XiaoMi-AI文件搜索系统
World File Search System甲骨文

对称甲骨文问题的量子查询复杂性。
我们研究了量子学习问题的查询复杂性,其中orac会形成统一矩阵的G组。在最简单的情况下,人们希望识别甲骨文,我们发现了t -Query量子算法的最佳成功概率的描述。作为应用程序,我们表明需要查询ω(n)的查询以识别S n中的随机置换。更普遍地,假设H是Oracles G组的固定子组,并从G中均匀地访问了对Oracle采样的访问,我们想了解Horacle属于哪个H caset。我们称此问题coset识别,它概括了许多众所周知的量子算法,包括Bernstein-Vazirani问题,范DAM问题和有限的场外多项式插值。我们为此问题提供了字符理论公式,以实现t- Query算法获得的最佳成功概率。一个应用程序涉及Heisenberg组,并根据N + 1的n + 1查询提供了一个问题,只有1个查询。

在部分信息下进行分类的紧密界限
排序是理论计算机科学中的基本算法问题之一。它具有自然概括,由弗雷德曼(Fredman)于1976年引入,称为部分信息。The input consists of: - a ground set X of size n , - a partial oracle O P (where partial oracle queries for any ( x i , x j ) output whether x i ≺ P x j , for some fixed partial order P ), - a linear oracle O L (where linear oracle queries for any ( x i , x j ) output whether x i < L x j , where the linear order L extends P ) The goal is to recover the linear order使用最少数量的线性甲骨文查询在X上l。在此问题中,我们通过三个指标来测量算法复杂性:o l的线性甲骨文查询数量,部分甲骨文查询的数量和所花费的时间(识别哪个对(x i,x J)部分或线性oracle查询所需的算法指令的数量(识别哪个对(x I,x)执行)。令E(P)表示p的线性扩展数。 任何算法都需要最差的库log 2 e(p)线性甲骨文查询才能恢复x上的线性顺序。 在1984年,Kahn和Saks提出了第一个使用θ(log e(p))线性甲骨文查询(使用O(n 2)部分Oracle查询和指数时间)的算法。 从那时起,一般的问题和受限变体都经过一致研究。 一般问题的最新问题是Cardinal,Fiorini,Joret,Jungers和Munro,他们在Stoc'10设法将线性和部分甲骨文查询分为预处理和查询阶段。 他们可以使用O(n 2)部分Oracle查询和O(n 2。)进行预处理P 5)时间。令E(P)表示p的线性扩展数。任何算法都需要最差的库log 2 e(p)线性甲骨文查询才能恢复x上的线性顺序。在1984年,Kahn和Saks提出了第一个使用θ(log e(p))线性甲骨文查询(使用O(n 2)部分Oracle查询和指数时间)的算法。从那时起,一般的问题和受限变体都经过一致研究。一般问题的最新问题是Cardinal,Fiorini,Joret,Jungers和Munro,他们在Stoc'10设法将线性和部分甲骨文查询分为预处理和查询阶段。他们可以使用O(n 2)部分Oracle查询和O(n 2。5)时间。然后,给定o l,它们在θ(log e(p))线性甲骨文查询和o(n + log e(p))时间的x(log e(p))上的线性顺序 - 这在线性甲骨文查询的数量中是最佳的,但在所花费的时间中却没有。我们提出了第一种使用偏隔序数量甲骨文查询的第一个算法。对于任何常数C≥1,我们的算法可以使用O(n 1+ 1


普通oaep变换的量子后安全
量子计算的快速进展以及Shor's算法[12](如Shor算法)的存在,引发了用后量词加密术代替旧密码学的必要性。朝着这一目标,标准技术研究所(NIST)发起了量子后加密术的竞争。在本文中,我们在NIST竞争的最终主义者之一NTRU提交[6]中解决了一个公开问题。(未修改)量子随机甲骨文模型中(未修改的)最佳不对称加密填充(OAEP)的安全性已被称为[6]中有趣的开放问题。现有的量词后安全证明[14]需要对OAEP变换进行修改。(请参阅下面的详细信息。)随机Oracle模型[1]是一个强大的模型,在该模型中,假设存在包括对手在内的各方都可以访问的真正随机函数,则证明了加密方案的安全性。但在现实世界应用中,随机甲骨文将被加密哈希函数替换,并且该功能的代码是公开的,并且是对手所知道的。在[4]之后,我们使用量子随机甲骨文模型,在该模型中,对手可以在叠加中对随机甲骨文进行查询(即,给定输入的叠加,他可以得到输出值的叠加)。这是必要的,因为基于真实哈希函数的量子对手攻击方案必须能够评估叠加中的功能。因此,如果一个Quantum Security请求,则随机Oracle模型必须反映该功能。

用于从鞍点逃脱的量子算法
查询量子评估Oracle(即零订单Oracle)。与Jin等人的经典最新算法相吻合。使用〜o(log 6(n) /ϵ1。< /div> 75)查询梯度甲骨文(即,第一阶甲骨文),我们的量子算法在log n方面更好地在多项式上,并以1 /ϵ表示其复杂性。 从技术上讲,我们的主要贡献是通过模拟量子波方程来代替梯度下降方法中的经典扰动的想法,这构成了量子查询复杂性的改善,并使用log n n因子逃脱了鞍点。 我们还展示了如何使用Jordan引起的量子梯度计算算法来替换具有相同复杂性的量子评估查询的经典梯度查询。 最后,我们还执行了支持我们理论发现的数值实验。使用〜o(log 6(n) /ϵ1。< /div>75)查询梯度甲骨文(即,第一阶甲骨文),我们的量子算法在log n方面更好地在多项式上,并以1 /ϵ表示其复杂性。从技术上讲,我们的主要贡献是通过模拟量子波方程来代替梯度下降方法中的经典扰动的想法,这构成了量子查询复杂性的改善,并使用log n n因子逃脱了鞍点。我们还展示了如何使用Jordan引起的量子梯度计算算法来替换具有相同复杂性的量子评估查询的经典梯度查询。最后,我们还执行了支持我们理论发现的数值实验。

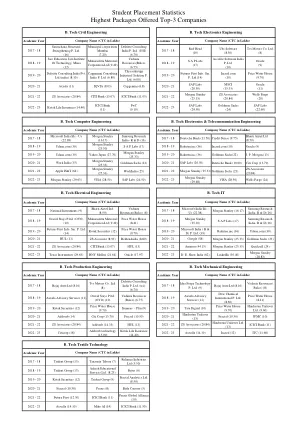
学生就业统计 提供最高薪酬待遇的前三名公司
2022 - 23 德州仪器 (29.63) 纽约梅隆银行 (21.64) 甲骨文 (17.97) 2022 - 23 DE Shaw India (62) 领英 (30.40) 摩根士丹利

与生成对抗网络密度估计的收敛速率
在这项工作中,我们对香草生成对抗网络(GAN)的非反应性特性进行了详尽的研究。与先前已知的结果相比,我们证明了基础密度P ∗与GAN估计值之间的Jensen-Shannon(JS)差异的甲骨文不平等。我们界限的优势在应用于非参数密度估计的应用中变得明确。我们表明,GAN估计值和P ∗之间的JS差异与(log n/ n)2β/(2β + d)的速度快速衰减,其中n是样本大小,β决定了p ∗的平滑度。这种收敛速率与最佳的密度相吻合(至对数因素)与最佳的密度相一致。关键字:生成模型,甲骨文不平等,詹森 - 香农风险,最小值率,非参数密度估计。


McGraw Hill 在迁移到 Oracle Cloud 的过程中利用 Informatica 实现了 ETL 策略的现代化
Lee Rosenfeld,E T L 集成架构师,McGraw-Hill,lee.rosenfeld@mheducation.com Neil Mendelson,甲骨文数据与人工智能战略副总裁,neil.mendelson@oracle.com