XiaoMi-AI文件搜索系统
World File Search System语时

大语模型的道德机器实验
随着大型语言模型(LLM)已变得更加深入地整合到各个部门中,因此了解它们如何做出道德判断已经变得至关重要,尤其是在自动驾驶领域。本研究使用道德机器框架来研究包括GPT-3.5,GPT-4,Palm 2和Llama 2在内的突出LLM的道德决策趋势,以将其反应与人类偏好进行比较。虽然LLMS和人类的偏好,例如将人类优先于宠物优先考虑,而偏爱挽救更多的生命是广泛的,但Palm 2和Llama 2,尤其是证据,尤其是证据明显的偏差。此外,尽管LLM和人类偏好之间存在定性相似之处,但与人类的温和倾向相比,LLMS可能倾向于更加毫不妥协的决策。这些见解阐明了LLM的道德框架及其对自主驾驶的潜在影响。

大语模型中的心理理论
摘要及其最近的发展,大型语言模型(LLM)表现出一定程度的心理理论(TOM),这是一种与我们的意识思维有关的复杂认知能力,使我们能够推断他人的信念和观点。虽然人类的TOM能力被认为是源自广泛相互联系的脑网络的神经活性,包括背侧内侧前额叶皮层(DMPFC)神经元的神经活性,但LLM与TOM相似的LLM能力的确切过程仍然很广。在这项研究中,我们从DMPFC神经元中依靠人类TOM的DMPFC神经元中汲取了灵感,并采用了类似的方法来检查LLMS是否表现出可比的特征。令人惊讶的是,我们的分析揭示了两者之间的显着相似之处,因为LLM中隐藏的嵌入(人造神经元)开始对真实或虚假的belief试验表现出很大的响应能力,这表明它们代表他人的观点的能力。这些人工嵌入响应与LLMS在TOM任务中的性能密切相关,该功能取决于模型的大小。此外,可以使用整个嵌入来准确地解码对方的信念,这表明在人群水平上存在嵌入的TOM能力。一起,我们的发现揭示了LLMS嵌入的新兴特性,该特性对TOM特征的响应修改了其活动,提供了人工模型与人脑中神经元之间平行的初步证据。

llava-re:具有多模式大语模型
多模式生成型AI通常涉及在另一种模态中给定输入给定的图像或文本响应。图像文本相关性的评估对于衡量响应质量或对候选响应的排名至关重要。在二元相关性评估中,即,“相关”与“不相关”是一个基本问题。但是,考虑到文本具有多种格式,相关性的定义在不同的情况下有所不同,这是一项具有挑战性的任务。我们发现,多模式的大型语言模型(MLLM)是构建此类评估者的理想选择,因为它们可以灵活地处理复杂的文本格式并掌握适当的任务信息。在本文中,我们介绍了Llava-re,这是与MLLM进行二进制图像文本相关性评估的首次尝试。它遵循LLAVA体系结构,并采用详细的任务指令和多模式IN上下文样本。此外,我们提出了一个新型的二进制相关数据集,该数据集涵盖了各种任务。实验结果验证了我们框架的有效性。

大语模型的潜力在产生多重...
在本研究中使用了一种定制的Chatgpt,称为GPTS [15] [15],结果模型被称为“ Physio Exam gpt”。自定义过程涉及两个主要组成部分:首先,一个包括340个MCQ的知识库以及相应的正确答案,解释和链接的主题,这些主题是从第57届日本和第58届日本国家物理治疗师的国家许可检查中得出的。作者开发了这些解释和相关主题,如附录部分(补充1)所示。第二,量身定制的提示配置旨在使用户能够输入相关主题,从而使GPT可以根据知识库中嵌入的信息生成MCQ。提示设计的细节在补充2中列出;如上所述,自定义过程有意限于嵌入“知识”(MCQ)并配置“提示”,而没有其他微调或模型调整。生成的问题仅依赖于自定义GPT框架的标准功能。

VK0192 数据手册
时序基准发生器是一个 8 级递增计数器 , 可以精确的产生时基。看门狗 ( WDT )是由一个 时基发生器和一个 2 级计数器组成,它可以在主控制器 或其它子系统处于异常状态时产生中断。 WDT 计数溢出时产生一个溢出标 志,此标志可以通过命令输出到 /IRQ 脚 ( 开漏输出 ) 。时序基准发生器和 WDT 时钟的来源。时基和看门狗共用 1 个时钟源,可配置 8 种频率: f WDT = f sys/2 n ( n=0~7 )
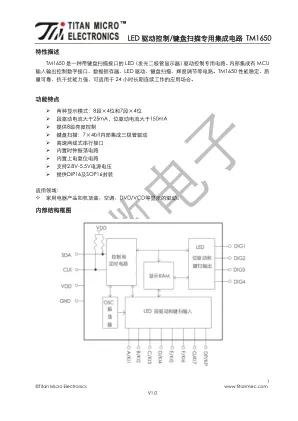
LED 驱动控制/键盘扫描专用集成电路TM1650
接口和TM1650 通信,在输入数据时当SCL 是高电平时,SDA 上的信号必须保持不变;只有SCL 上的 时钟信号为低电平时,SDA 上的信号才能改变。数据输入的开始条件是SCL 为高电平时,SDA 由高变




当您无法入睡时该怎么办
无论原因是什么,无论多么久,都有一个问题和策略可以提供帮助。该传单首先总结了可以帮助改善睡眠的主要策略。传单的主要部分描述了什么是睡眠以及如何控制睡眠。我们解释了失眠是如何发展的,然后提供实用的建议并描述改善睡眠的技术。有目的地有目的地详细说明传单,以清楚地解释策略以及它们可以改善睡眠的原因。有些人可能想从头到尾阅读整个传单,另一些人可能想使用内容页面找到相关部分。在大多数部分的末尾都有“接收回家消息”,这些消息总结了要点。此传单中描述的技术可能需要时间并需要毅力 - 通常没有“快速修复”。治疗失眠症需要精力和承诺,但目的是使您的睡眠方式长期改善,使您白天感觉更好。