XiaoMi-AI文件搜索系统
World File Search System编码

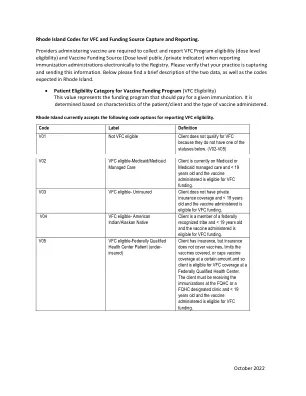
编码 VFC 资金来源
疫苗接种提供者在向登记处以电子方式报告免疫接种情况时,必须收集并报告 VFC 计划资格(剂量水平资格)和疫苗资金来源(剂量水平公共/私人指标)。请确认您的诊所正在捕获并发送此信息。以下是这两个数据的简要说明,以及罗德岛州所需的代码。

计费和编码信息
用于实体肿瘤和血液学恶性肿瘤;与目前的治疗状况无关的血液系统恶性肿瘤与对COVID-19的反应不佳有关(例如,慢性淋巴细胞性白血病,非霍奇金淋巴瘤,多发性骨髓瘤,急性白血病);接受固体器官移植或胰岛移植并接受免疫抑制治疗;接收嵌合抗原受体(CAR)-T细胞或造血干细胞移植(在移植或接受免疫抑制治疗后的2年内);中度或严重的原发性免疫缺陷(例如,常见的可变免疫缺陷疾病,严重的联合免疫缺陷,Digeorge综合征,Wiskott-Aldrich综合征);晚期或未经治疗的HIV感染(患有艾滋病毒和CD4细胞计数<200/mm 3的患者,艾滋病定义疾病的病史,没有免疫重建,或症状HIV的临床表现);用高剂量皮质类固醇(即服用≥2周的≥20毫克泼尼松或每天≥20毫克)的主动治疗B细胞耗尽剂)。†高剂量皮质类固醇(即≥20mg泼尼松或每天施用≥2周)的主动治疗。 ‡专门针对患者在主动治疗下。 §个人历史代码仅在与患者当前的免疫功能低下的健康状况相关时才能选择。 ¶用于实体瘤或血液学恶性肿瘤治疗时。 对于HSCT患者,必须在移植或接受的2年内†高剂量皮质类固醇(即≥20mg泼尼松或每天施用≥2周)的主动治疗。‡专门针对患者在主动治疗下。§个人历史代码仅在与患者当前的免疫功能低下的健康状况相关时才能选择。¶用于实体瘤或血液学恶性肿瘤治疗时。对于HSCT患者,必须在移植或接受#固体移植或胰岛移植患者必须服用免疫抑制疗法。

超导腔双轨编码
设计能够减少和减轻错误的量子硬件对于实用的量子纠错 (QEC) 和有用的量子计算至关重要。为此,我们引入了电路量子电动力学 (QED) 双轨量子比特,其中我们的物理量子比特被编码在两个超导微波腔的单光子子空间 {| 01 ⟩ , | 10 ⟩} 中。主要的光子损失误差可以被检测到并转换成擦除误差,这通常更容易纠正。与线性光学相比,双轨代码的电路 QED 实现提供了独特的功能。每个双轨量子比特仅使用一个额外的 transmon ancilla,我们描述了如何执行一组基于门的通用操作,其中包括状态准备、逻辑读出以及可参数化的单量子比特和双量子比特门。此外,腔体和传输器中的一阶硬件错误可以在所有操作中被检测到并转换为擦除错误,留下数量级较小的背景泡利错误。因此,双轨腔量子比特表现出良好的错误率层次,预计在当今相干时间下的性能远低于相关的 QEC 阈值。
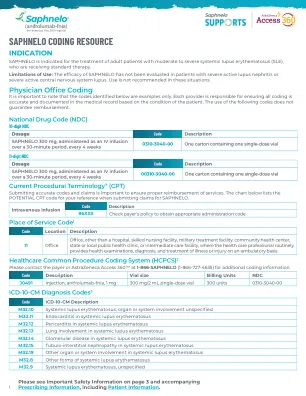
SAPHNELO 编码资源
参考文献:1. 医疗保险和医疗补助服务中心。服务地点代码集。访问于 2021 年 6 月 22 日。https://www.cms.gov/Medicare/Coding/place-of-service-codes/Place_of_Service_Code_Set 2. 医疗保险和医疗补助服务中心 (CMS) 医疗保健。2022 年 3 月 1 日更新。访问于 2022 年 3 月 2 日。https://www.cms.gov/files/document/2021-hcpcs-application-summary-quarter-4- 2021-drugs-and-biologicals.pdf。3. 医疗保险和医疗补助服务中心。2021 年 ICD-10-CM 代码。访问于 2021 年 6 月 22 日。https:// www.cms.gov/medicare/icd-10/2021-icd-10-cm

编码课程计划
无论能量的形式如何,我们都需要谨慎使用多少能量。不可再生能源最终将用完,因此浪费能量会更快地耗尽该来源。可再生能源虽然能够补充能力仍然有限,但其技术仍能产生多少能量。只有18.9%的加拿大能源可再生。如果我们使用该能量的速度比产生的能量更快,则我们被迫使用不可再生能源。在这两种情况下,只要节省能量并仅使用我们需要的尽可能多的能量就变得很重要。我们可以将各种土著社区视为如何使用能量的一个例子。第七代理原则是基于Haudenosaunee的哲学,即我们今天做出的决定应该导致未来的七代可持续一代。Haudenosaunee认识到人类没有拥有世界及其资源,而是他们认为人类必须与环境过平衡的生活。这意味着只使用您需要的东西,并以使世界在未来的几代人中保持和谐和健康的方式生活。行动我们可以节省能源的一种方式就是考虑我们的效率。例如,您可以使用更有效的灯泡,例如用LED灯泡替换活力减少75%的LED灯泡。效率也是编码中非常重要的概念。当程序员代码时,他们并不是唯一从事项目的工作。程序员必须使用最少的代码行来完成任务,这一点很重要,因为这使得更容易找到错误并从他人那里获得帮助。在这项活动中,学生将探讨效率的概念。与此活动相关的四个讲义。每个讲义都有一个使用网格空间进行遍历的地图。每个网格将代表一个能量单位。学生将必须选择最有效的路线,以从开始(绿色)到末端(橙色)。这是一个示例:

编码和报销指南
所有参与者均有责任根据任何保险公司或法律的要求报告收到的所有计划福利。该计划仅在美国和美国领土有效,在法律禁止的地方无效,并在适用的情况下遵守与 AB 级仿制药相关的州限制(例如 MA、CA)。任何一方不得要求报销通过该计划获得的全部或部分福利。该计划旨在为患者服务。只有使用该计划的患者可获得通过该计划提供的资金。该计划不适用于第三方,第三方会减少患者可用的金额或将部分金额用于自己的目的。如果患者的健康计划将 Genentech 计划援助重新定向为患者自付费用,则患者可能会受到其他计划福利结构的约束。Genentech 保留随时撤销、撤销或修改该计划的权利,恕不另行通知。

编程和编码课程
BIOS 6640 R用于数据科学3.0 Cr。限制:以可变术语和年份提供。仅针对以下课程之一给出:BIOS 6640或EPID 6605 R中的统计编程,包括数据管理,订阅,循环,循环,功能,软件包,图形。将涵盖可再现研究的概念和方法,以及计算密集的统计方法。这些方法用于分析数据并提出结果。BIOS 6642 Python编程简介3.0 Cr。限制:以可变术语和年份提供。仅给本课程或BIOS 6682的信用。使用Python进行编程的第一门课程涵盖了诸如变量,数据类型,迭代,控制,输入/输出以及功能以及高级概念(例如面向对象的编程)等基本概念。可以使用与统计相关的示例,作业和项目。BIOS 6644实用数据争吵2.0 Cr。限制:提供的变量条款和年。数据争吵是将数据转化为对科学有用的格式的过程。本课程将为学生提供各种各样的工具,策略和实践,这些工具,策略和实践可以大大减轻痛苦,并浪费时间通常与争吵有关,以及如何利用所有人可用的无数免费资源。BIOS 6660使用R和Bioconductor 3.0 Cr对基因组数据进行分析。PREREQ/COREQ:BIOS 6602或BIOS 6612,或教师同意。限制:以可变术语和年份提供。BIOS 7747生物医学应用机器学习3.0 Cr。本课程为学生提供了使用统计软件R和BioConductor解决现实生活生物学问题的经验。学生将与参与的研究人员和临床医生在基因组学数据的案例研究中进行沟通。PREREQ:生物统计学方法(例如BIOS 6611,BIOS 6612),线性代数(例如数学3191)和Python编程(例如BIOS 6642),或指导老师的许可。限制:以可变术语和年份提供。本课程适用于MS和博士生。无监督和监督的机器学习方法的理论背景及其在生物医学问题解决方案中的应用。除了了解方法论细节外,学生还将学习如何在Python中使用和应用机器学习方法并提高其编码能力。BIOS 7719信息可视化3.0 Cr。与CPBS 7719交叉上市。PREREQ:BIOS 6611和BIOS 6612或教师许可。使用适合开发交互式可视化的语言进行熟练编码。限制:以可变术语和年份提供。信息可视化研究用于分析抽象数据的交互式可视化技术。本课程介绍了在各种生物学和生物医学领域中应用的设计,开发和验证方法。


计费和编码指南
重要的安全信息盒装警告:血液学性恶性血液学恶性肿瘤发生在接受Lyfgenia治疗的患者中。密切监测患者,至少每6个月每6个月,在第6、12个月的整合部位分析并有必要通过整合地点分析,并通过整体分析进行监测。血液学恶性血液学恶性肿瘤发生在接受Lyfgenia治疗的患者中(研究1,A组)。在获得初步产品批准时,使用不同的制造过程和移植程序(研究1,A组)患有早期版本的Lyfgenia治疗的患者开发了急性髓样白血病(AML)。一名患有α-丘脑贫血性状的患者(研究1,C组)已被诊断出患有骨髓增生性综合征(MDS)。与动员,调理和输注叶犬有关的额外造血应激,包括需要再生造血系统的需要,可能会增加血液学恶性肿瘤的风险。与普通人群相比,患有镰状细胞疾病的患者患血液学恶性肿瘤的风险增加。接受Lyfgenia治疗的患者可能患有血液学恶性肿瘤,应进行终身监测。监测血液学恶性肿瘤,至少在接受Lyfgenia治疗后至少15年,每6个月至少每6个月进行全血(具有差异),并在第6、12个月进行整合位点分析,并有保证。如果发生恶性肿瘤,请致电1-833-999-6378与Bluebird Bio联系以进行报告,并获取有关测试样品的说明。