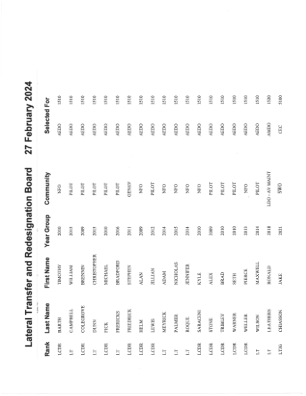
机构名称:
¥ 1.0
强化学习(RL)已成功地应用于各种在线调整任务,通常优于传统优化方法。但是,无模型的RL算法通常需要大量的样式,训练过程通常涉及数百万个相互作用。由于需要重复此耗时的过程来为每个新任务培训基于RL的控制器,因此它在在线调整任务中更广泛地应用构成了重大障碍。在这项工作中,我们通过扩展域随机化来训练一般的晶格 - 反应政策来应对这一挑战。我们专注于线性加速器中的共同任务:通过控制四极杆和校正磁体的强度来调整电子束的横向位置和尺寸。在训练期间,代理与磁铁位置随机分配的环境相互作用,从而增强了训练有素的策略的鲁棒性。初步结果表明,这种方法使政策能够概括和解决不同晶格部分的任务,而无需进行额外的培训,这表明有可能开发可转移RL的代理。这项研究代表了迈向快速RL部署的第一步,并为加速器系统创建了晶格 - 不合稳定的RL控制器。
横向横梁调整的晶格 - 不合稳固式学习剂
主要关键词

相关文件推荐




![横向阅读 [pdf]](/simg/e/e9f15781d2d987ec8433f2a7383873404e0f4ed8.png)