XiaoMi-AI文件搜索系统
World File Search System股票交易

稀有View Systematic Equity ETF 2024 Q4
投资涉及风险,包括可能损失本金。无法保证基金将实现其既定目标。对该基金的投资可能会受到风险的影响,包括市场,利率,税收,流动性,杠杆,非变化,投资限制,运营,授权参与者集中,不保证积极交易市场,积极管理,积极管理,基金股票,股票交易,贸易股票,贸易,溢价/折扣和集中度风险和集中风险的股票和集中股票,以及所有这些可能会构成基金。多元化不能确保利润或防止损失。交易所贸易资金(ETF)贸易像股票一样,会遇到投资风险,并将在市场价值上波动。与共同基金不同,ETF股票不能直接与该基金单独赎回,并且以市场价格在二级市场上买卖,这可能高或低于ETF的净资产价值(NAV)。ETF股票的交易将导致经纪佣金,这将减少回报。ETF股票的交易将导致经纪佣金,这将减少回报。

人工智能在股票市场分析中的作用研究
印度孟买新查尼路 315 号 摘要:人工智能的应用正在扩展到各个领域,包括金融行业,它使参与者能够根据人工智能生成的数据做出灵巧的判断。虽然使用人工智能交易股票并不是什么新鲜事,但它已经取得了长足的进步。基于人工智能的交易策略在市场分析、股票选择、股票价格预测、投资、投资组合构建等领域变得越来越重要。人工智能交易使用计算机算法和软件分析市场数据和趋势。它使用机器学习、自然语言处理、计算机视觉等技术分析数据以寻找模式并预测市场趋势。在人工智能的帮助下,人们正在做出有效的财务决策。为了做出智能资产配置和股票选择的决策,人工智能和机器学习使用技术来识别信号并捕获海量数据集之间的潜在关系。在本章中,我们将研究股票市场中各种人工智能工具和软件的使用如何显著改变股票交易。还需要研究人工智能在股市预测中的风险和挑战。索引词:人工智能、股票价格预测、财务决策。

新冠疫情和疫苗的公布对市场有何影响?
摘要 由于 COVID-19 严重袭击了整个世界,研发出一种可以减轻其影响的疫苗已成为 2020 年最受期待的事件之一。本文研究了 2020 年两大事件对公司股票交易活动的影响:宣布 COVID-19 为全球大流行病以及宣布第一种冠状病毒疫苗。本研究采用事件研究法,使用纳斯达克 100 数据进行。使用普通最小二乘法 (OLS) 和分位数 (Q) 回归来获得股票的预期回报,并评估在每个事件窗口中,所分析的行业对市场的反应是否存在显着差异。获得的实证结果显示,不同行业的股票表现不同。具体而言,只有科技行业的股票对第一个公告做出了积极且显着的反应。然而,第二个事件的情况则相反,因为在受第一个公告打击最严重的行业中,金融市场的信心恢复程度更大。这些结论对于企业、投资者和政府做出更好的决策或采取新的政策具有重要意义。

影响日本经济由盛转衰的因素
变量 观察值 平均值 标准差 最小值 最大值 65 岁及以上人口(占总人口的百分比) 50 17.41457 7.32027 7.66965 29.92456 私营部门国内信贷(占 GDP 的百分比) 50 165.27599 27.39004 119.95455 217.76089 货物和服务出口(占 GDP 的百分比) 50 12.97013 3.17994 8.81647 21.56989 货物和服务进口(占 GDP 的百分比) 50 12.27444 4.15188 6.80943 25.40159 外国直接投资,净流入(占 GDP 的百分比) 50 0.18967 0.29426 -0.05209 1.23960 国内总储蓄 (占 GDP 的百分比) 50 30.38867 5.10204 22.00717 40.94528 通货膨胀率,GDP 平减指数 (年度百分比) 50 1.54181 3.95619 -1.88074 20.81005 国民总支出 (占 GDP 的百分比) 50 99.32781 1.47083 96.39755 103.82710 股票交易,总价值 (占 GDP 的百分比) 48 59.32331 42.26728 11.29986 143.80324 商品贸易 (占 GDP 的百分比) 50 21.72039 5.85834 13.31003 38.62790 失业率,总计(占劳动力总数的百分比)(全国估计值) 50 3.17940 1.10987 1.30000 5.38600
![arxiv:2412.20138v5 [q-fin.tr] 2025年3月2日](/simg/2\24014d0a9140f19331809d215488901e572fc1c8.webp)
arxiv:2412.20138v5 [q-fin.tr] 2025年3月2日
使用由大型语言模型(LLMS)提供动力的代理商的社会在自动化问题中取得了重大进展。在金融中,努力主要集中在单个系统系统上,处理特定任务或独立收集数据的多代理框架。但是,多代理系统复制现实世界贸易公司协作动态的潜力仍未得到探讨。贸易商提出了一个新型的股票交易框架,其灵感来自贸易公司,其中包括LLM功率的代理商,以专门的角色,例如基础分析师,情感分析师,技术分析师和具有不同风险配置文件的交易者。该框架包括评估市场条件的公牛和熊研究人员的代理人,风险管理团队监控敞口以及交易者综合辩论和历史数据中的见解,以做出明智的决定。通过模拟动态的协作交易环境,该框架旨在提高交易绩效。详细的雅典结构和广泛的实验揭示了其优越的基线模型,并有明显改善的回报,夏普比率和最大缩减,突显了多代理LLM框架在财务交易中的潜力。贸易代理可在https://github.com/pioneerfintech上获得。

投资者介绍 - Tyler Technologies | 2024 年 3 月
Tyler Technologies 在本报告中提供的财务指标并非按照公认会计原则 (GAAP) 编制,因此被视为非 GAAP 财务指标。此信息包括非 GAAP 毛利润、非 GAAP 毛利率、非 GAAP 营业收入、非 GAAP 营业利润率、非 GAAP 净收入、非 GAAP 每股摊薄收益、EBITDA、调整后 EBITDA、自由现金流和自由现金流利润率。我们在内部使用这些非 GAAP 财务指标来分析我们的财务结果,并相信它们对投资者有用,作为 GAAP 指标的补充,可用于评估 Tyler 的持续运营绩效,因为它们为比较不同时期的结果提供了额外的见解。Tyler 认为,使用这些非 GAAP 财务指标为投资者提供了一个额外的工具,可用于评估持续的运营结果和趋势,并将我们的财务结果与我们行业中的其他公司进行比较,其中许多公司都采用类似的非 GAAP 财务指标。上述非公认会计准则财务指标不包括股权激励费用、员工股票交易的雇主应缴纳的工资税、因企业合并产生的无形资产摊销相关费用、收购相关费用、租赁重组成本等。年化经常性收入 (ARR) 是通过将本季度的维护和订阅经常性收入年化来计算的。

Tyler Technologies | 2024 年 10 月 24 日
Tyler Technologies 在本报告中提供的财务指标并非按照公认会计原则 (GAAP) 编制,因此被视为非 GAAP 财务指标。此信息包括非 GAAP 毛利润、非 GAAP 毛利率、非 GAAP 营业收入、非 GAAP 营业利润率、非 GAAP 净收入、非 GAAP 每股摊薄收益、EBITDA、调整后 EBITDA、自由现金流和自由现金流利润率。我们在内部使用这些非 GAAP 财务指标来分析我们的财务结果,并相信它们作为 GAAP 指标的补充,对投资者有用,可以评估 Tyler 的持续运营绩效,因为它们为比较不同时期的结果提供了额外的见解。Tyler 认为,使用这些非 GAAP 财务指标为投资者提供了一个额外的工具,可用于评估持续的运营结果和趋势,并将我们的财务结果与我们行业中的其他公司进行比较,其中许多公司都采用类似的非 GAAP 财务指标。上述非公认会计准则财务指标不包括股权激励费用、员工股票交易的雇主应缴纳的工资税、因企业合并产生的无形资产摊销相关费用、收购相关费用、租赁重组成本等。年化经常性收入 (ARR) 是通过将当前季度的订阅和维护经常性收入年化来计算的。
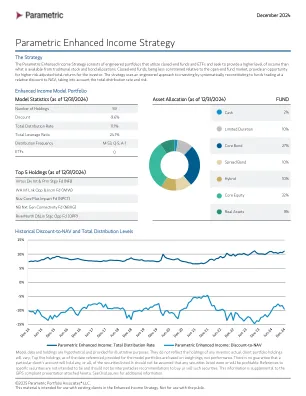
参数增强收入策略
模型方法:增强收入模型(“模型”)于 2008 年 3 月 1 日开始实施,此后一直持续管理。该模型与实时种子资金一起开始实施。该模型以 1,000,000 美元开始实施,并通过股票交易进行历史管理,包括所有公司行动和分配,这些分配应计并记入现金,就像它们是实时账户一样。模型绩效扣除投资管理费(35 个基点)后显示,还反映了估计交易成本的扣除,这些成本来自历史综合月度绩效与模型绩效之间的差异。分配应计并支付给现金,现金在每次定期模型重新平衡期间进行再投资。模型绩效以时间加权为基础。模型定期重新平衡,作为各自策略的唯一模型目标,按比例反映客户账户内进行的所有相应交易。模型交易由 Parametric 的数据供应商在收盘时定价。模型绩效是通过每日生产流程计算得出的,包括证券价格回报、分配应计/支付和公司行动。自模型成立以来,模型管理理念或持续生产没有发生任何重大变化,模型的实施与投资于策略的客户账户管理高度一致。如有要求,可提供其他模型方法。

ESPP:资格和取消资格的性格(...
投资涉及风险,包括损失风险。保真不提供法律或税收建议。本文的信息本质上是一般性和教育意义的,不应被视为法律或税收建议。税法法规很复杂,可能会发生变化,这可能会对投资结果产生重大影响。保真度无法保证此处的信息是准确,完整或及时的。保真不对此类信息或结果获得的结果不保证,并违反了您对您使用的任何责任或依赖此类信息所征收的任何税收立场所产生的责任。有关您的特定情况,请咨询律师或税务专业人士。与Mystockoptions.com安排的内容提供的部分是在线股票计划教育和工具的独立来源。未经Mystockplan.com,Inc。或Fidelity Investments的明确许可,可能不会复制内容。佣金和费用将适用于股票交易。为您的方便起见,包括指向第三方材料的链接。内容所有者并不是忠实的,并且对其提供的信息和服务完全负责。保真不承担因使用此类信息或服务而产生的任何责任。Fidelity Stock Plan Services,LLC,除了您公司或其服务提供商直接提供给计划的任何服务外,还为您公司的股权补偿计划提供记录保存和/或行政服务。保真度投资和金字塔设计徽标是FMR LLC的注册服务标记。Fidelity Brokerage Services LLC,纽约证券交易所成员,SIPC©2023 FMR LLC。保留所有权利。951423.3.0 ESPP指南– 0123

通过论证构建更可解释的人工智能
引言大数据时代的到来为机器学习带来了巨大的成功。数据的丰富和各种机器学习技术的发展共同导致了新的人工智能模型和应用的爆炸式增长。然而,机器学习的大部分仍然是不透明的“黑匣子”。人工智能系统的有效性,特别是在疾病诊断、股票交易和自动驾驶汽车等关键应用中,将受到机器无法向人类解释其决策和结论的限制。因此,构建更可解释的人工智能非常重要,这样人类才能理解、信任和有效地管理新兴的人工智能系统(Gunning 2016)。整合(Gunning 2016)和(Biran and Cotton 2017)中提出的分类法,现有的可解释人工智能(XAI)研究可分为三大类方法:(1)基于特征的解释,(2)模型近似和(3)可解释模型。对于基于特征的解释,通常会给出一个不可解释的复杂模型及其预测。这种方法侧重于通过提取和识别对预测结果有显著影响的特征来为预测生成理由。Martens 等人(2008)通过提取可以基于一小部分特征产生与 SVM 类似结果的规则来解释 SVM 分类器的结果。Landecker 等人(2013)通过研究不同组件对分类结果的重要程度来解释分层网络的分类结果。Hendricks 等人(2016)使用 LSTM 基于突出的图像特征和类别判别特征为 CNN 的图像分类结果生成解释。