XiaoMi-AI文件搜索系统
World File Search System训练量

带量采购政策对使用的影响...
摘要 目的 2018年12月,中国启动国家带量采购(NVBP),与药品生产企业进行药品价格谈判。吉非替尼是25种试点药物之一,用于治疗非小细胞肺癌。肺癌是中国最常见的癌症类型,像吉非替尼这样的靶向药物已被证明可以为患者带来临床益处。本研究旨在探讨NVBP政策对抗癌药物使用和支出的影响。方法 以吉非替尼和替代药物(埃克替尼和厄洛替尼)为研究对象。使用中国医院药品审计数据库的9454家医院的季度数据进行分析。以采购量和支出为变量进行描述性分析。采用间断时间序列(ITS)分析进一步分析NVBP政策对研究药品的影响。结果 NVBP政策实施前(2018Q2—2019Q1)与实施后(2019Q2—2020Q1)的12个月期间,药品总采购量从448万DDD上升至702万DDD,增幅为56.66%,吉非替尼和替代药品的采购量分别增长了100.61%和14.88%。NVBP政策实施后,替代药品采购量减少了72 051 DDD(P值=0.044),趋势变化量减少了56 738 DDD(P值<0.01)。总体费用减少14.7%,其中吉非替尼费用减少38.47%,替代药品费用增加10.70%。ITS分析显示,总药品和吉非替尼费用的水平和趋势变化差异均具有统计学意义。结论 本研究提供的证据表明,NVBP政策的实施与第一代抗EGFR肺癌药物费用的减少有关。该政策有效地控制了第一代抗EGFR肺癌药物费用的增长。

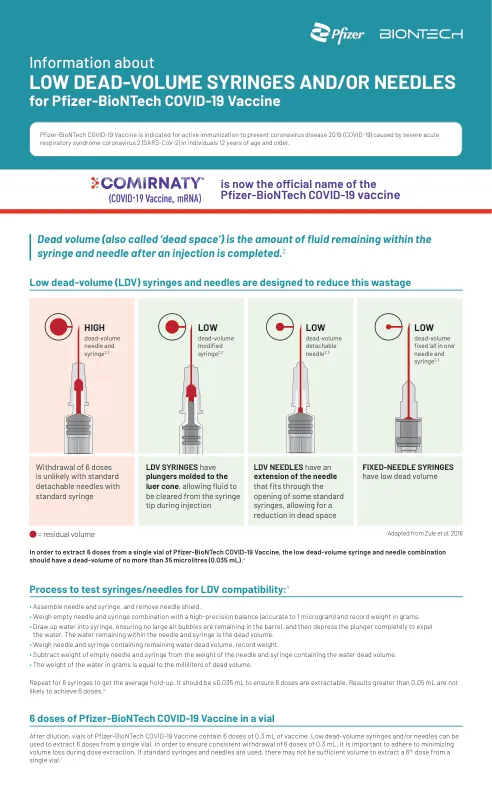
低死量注射器和/或针头
Pfizer-Biontech Covid-19疫苗,优先使用低死量注射器和/或针。•每个剂量必须含有0.3 mL的疫苗。•如果在小瓶中剩余的疫苗量不能提供0.3毫升的全剂量,请丢弃小瓶和任何多余的体积。•稀释后6小时立即进行管理。•低死量注射器和/或针可用于从单个小瓶中提取6剂。以确保一致

儿童达到目标药物暴露量
儿童的成熟生理反映在更复杂的给药方案中,以在儿科一生中达到目标暴露[1]。对于多种药物,如果满足以下要求,治疗药物监测(TDM)可能支持药物治疗的优化:(1)治疗范围较窄,(2)变异性大,(3)已知的浓度-效应关系,(4)没有可测量的效果。模型信息精准给药(MIPD)是TDM的下一步,最近受到了更多的关注,因为它可以作为帮助个体化给药的有力工具[2]。特别是,儿科药物治疗可能会受益于这种临床决策支持(CDS)的发展,并超越复杂的给药方案,实现更加个性化的给药。在本期期刊中,Hartman 等人[ 3 ] 评估根据基于模型的剂量指南对危重新生儿和儿童给药的万古霉素、庆大霉素和妥布霉素在 TDM 期间的目标达成情况。尽管如此,作者仍然观察到这三种药物的亚治疗浓度和超治疗浓度的比例很大。我们非常感谢他们在实施更简化的剂量指南后评估目标达成情况的主动性


再次低软量定理
摘要表明,与Lebiedow-Icz等人的主张相反。(Phys Rev D 105(1):014022,2022)在适当的物理变量中配制的较低定理(Phys Rev 110(4):974–977,1958)用于软光子发射不需要任何模拟。我们还拒绝Lebiedowicz等人的批评。(2022)论文(Phys。Burnett和Kroll。修订版Lett。 20:86–88,1968; Nucl Phys B 307:705–720,1988年的Lipatov。 同时,我们确定了Burnett and Kroll(1968)中的一些不准确性,以呈现软孔定理的旋转一半属性。 我们还指出了经典教科书中低定理的缺点(Berestetskii等人 量子电动力学。 Pergamon Press,牛津,1982年; Lifshitz和Pitaevsky在相对论量子理论中,第2部分,Fizmatlit,2002)。Lett。20:86–88,1968; Nucl Phys B 307:705–720,1988年的Lipatov。同时,我们确定了Burnett and Kroll(1968)中的一些不准确性,以呈现软孔定理的旋转一半属性。我们还指出了经典教科书中低定理的缺点(Berestetskii等人量子电动力学。Pergamon Press,牛津,1982年; Lifshitz和Pitaevsky在相对论量子理论中,第2部分,Fizmatlit,2002)。

量热法 - Indico Global
更高的能量“容易” - 3个TEV研究(CLIC),但许多TEV具有挑战性:•功率与亮度成比例•考虑到50km•较高能量意味着较小的光束和越来越重要的横梁效应


大规模人工智能训练
大规模 AI 训练需要尖端技术来最大限度地发挥 GPU 的并行计算能力,以处理数十亿甚至数万亿个 AI 模型参数,这些参数需要使用呈指数级增长的海量数据集进行训练。利用 NVIDIA 的 HGX™ H100 SXM 8-GPU/4-GPU 和最快的 NVLink™ 和 NVSwitch™ GPU-GPU 互连(带宽高达 900GB/s),以及最快的 1:1 网络到每个 GPU 进行节点集群,这些系统经过优化,可在最短的时间内从头开始训练大型语言模型。通过全闪存 NVMe 完成堆栈以实现更快的 AI 数据管道,我们提供带有液体冷却选项的完全集成机架,以确保快速部署和流畅的 AI 训练体验。
