XiaoMi-AI文件搜索系统
World File Search System视觉场景

自然视觉场景的神经网络重建...
神经编码是系统神经科学中的核心问题之一,用于了解大脑如何从环境中处理刺激,此外,它也是设计脑与机器界面算法的基石,在该算法中,解码传入的刺激是高度要求的,以便更好地性能进行物理设备的性能。传统研究人员将功能性磁共振成像(fMRI)数据作为解码视觉场景感兴趣的神经信号。但是,我们的视觉感知在称为神经尖峰的事件方面以毫秒的快速时间尺度运行。几乎没有使用尖峰进行解码的研究。在这里,我们通过开发一个基于深层神经网络的新型解码框架(名为Spike-图像解码器(SID))来重建自然视觉场景(包括静态图像和动态视频),从实验记录的视网膜神经节细胞的尖峰中重建了新的解码框架。SID是一个端到端解码器,其一端为神经尖峰,另一端为图像,可以直接训练它,以使视觉场景以高度准确的方式从尖峰重建。与现有的fMRI解码模型相比,我们的SID在视觉刺激的重建方面也表现出色。此外,借助Spike编码器,我们证明SID可以通过使用MNIST,CIFAR10和CIFAR100的图像数据集将其推广到任意视觉场景。此外,有了预先训练的SID,可以解码任何动态视频,以实现通过Spikes对视觉场景进行实时编码和解码。©2020 Elsevier Ltd.保留所有权利。总的来说,我们的结果为人工视觉系统(例如基于事件的视觉摄像机和视觉神经图)提供了有关神经形态计算的新启示。

利用深度神经网络从神经脉冲重建自然视觉场景
神经编码是系统神经科学中理解大脑如何处理来自环境的刺激的核心问题之一,此外,它也是设计脑机接口算法的基石,其中解码传入的刺激对于提高物理设备的性能至关重要。传统上,研究人员专注于将功能性磁共振成像 (fMRI) 数据作为解码视觉场景的神经信号。然而,我们的视觉感知在称为神经尖峰的事件中以毫秒为单位的快速时间尺度运行。很少有关于使用尖峰进行解码的研究。在这里,我们通过开发一种基于深度神经网络的新型解码框架来实现这一目标,称为尖峰图像解码器 (SID),用于从实验记录的视网膜神经节细胞群尖峰重建自然视觉场景,包括静态图像和动态视频。SID 是一个端到端解码器,一端是神经尖峰,另一端是图像,可以直接对其进行训练,以便以高精度的方式从尖峰重建视觉场景。与现有的 fMRI 解码模型相比,我们的 SID 在视觉刺激重建方面也表现出色。此外,借助脉冲编码器,我们展示了 SID 可以通过使用 MNIST、CIFAR10 和 CIFAR100 的图像数据集推广到任意视觉场景。此外,使用预先训练的 SID,可以解码任何动态视频,实现脉冲对视觉场景的实时编码和解码。总之,我们的结果为人工视觉系统的神经形态计算提供了新的启示,例如基于事件的视觉相机和视觉神经假体。

视觉场景复杂性对空间注意神经特征的影响
空间选择性注意极大地影响了我们对复杂视觉场景的处理,但大脑选择相关物体而抑制不相关物体的方式仍不清楚。使用非侵入性脑电图 (EEG) 发现了这些过程的证据。然而,很少有研究描述在注意动态刺激期间这些测量值的特征,而且对于这些测量值如何随着场景复杂性的增加而变化知之甚少。在这里,我们比较了三个视觉选择性注意任务中 EEG N1 和 alpha 功率(8-14 Hz 之间的振荡)的注意力调节。这些任务在呈现的不相关刺激数量上有所不同,但都需要持续注意侧化刺激的方向轨迹。在几乎没有不相关刺激的场景中,自上而下的空间注意控制与顶叶-枕叶通道中 N1 和 alpha 功率的强烈调节有关。然而,在两个半视野中都有许多不相关刺激的场景中,自上而下的控制不再表现为对 alpha 功率的强烈调制,并且 N1 振幅总体上较弱。这些结果表明,随着场景变得更加复杂,需要在两个半视野中进行抑制,自上而下控制的神经特征会减弱,这可能反映了 EEG 在表示这种抑制方面存在一些局限性。

教练手册 - FlightAcad - 法航
本指导手册适用于法航 L3 A350 模拟器,仅提供可用模拟器功能(包括故障和视觉场景)的概述。本指导手册不会因小更新而修改,但会影响 IOS 手册的模拟器重大更新将予以配合。确保您已获得本文档的最新副本,可通过联系客户支持或模拟器工程部门获取可用故障和视觉场景的最新概述。可通过指导站的机场选择页面引用可用的 JAR-STD 认证视觉场景。

构建具有互动感知的负担能力图
机器人需要了解他们的环境才能执行其任务。如果可以在封闭环境中预先编程的视觉场景分析过程,则在开放环境中运行的机器人将从与环境的互动中学习它的能力。此功能进一步为获得提供的图表开辟了道路,在该图中,机器人的动作能力结构了其视觉场景的理解。我们提出了一种方法,通过依靠互动感知方法和在线分类来建立此类负担图地图,并为配备两个具有7个自由度的武器的真正机器人进行在线分类。我们的系统是模块化的,可以从不同技能中学习地图。在提议的负担形式化中,行动和效果与视觉特征有关,而不是对象,因此我们的方法不需要事先定义对象概念。我们已经在三个动作原语和真实的PR2机器人上测试了该方法。
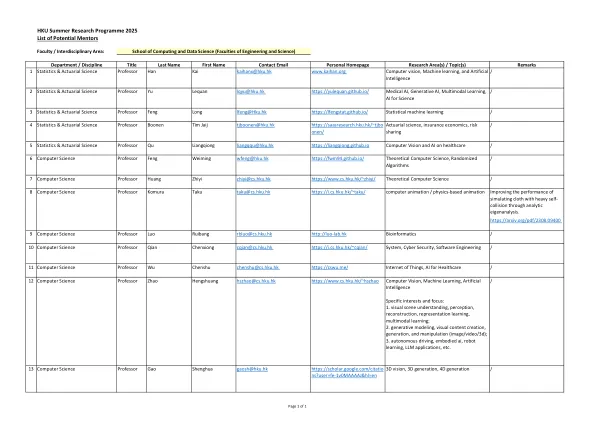
HKU夏季研究计划2025潜在导师列表
特定的兴趣和重点:1。视觉场景理解,感知,重建,表示学习,多模式学习; 2。生成建模,视觉内容创建,生成和操纵(图像/视频/3D); 3。自动驾驶,体现AI,机器人学习,LLM应用程序等。
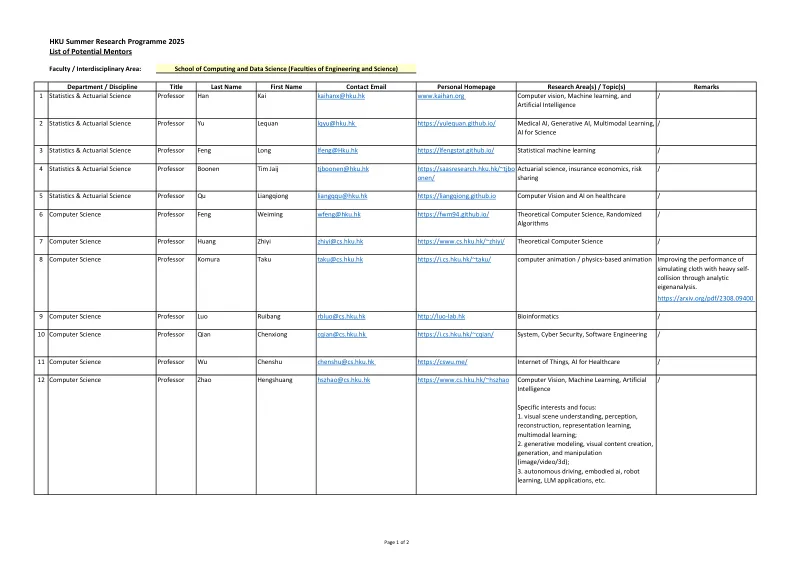
HKU夏季研究计划2025潜在导师列表
特定的兴趣和重点:1。视觉场景理解,感知,重建,表示学习,多模式学习; 2。生成建模,视觉内容创建,生成和操纵(图像/视频/3D); 3。自动驾驶,体现AI,机器人学习,LLM应用程序等。

在视觉场景显示中突出显示项目的策略,以支持身体有障碍的人进行增强和替代的交流访问
视觉场景显示 (VSD) 是一项较新的创新,它为辅助交流显示提供了一种新范例 [1,2]。传统上,AAC 选择的项目孤立地呈现在纯色背景上,没有上下文,通常按分类类别排列在网格内(例如,不同动物的网格)[6]。与传统的基于网格的显示相比,VSD 在任何时候提供的交流选项数量可能更有限。这种限制是因为 VSD 仅限于场景中自然出现的项目选择。然而,VSD 会在自然发生的环境中(例如,在照片中)呈现符号,并根据物体在场景中的自然位置使用直观的导航系统 [2,7]。此外,即时 (JIT) 编程旨在支持个人的即时交流访问和语言学习,以增强交流成功率 [8]。积极的一面是,VSD 可以即时生成,这意味着它们可以通过嵌入式数码相机轻松捕捉,然后将场景元素指定为交流热点 [9]。简单的过程有助于减少程序员为使用 VSD 的个人构建显示器的需求,从而可能带来更大的参与度 [10]。因此,这些优势意味着 VSD 为处于早期符号发展阶段的儿童 [11] 或患有失语症等疾病的成年人 [12] 提供了许多优于传统网格显示器的优势。因此,重要的是要考虑如何设计 VSD 以支持那些有严重身体障碍的人的通信访问。

使用夸张的视觉层次结构映射改善视觉识别
视觉场景是自然组织的,在层次结构中,粗糙的语义递归由几个细节组成。探索这种视觉层次结构对于认识视觉元素的复杂关系至关重要,从而导致了全面的场景理解。在本文中,我们提出了一个视觉层次结构映射器(HI-MAPPER),这是一种增强对预训练的深神经网络(DNNS)结构化理解的新方法。hi-mapper通过1)通过概率密度的封装来调查视觉场景的层次结构组织; 2)学习双曲线空间中的分层关系,并具有新颖的分层对比损失。预定义的层次树通过层次结构分解和编码过程递归地与预训练的DNN的视觉特征相互作用,从而有效地识别了视觉层次结构并增强了对整个场景的识别。广泛的实验表明,Hi-Mapper显着增强了DNN的表示能力,从而改善了各种任务的性能,包括图像分类和密集的预测任务。代码可在https://github.com/kwonjunn01/hi-mapper上找到。

视觉谜语:大型视力和语言模型的常识性和世界知识挑战
想象一下,观察某人挠自己的手臂;要了解为什么,需要其他上下文。但是,在附近发现蚊子会立即为该人的不适感提供一个可能的解释,从而减轻了需要进一步信息的需求。此示例说明了微妙的视觉提示如何挑战我们的认知能力,并证明了解释视觉场景的复杂性。为了研究这些技能,我们提供了视觉谜语,这是一种基准测试,旨在测试需要常识和世界知识的视觉谜语的视觉和语言模型。基准包括400个视觉谜语,每个谜语都具有由各种文本到图像模型,问题,地面真相答案,文本提示和归因创建的独特图像。人类评估表明,现有模型显着落后于人类绩效,即精度为82%,Gemini-Pro-1.5以40%的精度领先。我们的基准包括自动评估任务,以使评估可扩展。这些发现强调了视觉谜语作为增强视觉和语言模型解释复杂视觉场景功能的宝贵资源的潜力。