XiaoMi-AI文件搜索系统
World File Search System横梁

电动汽车电力横梁的操作概念
• Planned operations and vehicle designs are limited by the power and the capacity of batteries • Takeoff, landing, and reserves consume ~40% of available energy • eVTOL § takeoffs and landings require high power (~8 times horizontal flight), increasing safety risk • Low energy or emergency landing (especially under extreme weather) uses even more energy and a severe threat to safe AAM operations


横向横梁调整的晶格 - 不合稳固式学习剂
强化学习(RL)已成功地应用于各种在线调整任务,通常优于传统优化方法。但是,无模型的RL算法通常需要大量的样式,训练过程通常涉及数百万个相互作用。由于需要重复此耗时的过程来为每个新任务培训基于RL的控制器,因此它在在线调整任务中更广泛地应用构成了重大障碍。在这项工作中,我们通过扩展域随机化来训练一般的晶格 - 反应政策来应对这一挑战。我们专注于线性加速器中的共同任务:通过控制四极杆和校正磁体的强度来调整电子束的横向位置和尺寸。在训练期间,代理与磁铁位置随机分配的环境相互作用,从而增强了训练有素的策略的鲁棒性。初步结果表明,这种方法使政策能够概括和解决不同晶格部分的任务,而无需进行额外的培训,这表明有可能开发可转移RL的代理。这项研究代表了迈向快速RL部署的第一步,并为加速器系统创建了晶格 - 不合稳定的RL控制器。

eurolight®用户手册
2-阶段|一条车道,有2个行人横梁2-相|一条车道,有一个连接点和3个行人横梁2-相|十字路口(平行),有4个行人横梁3-相|连接(旋转)与3个行人横梁3-相|一个带2个连接的车道,带4个行人横梁4-相|十字路口(旋转),有4个行人横梁

引入了
摘要。横梁开关是多阶段互连网络中的基本组件。因此,进行了这项研究是为了研究具有两个多路复用器的横杆开关的性能。使用量子点蜂窝自动机(QCA)技术和QCA Designer软件模拟了所提供的横梁开关,并根据细胞数,占用面积,时钟数和能量消耗进行了研究和优化。使用提供的横梁开关,基线网络的设计是在单元格和占用区域方面是最佳的。此外,研究并模拟了输入状态的数量,以验证基线网络的准确性。所提出的横梁开关使用62个QCA单元,开关的占用区域等于0.06µm 2,其潜伏期等于4个时钟区域,这比其他设计更有效。在本文中,使用呈现的横梁开关,基线网络由1713个单元格设计,占领面积为2.89µm 2。

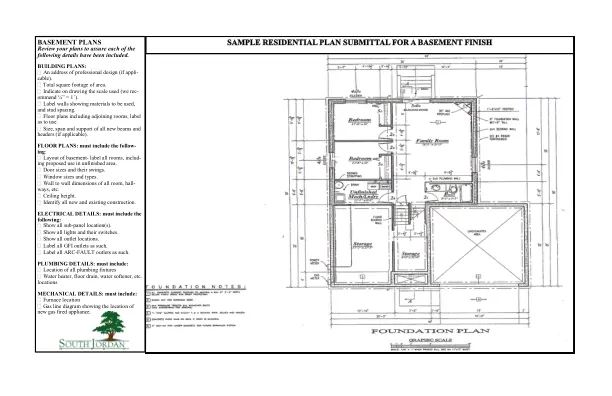
我需要哪些计划才能获得装修、改造或完工许可证?
• 平面图上必须显示每个窗户的位置、大小和类型。请注意,任何需要出口的窗户都必须有 5.7 平方英尺的净开口。• 承重墙、横梁、横梁和其他支撑上方负载的结构构件的位置也必须在平面图上显示,或显示在平面图中包含的单独框架平面图上。工程木材和桁架规格应由制造商/供应商提供。平面图必须显示所有台阶和楼梯。

连接器 - Simpson Strong-Tie
1ARBGAL Arris 导轨支架 ......................。。226 A 角。。。。。。。。。。。。。。。。。。。。。.....................152 A34E/A35E 框架锚 .........................15 0 AB255 结构角支架。......................158 ABR 加固角支架 ........................154 ABR255 结构角支架。......................156 ABW 可调节柱底座带支架 ...............176 AE 加固角支架 .。。。。。。。。。。。。。。。。。。。。。。。154 AKR 木框架加固角支架 ...... div>...160 APB 可调节高架柱底座 ..。 。 。 。 。 。 。 。 . . . . . . . . . . div> 175 ATFN 隐藏式横梁吊架 . . . . . 。 。 。 。 。 。 。 。 < /div> . . . . . 。 。 。 。 。 。 92。。。。。。。。.......... div>175 ATFN 隐藏式横梁吊架 .....。。。。。。。。 < /div>.....。。。。。。92

连接器 - Simpson Strong-Tie
1ARBGAL Arris 导轨支架 ......................。。226 A 角。。。。。。。。。。。。。。。。。。。。。.....................152 A34E/A35E 框架锚 ..........................150 AB255 结构角支架。......................158 ABR 加固角支架 ........................154 ABR255 结构角支架。......................156 ABW 可调节柱底座带支架 ...............176 AE 加固角支架 .。。。。。。。。。。。。。。。。。。。。。。。154 AKR 木框架加固角支架 ...... div>...160 APB 可调节高架柱底座 ..。 。 。 。 。 。 。 。 . . . . . . . . . . div> 175 ATFN 隐藏式横梁吊架 . . . . . 。 。 。 。 。 。 。 。 < /div> . . . . . 。 。 。 。 。 。 92。。。。。。。。.......... div>175 ATFN 隐藏式横梁吊架 .....。。。。。。。。 < /div>.....。。。。。。92
