XiaoMi-AI文件搜索系统
World File Search System模型的

1 基于模型的 T700 决策支持工具...
本文介绍了 DSTO 在开发基于模型的方法以诊断和预测由通用电气 T700 发动机驱动的澳大利亚国防军 (ADF) 直升机的气路健康状况方面取得的进展。特别是,介绍了两种新的基于模型的工具:一种用于估计功率保证,一种用于检测异常发动机运行。这些工具的开发是为了利用现代健康和使用监测系统 (HUMS) 记录的发动机参数。正在考虑将此类系统安装到 ADF 直升机上,作为中期升级和采购项目的一部分。第一个工具是基于 T700 模型的功率保证估算器,建议与当前的健康指标测试 (HIT) 检查一起使用,它将 HIT 检查值与给定飞行条件和组件退化场景的可用功率联系起来。第二种工具是基于模型的检测器和模糊逻辑决策器的组合,最初建议用于 HUMS 地面站,以减少手动处理或查询的数据量。DSTO 开发的 MATLAB-Simulink 真双 T700 发动机模型具有对瞬态飞行数据的精确跟踪能力,可以检测给定飞行过程中发动机状况的重大变化。然后,模糊逻辑公式可以自动执行此检测过程,并为未来预测趋势提供飞行结束估计。


DeepFake模型的可插入水印
DeepFake模型滥用构成了主要的安全性。现有的被动和主动的深层检测方法都缺乏义务和鲁棒性。在这项研究中,我们提出了一个可插入式有效的活性模型水印框架以进行深泡泡检测。这种方法促进了识别水印在各种深层生成模型中的嵌入,使当局能够轻松提取它们以进行检测。具体来说,我们的方法利用生成模型解码器中的通用卷积结构。它采用自适应水嵌入定位的结合内核稀疏性,并引入了汇总内核的归一化,以无缝地与固有模型的水印参数无缝。对于水印提取,我们基于深层检测模型共同训练水印提取器,并使用BCH编码有效地识别水印图像。最后,我们将方法应用于八种主要类型的深泡剂模型。实验表明,即使在沉重的损失通道中,我们的方法可成功地检测到平均准确性超过94%的深烟。这种方法独立于发电模型的培训,而不会影响原始模型的性能。此外,我们的模型需要培训数量非常有限的参数,并且对三种主要的自适应攻击具有弹性。可以在https://github.com/guaizao/pluggable-watermarking

大规模基础模型的原则
1。基础模型的数学原理:我开发了一个连贯的作品,该作品建立了理论基础,即覆盖概括,训练动力学和可识别性分析,用于基础模型的一系列自我监督学习(SSL)范式。这些包括自动锻炼[30],重建性[12,22],对比度[4,6],非对抗性[14],预测[11]接近,在图理论框架中,我将它们统一并表征它们。对于诸如变形金刚之类的骨干网络,我提出了有关其特征传播的动态分析[2,19,16,29]。从内在的学习角度来看,我率先提出了LLMS自校正能力的第一个理论解释(对于OpenAI O1中的测试时间推理至关重要),并在ICML'24 ICL研讨会上赢得了最佳纸张奖。

底盘模型的确定和静态分析...
带有内燃机的车辆技术在19世纪末出现。尽管不是很清楚,但电动汽车的首次原型研究与同一时期一致。今天,诸如全球变暖,污染和化石燃料储备的减少等因素加速了对电动汽车技术的过渡。在这种情况下,电动驱动系统的新系统结构与传统车辆结构的不同。在这项研究中,进行了电动汽车的底盘设计。在设计时,将在ANSYS计划的帮助下对电池组进行建模和模拟的部分,以保护对撞击特别敏感的电池和电子组件。为了在法规和标准中指定的滥用测试中取得成功,应正确进行材料选择和设计。在这种情况下,正确的材料是根据研究确定的,并进行了3D模拟,并在模拟环境中进行了崩溃测试。结果,在许多底盘模型中选择了管型底盘,发现7079铝合金适合原材料。根据仿真结果,可以看出设计和所选合金是合适的。
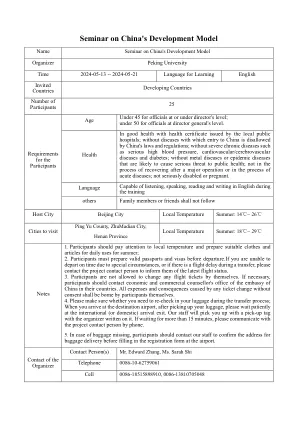
中国发展模型的研讨会
1。参与者应注意当地温度,并准备适当的衣服和文章,以供夏季日常使用; 2。参与者必须在出发前准备有效的护照和签证。如果您由于特殊情况而无法准时出发,或者如果在转会期间有延迟延迟,请与项目联系人联系,以告知他们最新的飞行状态。3。不允许参与者自己更改任何飞行票。必要时,参与者应在其国家联系中国大使馆的经济和商业顾问办公室。未经同意票的任何机票造成的所有费用和后果应由参与者自己承担。4。请确保您是否需要在转移过程中重新检查行李;当您到达目的地机场时,拿起行李后,请耐心等待国际(或国内)到达的出口。我们的员工将带有一个编写的组织者的接送标签来接您。如果等待超过15分钟,请通过电话与项目联系人进行交流。

经济年龄结构模型的验证结果……
为了解决这一局限性,Acemoglu 等人(2020 年)、Gollier(2020 年)和 Favero 等人(2020 年)引入了模型,将人群划分为有限数量的同质“风险组”,并研究引入针对特定群体的政策对经济和流行病学的联合影响。尽管如此,在他们的表述中,没有从一个群体转移到另一个群体的可能性,然后这种方法只有在假设流行病的持续时间与每个群体所包含的年龄范围相比可以忽略不计时,才能考虑到疾病对不同年龄组的不同影响。然而,如果流行病持续数年,这种假设不太可能成立,而对于在人群中成为地方病的疾病,这种假设是不够的 2 。

关于矩阵模型的平面自由能
1 j 2 ! 。 。 。 jk! p 2 j 2 ` ¡ ¡ ¡ kj k ´ 1 q ! pj 2` ¡ ¡ ¡` pk ´ 1 qjk ` 2 q ! p´ x 2 qj 2 。 。 。 p´ xkqjk , (1.8)

测量经济模型的完整性
有更多理由寻找改善预测模型比预测良好的模型的方法。但是什么构成“良好”表现?我们的观点是,答案取决于指定的“功能”(即解释变量)。为了定义想法,假设我们有有关客户是否同意特定贷款的数据。贷款与诸如利率或贷款期限之类的特征不同。这些特征与需求相关的一种模型(“ NPV模型”)可能认为,客户在贷款期间通过预期资本成本的镜头查看贷款。资本的预期成本是可用功能的特定功能。我们可以通过在数据上评估该模型的预测,例如查看有效利率下降时需求是否增加。这些测试使我们能够拒绝错误的模型,但是它们没有告诉我们不同的模型可以做得更好。为了解决这个问题,我们建议将模型的准确性与使用我们具有描述每笔贷款的功能做出的最佳需求预测的准确性。将基准的预测精度与NPV模型的预测准确性进行比较,将告诉我们NPV模型捕获了结果中有多少可预测的信号(给定基线特征)。如果最佳预测比NPV模型的预测要好得多,则可能有另一个模型建立在相同的功能上,从而实质上提高了预测精度。例如,另一个模型可能会假设客户忽略未来的利率,而仅关注初始利率,或者将2.99%的人从2.95%差异。另一方面,如果最佳预测并不比NPV模型的预测好得多,则构建在相同功能上的替代模型在这些数据上可能无法做得更好。新模型可以提供帮助,但必须通过识别当前未测量的新变量来做到这一点。例如,强调框架和说服力的模型将指出将我们的数据集扩展到包括贷款描述中使用的词汇。超出了这个特定示例,任何模型的预测误差通常都可以分解为两个来源:(1)由于我们测量的功能的局限性,即结果>
