中基于传统 SSVEP 的 BCI 相比,所提出的混合 BCI 的准确度和 ITR 均显着提高。

“人类应该敬畏人工智能的进步......
2016 年 3 月,谷歌的 AlphaGo 计算机程序在以难度高、抽象性著称的中国古代棋盘游戏围棋中击败了围棋大师李世石 [参考:卫报],这被视为人工智能进步的又一例证。它紧随 IBM 的“深蓝”和“沃森”的脚步。前者于 1997 年击败了国际象棋世界冠军加里·卡斯帕罗夫 [参考:时代杂志],后者是另一台 IBM 机器,于 2011 年击败了美国电视智力竞赛节目《危险边缘!》的两位前冠军,展示了理解自然语言问题的能力 [参考:TechRepublic]。然而,人工智能不仅仅被用来在游戏中击败人类——对于某些人来说,它的影响将深远——德国的开发人员甚至提出,机器人可能被用来教难民儿童语言 [参考:Deutsche Welle]。目前,人工智能正在许多领域得到发展,例如无人驾驶运输、金融、欺诈检测,以及机器人技术和文本和语音识别等众多应用。因此,人工智能的支持者认为:“这对人类来说是一个巨大的机遇,而不是威胁”[参考:赫芬顿邮报],并认为能够学习完成目前需要人类完成的任务的机器可以加快进程,让人类在未来有更多的闲暇时间[参考:泰晤士报]。但批评者担心,如果我们开发出能够快速学习、驾驶我们的汽车和完成我们工作的机器,我们可能会遇到它们变得比人类更聪明的情况——从而对人类在工作场所的未来以及我们在世界上更广泛的地位构成生存问题。鉴于人工智能的各个方面(例如深度学习)的不断发展[参考:Tech World],反对者怀疑它是否会在某个时候发展出自己的利益并主宰人类,或者在特定情况下对我们造成伤害。鉴于这些担忧,我们是否应该担心人工智能技术的进步?

多晶阴极非均匀热电子发射的物理模型
开发了一种新的基于物理的模型,该模型可以准确预测从温度限制 (TL) 到全空间电荷限制 (FSCL) 区域的热电子发射发射电流。对热电子发射的实验观测表明,发射电流密度与温度 (J − T) (Miram) 曲线和发射电流密度与电压 (J − V) 曲线的 TL 和 FSCL 区域之间存在平滑过渡。了解 TL-FSCL 转变的温度和形状对于评估阴极的热电子发射性能(包括预测寿命)非常重要。然而,还没有基于第一原理物理的模型可以预测真实热电子阴极的平滑 TL-FSCL 转变区域,而无需应用物理上难以证明的先验假设或经验现象方程。先前对非均匀热电子发射的详细描述发现,3-D空间电荷、贴片场(基于局部功函数值的阴极表面静电势不均匀性)和肖特基势垒降低的影响会导致从具有棋盘格空间分布功函数值的模型热电子阴极表面到平滑的TL-FSCL过渡区域。在这项工作中,我们首次为商用分配器阴极构建了基于物理的非均匀发射模型。该发射模型是通过结合通过电子背散射衍射(EBSD)获得的阴极表面晶粒取向和来自密度泛函理论(DFT)计算的面取向特定的功函数值获得的。该模型可以构建阴极表面的二维发射电流密度图和相应的 J-T 和 J-V 曲线。预测的发射曲线与实验结果非常吻合,不仅在 TL 和 FSCL 区域,而且在 TL-FSCL 过渡区域也是如此。该模型提供了一种从商用阴极微结构预测热电子发射的方法,并提高了对热电子发射与阴极微结构之间关系的理解,这对真空电子设备的设计大有裨益。

围棋作为人工智能研究领域的挑战
1.0 简介 计算机程序几乎在各个游戏层面上都在挑战人类的表现:世界西洋双陆棋冠军是一个神经网络程序 [7]。国际象棋程序(最初是人工智能搜索技术研究的雏形)的性能处于大师级别:1994 年,世界上等级分最高的国际象棋选手卡斯帕罗夫在一场计时锦标赛中被计算机国际象棋程序击败,不过他还没有输过一场不计时比赛。然而,这些顶级程序早已不再能启发或教导人工智能和认知科学研究人员如何将人类认知的灵活性和技巧融入计算机程序。数十年的国际象棋研究中得出的一个常见误解是,一旦问题得到正式指定,利用良好的搜索和评估算法的蛮力技术就足以解决任何问题。围棋领域与这种常见误解相矛盾。正式指定围棋规则很容易,然而,所有当前程序的表现都比不上人类,甚至连初级中级玩家的水平都比不上。最初,我们认为国际象棋和围棋之间程序性能的差异与相对分支因子有关,因此也与国际象棋和围棋的相对复杂性有关。虽然围棋的分支因子确实要大得多,这对编程有相当大的影响(如表 1 所示),但我们逐渐意识到,这两种游戏中战略和战术之间的差异更为重要。在国际象棋中,棋盘位置的良好评估函数通常仅通过战术手段就可以估计出来——也就是说,搜索可能的走法树,直到发现位置强度的重大变化。在围棋中,战术考虑涉及争夺特定的棋子组(定义见第 2.1 节),而战略考虑涉及构建棋子组,这些棋子组将在后期对游戏产生巨大影响。人类棋手要想在国际象棋和围棋中表现出色,就必须精通战略和战术。在国际象棋程序中,战术技能与长远搜索技术相结合足以产生出色的表现。这些技术在围棋程序中失败了,原因我们将在下文中讨论。

Bills-116rcp68-JES-Division-G.pdf
I.简介1在2021年1月,拜登政府发布了两项行政命令,这些命令可能塑造政策,基础设施发展和美国就业。首先,第14005号行政命令:“确保所有美国工人在整个美国的未来”“最大程度地利用在美国提供的商品,产品和材料以及所提供的服务的商品,产品和材料”,第二次执行订单14008:“在家中和国内的气候危机来解决倡议,以促进清洁能源过渡和开发的倡议,以促进清洁能源过渡和开发的倡议。在其许多含义中,这些秩序应该是促进美国矿物质生产的基础,尤其是支持可再生能源技术和基础设施所需的矿物,包括铜,镍,锰,石墨,石墨,锂,钴,钴等等。为了支持这一点,国际能源局最近报告说:“达成巴黎协定目标的一致努力。。。将意味着到2040年,清洁能源技术的矿物质需求是四倍。” 2美国拥有丰富的矿产储量,使政府的购买美国重点是包括美国矿业领域,以获取可再生能源部门的矿产需求。近年来,美国国会提出了立法,该立法将使在美国矿产投资,增加成本并减少矿产所有权。例如,在第116届国会中,国会议员劳尔·格里哈尔瓦(RaúlGrijalva)提出了一项法案,以替代1872年的一般采矿法(“一般采矿法”),并用租赁系统。3参议员汤姆·乌多尔(Tom Udall)同样提出了立法,以减少采矿索赔所有者的税收利益,并对现有未经批准的采矿索赔施加繁重的特许权使用费。4这些拟议的法律将限制用于矿产开发目的的公共土地的使用,在联邦公共土地上占据了所有权和未经强化的采矿索赔利益,削弱了未经意义的采矿索赔的经济价值,并通过其他监管机构对私人持有和棋盘土地施加了意想不到的负担。这些不是修改一般采矿法的第一次尝试,而是5,它们可能不会是最后一个。

通过连续时间选择均值 - 变化投资组合...
强化学习(RL)是机器学习中的一个活跃子区域,已成功应用于解决复杂的决策问题,例如玩棋盘游戏[31,32]和视频游戏[22] [22],自主驾驶[18,21],以及最近,将大型语言模型和文本生成模型与人类的preference preferfection and-to anclight [18,21]。RL研究主要集中在离散时间和空间中的马尔可夫决策过程(MDP)上。有关MDP的理论和应用的详细说明,请参见[34]。Wang,Zariphopoulou和Zhou [40]是第一个使用受控扩散过程的RL制定和开发RL的熵调查的,探索性控制框架的人,该过程固有地与连续状态空间和可能的连续作用(可能连续的动作(控制)空间)。在此框架中,随机放松控制被用来表示探索,从而捕获了RL核心的“反复试验”概念。随后的工作旨在通过Martingale方法[14、15、16]和政策优化在连续时间内为无模型RL奠定理论基础[44]。在这里,“无模型”是指潜在的动力学是扩散过程,但是它们的系数以及奖励函数是未知的。[14,15,16]的关键见解是,可以从基于连续时间RL的Martingale结构中得出学习目标。这些论文中的理论结果自然会导致一般RL任务的各种“无模型”算法,因为它们直接直接学习最佳策略而无需尝试学习/估计模型参数。这些算法中的许多算法恢复了通常以启发式方式提出的MDP的现有RL算法。然而,对MDP的RL研究占据了中心阶段的算法的融合和遗憾分析仍然缺乏扩散率。To our best knowledge, the only works that carry out a model-free convergence analysis and derive sublinear regrets are [12] for a class of stochastic linear–quadratic (LQ) control problems and [11] for continuous-time mean–variance portfolio selection, both of which apply/apapt the policy gradient algorithms developed in [15] and exploit heavily the special structures of the problems.本文的目的是通过对[16]中引入的(小)Q学习的定量分析以及通常非线性RL问题的相关算法来填补这一空白。(big)Q-学习是离散时间MDP RL的关键方法,但Q功能在连续的时间内崩溃,因为它不再依赖于时间步长无限时间小时的操作。[16]提出了Q功能的概念,Q功能是Q功能在时间离散化方面的第一阶导数。
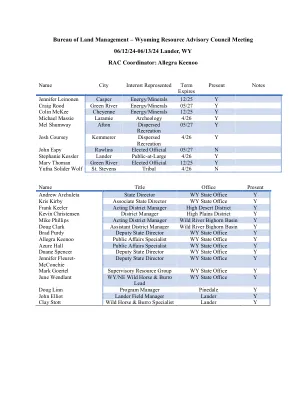
怀俄明州资源咨询委员会会议06/12/24- ...
凯默勒野外办事处(KFO):代理野外经理,布兰登·泰普(Brandon Teppo)KFO涵盖了约140万英亩的联邦表面,而160万个跨越三个县的联邦矿产英亩(Lincoln,Sweetwater和Uinta)。现场办公室跨越了三个大型排水(大盆地/上科罗拉多州/蛇河),其中包含大量的蓝色ribbon溪流。这是加利福尼亚州俄勒冈州,摩门教先驱步道系统的几个截止部分,其中包括几种类型的娱乐机会。kfo管理着各种资源,除了硬岩开采外,还设有该州最大的H2S/CO2加工厂。Pinedale野外办公室(PFO):代理野外经理Perry Wickham PFO管理了大约924,000英亩的公共土地地面和120万英亩的联邦矿产,在四个县西北怀俄明州(Fremont,Lincoln,Sublette和Teton)。我们地区最大的流体矿物开发项目是Pinedale背斜和Jonah天然气场,它们是该国的主要能源。现场办公室是上绿河流域源头的所在地,也是第一个正式指定的大型游戏迁移走廊。在风河和怀俄明州的山脉中包含用于钓鱼,狩猎和娱乐的主要栖息地。Rawlins现场办公室(RFO):Tim Novotny RFO现场经理,在其规划区(碳,奥尔巴尼,Laramie和Sweetwater)县管理四个大县。它包括大约350万英亩的公共土地表面和450万英亩的联邦矿产。RFO处理各种程序。RFO是国家标志中心的所在地,该中心为其他政府机构和合作社制造了各种各样的定制标志。该地区最大的开发项目是不可再生能源。Recreation opportunities include hunting, hiking, water sports, historic trails, but the most popular one is the Continental Trail Rock Springs Field Office (RSFO): Field Manager, Kimberlee Foster RSFO manages more than 3.6 million acres of public land surface and 3.5 million acres of public subsurface minerals among five counties (Fremont, Lincoln, Sublette, Sweetwater, and Uinta) in southwest怀俄明州。娱乐,地质地层和Killpecker Sand Dunes开放区域带来来自全国各地的旅行者参观。世界上最大的钠租赁区占国内苏打水总产量的90%,全球生产的30%位于现场办公室以西35英里处。野外办事处包含大量的土地赠款,作为横登陆铁路的一部分,保留在永久性的棋盘板模式下,是交替的公共和私有土地所有权。